This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
However, this is still not common in the Data Warehouse (DWH) field. In my recent blog, I researched OLAP technologies, for this post I chose some open-source technologies and used them together to build a full data architecture for a Data Warehouse system. Why is this?
I found the blog to be a fresh take on the skill in demand by layoff datasets. DeepSeek’s smallpond Takes on Big Data. DeepSeek continues to impact the Data and AI landscape with its recent open-source tools, such as Fire-Flyer File System (3FS) and smallpond. link] Mehdio: DuckDB goes distributed?
This blog post was written by Dean Bubley , industry analyst, as a guest author for Cloudera. . The focus has also been hugely centred on compute rather than datastorage and analysis. But there may be a large gap between when “compute” occurs, compared to when data is collected and how it is stored.
Data engineering can help with it. It is the force behind seamless data flow, enabling everything from AI-driven automation to real-time analytics. To stay competitive, businesses need to adapt to new trends and find new ways to deal with ongoing problems by taking advantage of new possibilities in data engineering.
Though basic and easy to use, traditional table storage formats struggle to keep up. Open Table Format (OTF) architecture now provides a solution for efficient datastorage, management, and processing while ensuring compatibility across different platforms. In this blog, we will discuss: What is the Open Table format (OTF)?
Python is used extensively among Data Engineers and Data Scientists to solve all sorts of problems from ETL/ELT pipelines to building machine learning models. Apache HBase is an effective datastorage system for many workflows but accessing this data specifically through Python can be a struggle. Put Operations.
This blog post describes the advantages of real-time ETL and how it increases the value gained from Snowflake implementations. With instant elasticity, high-performance, and secure data sharing across multiple clouds , Snowflake has become highly in-demand for its cloud-based data warehouse offering.
Summer in coming ( credits ) Hey, new Friday, new Data News edition. Thank you for every recommendation you do about the blog or the Data News. There is an introduction post about DataHub — when you look at what you have to run to launch a data catalog: 4 components and 4 different datastorage.
To help other people find the show you can leave a review on iTunes , or Google Play Music , and tell your friends and co-workers This is your host Tobias Macey and today I’m interviewing Julien Le Dem and Doug Cutting about data serialization formats and how to pick the right one for your systems.
However, one of the most common challenges faced by data engineers is the evolution of schemas as new data comes in. Schema evolution refers to the ability of a system to adapt to changes in the structure of incoming data without breaking existing workflows.
Such a status has yet to be granted and without which, data transfers between the UK and the EU will not be lawfully permitted post-December 31st 2020. Without an agreed legislative route to allow datastorage and processing in the US and EU, the UK Government will be left with one option; storage and processing within the UK only.
I will write a separate blog on these announcements after the Databricks conference; in the meantime, I found the blog from Cube Research, a balanced article about Snowflake Summit. link] Open AI: Model Spec LLM models are slowly emerging as the intelligent datastorage layer. Will they co-exist or fight with each other?
Hybrid Horses for Courses: The Right Cloud for AI from Pilot to Production at Scale Later, on May 14 at 12:40 pm BST , hear from Mark Samson, one of Cloudera’s solutions engineering directors, on whether a data center or cloud deployment is best for your organization’s data platform and architecture.
Managing the data that represents organizational knowledge is easy for any developer and does not require exhaustive cycles of data science work. Utilizing Pinecone for vector datastorage over an in-house open-source vector store can be a prudent choice for organizations.
We have published a detailed blog post of its modeling architecture. While it is blessed with an abundance of data for training, it is also crucial to maintain a high datastorage efficiency. To learn more about engineering at Pinterest, check out the rest of our Engineering Blog and visit our Pinterest Labs site.
By focusing on these attributes, data engineers can build pipelines that not only meet current demands but are also prepared for future challenges. In this blog post, we’ll explore key strategies for future-proofing your data pipelines. We’ll explore scalability, integration, security, and cost management.
CIO blog post : “Digital transformation is a foundational change in how an organization delivers value to its customers.”. We see this consistently in the data platform/datastorage space. . Replacing redundant datastorage is a clear opportunity in this category. appeared first on Cloudera Blog.
Under this framework, AWS guarantees the security of the cloud, encompassing physical infrastructure, networking, and virtualization layers, while customers safeguard their workloads, data, and configurations in the cloud. This segregation of duties streamlines operations, empowering organizations to innovate without compromising security.
The powerful platform data security and governance layer, Shared Data Experience (SDX) , is a fundamental part of the open data lakehouse, in the data center just as it is in the cloud. Learn more about the next generation of Cloudera Data Platform for Private Cloud.
It is especially true in the world of big data. If you want to stay ahead of the curve, you need to be aware of the top big data technologies that will be popular in 2024. In this blog post, we will discuss such technologies. Let's explore the technologies available for big data.
