This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Batch dataprocessing — historically known as ETL — is extremely challenging. In this post, we’ll explore how applying the functional programming paradigm to data engineering can bring a lot of clarity to the process. Late arriving facts Late arriving facts can be problematic with a strict immutable data policy.
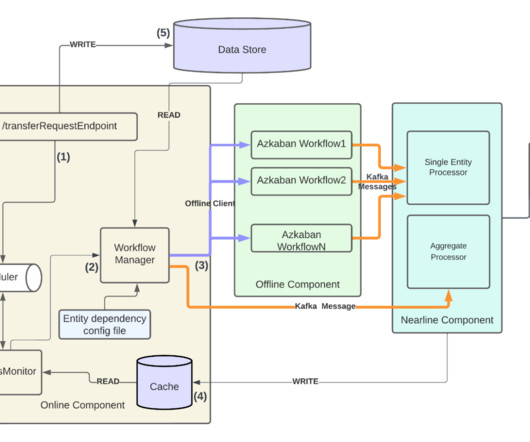
By Abhinaya Shetty , Bharath Mummadisetty In the inaugural blog post of this series, we introduced you to the state of our pipelines before Psyberg and the challenges with incremental processing that led us to create the Psyberg framework within Netflix’s Membership and Finance data engineering team.
This belief has led us to developing Privacy Aware Infrastructure (PAI) , which offers efficient and reliable first-class privacy constructs embedded in Meta infrastructure to address different privacy requirements, such as purpose limitation , which restricts the purposes for which data can be processed and used.
Metadata is the information that provides context and meaning to data, ensuring it’s easily discoverable, organized, and actionable. It enhances data quality, governance, and automation, transforming raw data into valuable insights. This is what managing data without metadata feels like. Chaos, right?
Data consistency, feature reliability, processing scalability, and end-to-end observability are key drivers to ensuring business as usual (zero disruptions) and a cohesive customer experience. With our new dataprocessing framework, we were able to observe a multitude of benefits, including 99.9%
Automation, AI, DataOps, and strategic alignment are no longer optional —they are essential components of a successful data strategy. As we look towards 2025, it’s clear that data teams must evolve to meet the demands of evolving technology and opportunities. How effective are your current data workflows?
The blog took out the last edition’s recommendation on AI and summarized the current state of AI adoption in enterprises. The simplistic model expressed in the blog made it easy for me to reason about the transactional system design. Kafka is probably the most reliable data infrastructure in the modern data era.
Open Table Format (OTF) architecture now provides a solution for efficient data storage, management, and processing while ensuring compatibility across different platforms. In this blog, we will discuss: What is the Open Table format (OTF)? First, we create an Iceberg table in Snowflake and then insert some data.
Its main purpose is to enable easy unit testing of your data pipelines, but it can technically be used in any other situations as a readable data format for small data sets. All the above commands are very likely to be described in separate future blog posts, but right now let’s focus on the dataflow sample command.
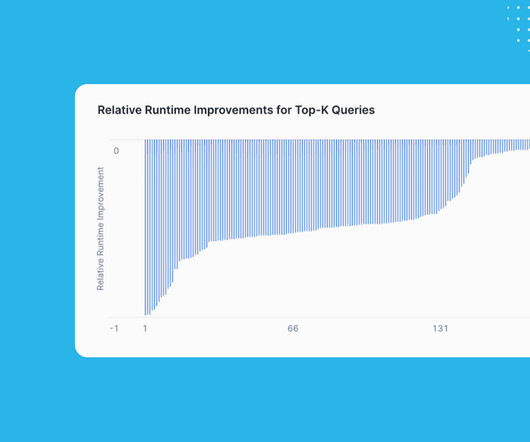
As we describe in this blog post , the top-k feature uses runtime information — namely, the current contents of the top-k elements — to skip micro-partitions where we can guarantee that they won’t contribute to the overall result. Snowflake starts processing those partitions first. on average, with some queries also reaching up to 99.8%
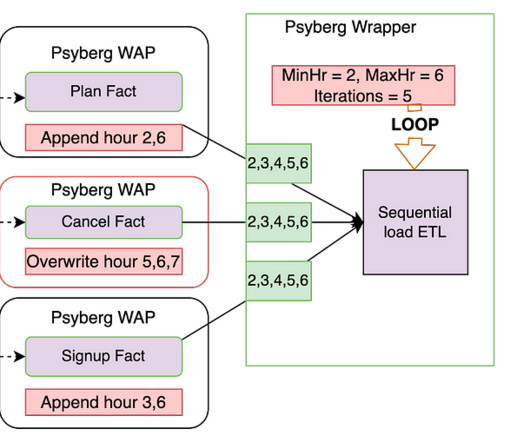
In this context, managing the data, especially when it arrives late, can present a substantial challenge! In this three-part blog post series, we introduce you to Psyberg , our incremental dataprocessing framework designed to tackle such challenges! Let’s dive in! To solve these problems, we came up with Psyberg!
