This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the realm of big dataprocessing, PySpark has emerged as a formidable force, offering a perfect blend of capabilities of Python programming language and Apache Spark. From loading and transforming data to aggregating, filtering, and handling missing values, this PySpark cheat sheet covers it all. Let’s get started!
transformers) became standardized, ML engineers started to show a growing appetite to iterate on datasets. While such dataset iterations can yield significant gains, we observed that only a handful of such experiments were conducted and productionized in the last six months. As model architecture building blocks (e.g.
Batch dataprocessing — historically known as ETL — is extremely challenging. In this post, we’ll explore how applying the functional programming paradigm to data engineering can bring a lot of clarity to the process. Late arriving facts Late arriving facts can be problematic with a strict immutable data policy.
Here’s What You Need to Know About PySpark This blog will take you through the basics of PySpark, the PySpark architecture, and a few popular PySpark libraries , among other things. Finally, you'll find a list of PySpark projects to help you gain hands-on experience and land an ideal job in Data Science or Big Data.
With its intuitive data structures and vast array of functions, Pandas empowers data scientists to efficiently clean, transform, and explore datasets, making it an indispensable tool in their toolkit. Handling missing values: Missing values are a common occurrence in datasets. Is R or Python better for data wrangling?
This belief has led us to developing Privacy Aware Infrastructure (PAI) , which offers efficient and reliable first-class privacy constructs embedded in Meta infrastructure to address different privacy requirements, such as purpose limitation , which restricts the purposes for which data can be processed and used.
Whether you are working on a personal project, learning the concepts, or working with datasets for your company, the primary focus is a data acquisition and data understanding. Your data should possess the maximum available information to perform meaningful analysis. What is a Data Science Dataset?
To remove this bottleneck, we built AvroTensorDataset , a TensorFlow dataset for reading, parsing, and processing Avro data. AvroTensorDataset speeds up data preprocessing by multiple orders of magnitude, enabling us to keep site content as fresh as possible for our members. avro", "part-00001.avro"], Default is zero.
With the global data volume projected to surge from 120 zettabytes in 2023 to 181 zettabytes by 2025, PySpark's popularity is soaring as it is an essential tool for efficient large scale dataprocessing and analyzing vast datasets. Resilient Distributed Datasets (RDDs) are the fundamental data structure in Apache Spark.
AWS DevOps offers an innovative and versatile set of services and tools that allow you to manage, scale, and optimize big data projects. With AWS DevOps, data scientists and engineers can access a vast range of resources to help them build and deploy complex dataprocessing pipelines, machine learning models, and more.
I found the blog to be a fresh take on the skill in demand by layoff datasets. DeepSeek’s smallpond Takes on Big Data. DeepSeek continues to impact the Data and AI landscape with its recent open-source tools, such as Fire-Flyer File System (3FS) and smallpond. link] Mehdio: DuckDB goes distributed?
Data professionals who work with raw data, like data engineers, data analysts, machine learning scientists , and machine learning engineers , also play a crucial role in any data science project. This project will help analyze user data for actionable insights.
The Race For Data Quality In A Medallion Architecture The Medallion architecture pattern is gaining traction among data teams. It is a layered approach to managing and transforming data. By systematically moving data through these layers, the Medallion architecture enhances the data structure in a data lakehouse environment.
Liang Mou; Staff Software Engineer, Logging Platform | Elizabeth (Vi) Nguyen; Software Engineer I, Logging Platform | In today’s data-driven world, businesses need to process and analyze data in real-time to make informed decisions. What is Change Data Capture? Why is CDC Important? or its affiliates.
Data consistency, feature reliability, processing scalability, and end-to-end observability are key drivers to ensuring business as usual (zero disruptions) and a cohesive customer experience. With our new dataprocessing framework, we were able to observe a multitude of benefits, including 99.9%
Traditional databases may need help to provide the necessary performance when dealing with large datasets and complex queries. Data warehousing tools are designed to handle such scenarios efficiently, enabling faster query performance and analysis, even on massive datasets. Not designed for transactional processing.
It requires a state-of-the-art system that can track and process these impressions while maintaining a detailed history of each profiles exposure. This nuanced integration of data and technology empowers us to offer bespoke content recommendations.