In this blog, I will demonstrate the value of Cloudera DataFlow (CDF) , the edge-to-cloud streaming data platform available on the Cloudera Data Platform (CDP) , as a Data integration and Democratization fabric. Data and Metadata: Data inputs and data outputs produced based on the application logic.
Liang Mou; Staff Software Engineer, Logging Platform | Elizabeth (Vi) Nguyen; Software Engineer I, Logging Platform | In today’s data-driven world, businesses need to process and analyze data in real-time to make informed decisions. What is Change Data Capture? Why is CDC Important? or its affiliates.
Automation, AI, DataOps, and strategic alignment are no longer optional —they are essential components of a successful data strategy. As we look towards 2025, it’s clear that data teams must evolve to meet the demands of evolving technology and opportunities. How effective are your current data workflows?
By Abhinaya Shetty , Bharath Mummadisetty This blog post will cover how Psyberg helps automate the end-to-end catchup of different pipelines, including dimension tables. In the previous installments of this series, we introduced Psyberg and delved into its core operational modes: Stateless and Stateful DataProcessing.
In addition to big data workloads, Ozone is also fully integrated with authorization and data governance providers namely Apache Ranger & Apache Atlas in the CDP stack. While we walk through the steps one by one from data ingestion to analysis, we will also demonstrate how Ozone can serve as an ‘S3’ compatible object store.
[link] Georg Heiler: Upskilling data engineers What should I prefer for 2028, or how can I break into data engineering? I honestly don’t have a solid answer, but this blog is an excellent overview of upskilling. These are common LinkedIn requests.
link] Netflix: A Recap of the Data Engineering Open Forum at Netflix Netflix publishes a recap of all the talks in the first Data Engineering open forum tech meetups. The blog contains a summary of each talk and a link to the YouTube channel with all the talks. Are there enough usecases?
It requires a state-of-the-art system that can track and process these impressions while maintaining a detailed history of each profiles exposure. This nuanced integration of data and technology empowers us to offer bespoke content recommendations.
The fact that ETL tools evolved to expose graphical interfaces seems like a detour in the history of dataprocessing, and would certainly make for an interesting blog post of its own. Sure, there’s a need to abstract the complexity of dataprocessing, computation and storage.
This blog captures the current state of Agent adoption, emerging software engineering roles, and the use case category. Generative AI demands the processing of vast amounts of diverse, unstructured data (e.g., meeting recordings and videos), which contrasts with traditional SQL-centric systems for structured data.
This is part 2 in this blog series. You can read part 1, here: Digital Transformation is a Data Journey From Edge to Insight. The first blog introduced a mock connected vehicle manufacturing company, The Electric Car Company (ECC), to illustrate the manufacturing data path through the data lifecycle.
In the second part, we will focus on architectural patterns to implement data quality from a data contract perspective. Why is Data Quality Expensive? I won’t bore you with the importance of data quality in the blog. Let’s talk about the dataprocessing types.
Data users in these enterprises don’t know how data is derived and lack confidence in whether it’s the right source to use. . If data access policies and lineage aren’t consistent across an organization’s private cloud and public clouds, gaps will exist in audit logs. From Bad to Worse.
Recently, we announced enhanced multi-function analytics support in Cloudera Data Platform (CDP) with Apache Iceberg. Iceberg is a high-performance open table format for huge analytic data sets. The post Streaming Ingestion for Apache Iceberg With Cloudera Stream Processing appeared first on Cloudera Blog.
The blog is an excellent comparison study of Ray vs. Dask’s performance. The author discusses the OneTable sync mechanism among all three major LakeHouse formats in this blog. The blog discusses Psyberg’s two operational models, stateless & stateful dataprocessing. Stores metadata to utilize later.
It is a replicated, highly-available service that is responsible for managing the metadata for all objects stored in Ozone. As Ozone scales to exabytes of data, it is important to ensure that Ozone Manager can perform at scale. The hardware specifications are included at the end of this blog.
In Part 2 of our blog series, we described how we were able to integrate Ray(™) into our existing ML infrastructure. In this blog post, we will discuss a second type of popular application of Ray(™) at Pinterest: offline batch inference of ML models. Ray Data is not bound to any specific ML library.
With in-place table migration, you can rapidly convert to Iceberg tables since there is no need to regenerate data files. Only metadata will be regenerated. Newly generated metadata will then point to source data files as illustrated in the diagram below. . Data quality using table rollback. Metadata management .
The table information (such as schema, partition) is stored as part of the metadata (manifest) file separately, making it easier for applications to quickly integrate with the tables and the storage formats of their choice. Change data capture (CDC). 3: Open Performance.
So, embrace the power of Change Data Capture, and embark on a captivating journey where the magic of real-time data awaits. In this blog, we will cover: What Is CDC and Its Benefits? These additional columns store metadata like timestamps, user IDs, and change types, ensuring granular change tracking and auditability.
Open source data lakehouse deployments are built on the foundations of compute engines (like Apache Spark, Trino, Apache Flink), distributed storage (HDFS, cloud blob stores), and metadata catalogs / table formats (like Apache Iceberg, Delta, Hudi, Apache Hive Metastore). Tables are governed as per agreed upon company standards.
Do ETL and data integration activities seem complex to you? Read this blog to understand everything about AWS Glue that makes it one of the most popular data integration solutions in the industry. Did you know the global big data market will likely reach $268.4 Businesses are leveraging big data now more than ever.
During the transformation phase, data is processed and converted into the appropriate format for the target destination. While legacy ETL has a slow transformation step, modern ETL platforms replace disk-based processing with in-memory processing to allow for real-time dataprocessing, enrichment, and analysis.
In our previous blog post we introduced Edgar, our troubleshooting tool for streaming sessions. We could also get contextual information about the streaming session by joining relevant traces with account metadata and service logs. The next challenge was to stream large amounts of traces via a scalable dataprocessing platform.
We scored the highest in hybrid, intercloud, and multi-cloud capabilities because we are the only vendor in the market with a true hybrid data platform that can run on any cloud including private cloud to deliver a seamless, unified experience for all data, wherever it lies. Sign up for a trial to see for yourself.
CDF-PC enables Apache NiFi users to run their existing data flows on a managed, auto-scaling platform with a streamlined way to deploy NiFi data flows and a central monitoring dashboard making it easier than ever before to operate NiFi data flows at scale in the public cloud. The need for a cloud-native Apache NiFi service.
This was a great conversation about the complexities of working in a niche domain of data analysis and how to build a pipeline of high quality data from collection to analysis.
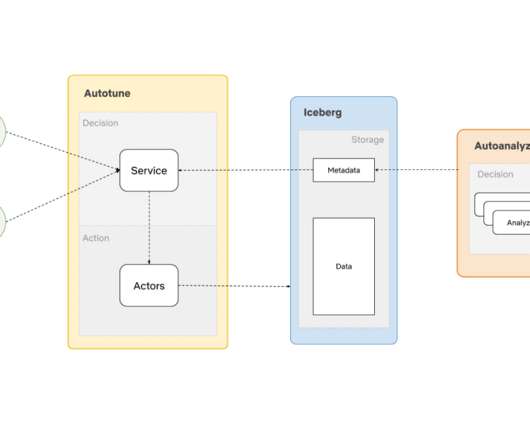
On the other hand, these optimizations themselves need to be sufficiently inexpensive to justify their own processing cost over the gains they bring. We built AutoOptimize to efficiently and transparently optimize the data and metadata storage layout while maximizing their cost and performance benefits.
He wrote some years ago 3 articles defining data engineering field. Some concepts When doing data engineering you can touch a lot of different concepts. Read technical blogs, watch conferences and read 📘 Designing Data-Intensive Applications (even if it could be overkill). Is it really modern?
In this blog post, we will discuss the AvroTensorDataset API, techniques we used to improve dataprocessing speeds by up to 162x over existing solutions (thereby decreasing overall training time by up to 66%), and performance results from benchmarks and production. The rest of the steps act as consumers of prefetched bytes.
The first generation of the Hive Metastore attempted to address the performance considerations to run SQL efficiently on a data lake. It provided the concept of a database, schemas, and tables for describing the structure of a data lake in a way that let BI tools traverse the data efficiently.
Use cases like fraud detection, network threat analysis, manufacturing intelligence, commerce optimization, real-time offers, instantaneous loan approvals, and more are now possible by moving the dataprocessing components up the stream to address these real-time needs. . Not in the manufacturing space? Not to worry.
Data Performance Testing Data performance testing is the process of evaluating the efficiency, effectiveness, and scalability of your dataprocessing systems and infrastructure. To perform data performance testing, you should first establish performance benchmarks and targets for your dataprocessing systems.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content