Data transformation helps make sense of the chaos, acting as the bridge between unprocessed data and actionable intelligence. You might even think of effective data transformation like a powerful magnet that draws the needle from the stack, leaving the hay behind.
link] AWS: An introduction to preparing your own dataset for LLM training Everything in AI eventually comes down to the quality and completeness of your internal data. link] Apache Arrow: Data Wants to Be Free: Fast Data Exchange with Apache Arrow Data exchange is critical when discussing AI and the need for data quality.
It requires a skillful blend of data engineering expertise and the strategic use of tools designed to streamline this process. That’s where data pipeline tools come in. This blog is all about that—specifically, the top 10 data pipeline tools that data engineers worldwide rely on.
This blog offers an Agentic AI learning path, explaining the core components behind AI Agents. If you’ve ever wondered how these intelligent systems work or wanted to build one, this blog is your starting point. Read more about AI agents in our latest blog: AI Agents: The New Human-Like Heroes of AI.
Master PySpark RDD operations and concepts with our concise and comprehensive PySpark cheat sheet, empowering you to unlock the potential of distributed dataprocessing. Resilient Distributed Datasets (RDDs) are a fundamental abstraction in PySpark, designed to handle distributed dataprocessing tasks.
Do ETL and data integration activities seem complex to you? Read this blog to understand everything about AWS Glue that makes it one of the most popular data integration solutions in the industry. Did you know the global big data market will likely reach $268.4 Businesses are leveraging big data now more than ever.
Building data pipelines is a core skill for data engineers and data scientists as it helps them transform raw data into actionable insights. In this blog, you’ll build a complete ETL pipeline in Python to perform data extraction from the Spotify API, followed by data manipulation and transformation for analysis.
You can share Iceberg table data with your clients who can then access the data using third party engines like Amazon Athena , Trino, Databricks, or Snowflake that support Iceberg REST catalog. The solution covered by this blog describes how Cloudera shares data with an Amazon Athena notebook.
Why Future-Proofing Your Data Pipelines Matters Data has become the backbone of decision-making in businesses across the globe. The ability to harness and analyze data effectively can make or break a company’s competitive edge. In this blog post, we’ll explore key strategies for future-proofing your data pipelines.
Tired of relentlessly searching for the most effective and powerful data warehousing solutions on the internet? This blog is your comprehensive guide to Google BigQuery, its architecture, and a beginner-friendly tutorial on how to use Google BigQuery for your data warehousing activities. Search no more! Did you know ?
Read this blog further to explore the Hive Architecture and its indispensable role in the landscape of big data projects. Hive is a data warehousing and SQL-like query language system built on top of Hadoop. It is designed to facilitate querying and managing large datasets in a distributed storage environment.
A data engineer can fulfill the above-mentioned responsibilities only if they possess a suitable skill set. And if you are now searching for a list of that highlights those skills, head over to the next section of this blog. as they are required for processing large datasets.
This blog post provides an overview of the top 10 data engineering tools for building a robust data architecture to support smooth business operations. Table of Contents What are Data Engineering Tools? This speeds up dataprocessing by reducing disc read and write times.
However, building and maintaining a scalable data science pipeline comes with challenges like data quality , integration complexity, scalability, and compliance with regulations like GDPR. Characteristics of a Data Science Pipeline A well-designed data science pipeline helps processdata from source to insights seamlessly.
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. Open Table Format (OTF) architecture now provides a solution for efficient data storage, management, and processing while ensuring compatibility across different platforms.
These platforms facilitate effective data management and other crucial Data Engineering activities. This blog will give you an overview of the GCP data engineering tools thriving in the big data industry and how these GCP tools are transforming the lives of data engineers.
This blog presents some of the most unique and exciting AWS projects from beginner to advanced levels. AWS (Amazon Web Services) is the leading global cloud platform, offering over 200 fully featured services from data centers worldwide. You can work on these AWS sample projects to expand your skills and knowledge.
With Azure Databricks, managing and analyzing large volumes of data becomes effortlessly seamless. So, if you're a data professional ready to embark on a data-driven adventure, read this blog till the end as we unravel the secrets of Azure Databricks and discover the limitless possibilities it holds.
MoEs necessitate less compute for pre-training compared to dense models, facilitating the scaling of model and dataset size within similar computational budgets. link] QuantumBlack: Solving data quality for gen AI applications Unstructured dataprocessing is a top priority for enterprises that want to harness the power of GenAI.
Table of Contents 20 Open Source Big Data Projects To Contribute How to Contribute to Open Source Big Data Projects? 20 Open Source Big Data Projects To Contribute There are thousands of open-source projects in action today. This blog will walk through the most popular and fascinating open source big data projects.
This blog introduces five interesting AWS Lambda project ideas that will show you where and how to implement Lambda in the best possible way. Learn more about real-world big data applications with unique examples of big data projects. The dataset includes widely popular YouTube videos (in CSV files). PREVIOUS NEXT <
Power BI’s extensive modeling, real-time high-level analytics, and custom development simplify working with data. You will often need to work around several features to get the most out of business data with Microsoft Power BI. Additionally, it manages sizable datasets without causing Power BI to crash or perform less quickly.
Automation, AI, DataOps, and strategic alignment are no longer optional —they are essential components of a successful data strategy. As we look towards 2025, it’s clear that data teams must evolve to meet the demands of evolving technology and opportunities. How effective are your current data workflows?
However, due to the absence of a control group in these countries, we adopt a synthetic control framework ( blog post ) to estimate the counterfactual scenario. Before starting any math, we need to ensure a high quality historical dataset. Data quality plays a huge role in this work.
Using Artificial Intelligence (AI) in the Data Analytics process is the first step for businesses to understand AI's potential. This blog revolves around helping individuals realize this potential through its applications, advantages, and project examples. from 2022 to 2030.
So, when is it better to processdata in bulk, and when should you take the plunge into real-time data streams? This blog will break down the key differences between batch and stream processing, comparing them in terms of performance, latency, scalability, and fault tolerance.
Raw data, however, is frequently disorganised, unstructured, and challenging to work with directly. Dataprocessing analysts can be useful in this situation. Let’s take a deep dive into the subject and look at what we’re about to study in this blog: Table of Contents What Is DataProcessing Analysis?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















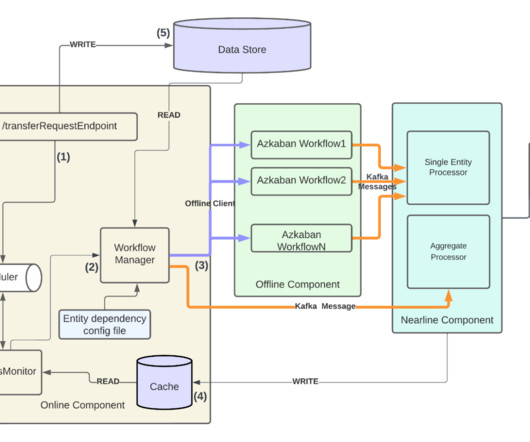





















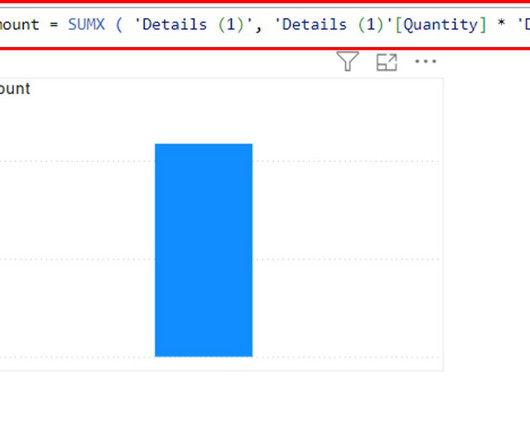

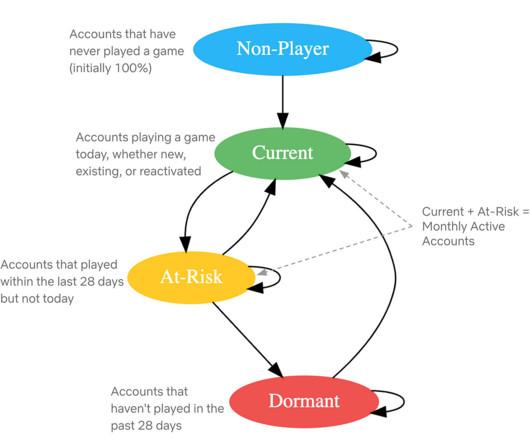









Let's personalize your content