The remainder of this blog post provides more detail on functionality and hosting options. You can host it in Snowflake managed infrastructure or your infrastructure of choice. Polaris Catalog will be both open sourced in the next 90 days and available to run in public preview in Snowflake infrastructure soon.
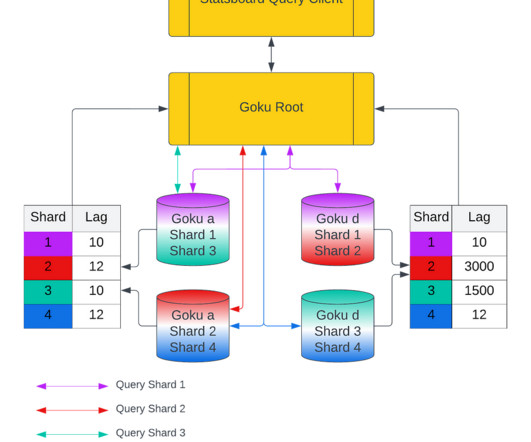
In the first blog, we will share a short summary on the GokuS and GokuL architecture, data format for Goku Long Term, and how we improved the bootstrap time for our storage and serving components. Goku Long Term Storage Architecture Summary and Challenges Figure 9: Flow of data from GokuS to GokuL.
Their methods enabled them to intercept sensitive information like personal messages, banking details, and other confidential data. In this blog, we’ll dive into the top 7 mobile security threats that are putting both personal and organizational data at risk and explore effective strategies to defend against these dangers.
There are a few ways that graph structures and properties can be implemented, including the ability to store data in the vertices connecting nodes and the structures that can be contained within the nodes themselves. How does the query interface and datastorage in DGraph differ from other options?
According to Dinesh Chandrasekhar, the Director Product Marketing at Cloudera, data decay – or deterioration – complicates an already complex ecosystem defined by the exponential explosion of data from streaming sources such as IoT. The intelligence revolution driven by fast data is already well underway.
File systems can store small datasets, while computer clusters or cloud storage keeps larger datasets. According to a database model, the organization of data is known as database design. The designer must decide and understand the datastorage, and inter-relation of data elements.
Cloudera is proud to provide the underlying data management fabric to the solution – everything from reliably moving connected vehicle data to the Cloud, to providing large scale datastorage, processing, analytics and machine learning – the foundations of real-time insights and in-vehicle decision making.” .
Data powers Uber’s global marketplace, enabling more reliable and seamless user experiences across our products for riders, … The post Databook: Turning Big Data into Knowledge with Metadata at Uber appeared first on Uber Engineering Blog.
The other half of the equation requires your team’s emphasis to shift to sustained excellence in managing and optimizing your data ecosystem — better known as Day 2 operations. In this blog, we’ll cover the highlights of our recently published Day 2 Operations Guide and why it matters to enterprises.
formats — This is a huge part of data engineering. Picking the right format for your datastorage. You'll be also asked to put in place a data infrastructure. It means a data warehouse, a data lake or other concepts starting with data. My advice on this point is to learn from others.
This is especially crucial to state and local government IT teams, who must balance their vital missions against resource constraints, compliance requirements, cybersecurity risks, and ever-increasing volumes of data. The post Hybrid Data Cloud Success for State and Local Governments appeared first on Cloudera Blog.
A shared, scalable data store that spans the enterprise enables a holistic approach. A converged data approach enables more comprehensive analysis while reducing duplication of datastorage. It can be used by third-party platforms, analysts, data scientists and the lines of business.
This scalability ensures the data lakehouse remains responsive and performant, even as data complexity and usage patterns change over time. Learn more about the Cloudera Open Data Lakehouse here. The post Unify your data: AI and Analytics in an Open Lakehouse appeared first on Cloudera Blog.
Both companies have added Data and AI to their slogan, Snowflake used to be The Data Cloud and now they're The AI Data Cloud. I won't delve into every announcement here, but for more details, SELECT has written a blog covering the 28 announcements and takeaways from the Summit.
Network operating systems let computers communicate with each other; and datastorage grew—a 5MB hard drive was considered limitless in 1983 (when compared to a magnetic drum with memory capacity of 10 kB from the 1960s). The amount of data being collected grew, and the first data warehouses were developed.
This blog post explores how Snowflake can help with this challenge. Legacy SIEM cost factors to keep in mind Data ingestion: Traditional SIEMs often impose limits to data ingestion and data retention. Now there are a few ways to ingest data into Snowflake. But what if security teams didn’t have to make tradeoffs?
Translation: Government agencies — especially those under the Department of Defense (DoD) — have use cases that require datastorage and analytic workloads to be maintained on premises to retain absolute control of data security, privacy, and cost predictability. . Learn more about CDP Private Cloud here.
With more than 25TB of data ingested from over 200 different sources, Telkomsel recognized that to best serve its customers it had to get to grips with its data. . Its initial step in the pursuit of a digital-first strategy saw it turn to Cloudera for a more agile and cost-effective datastorage infrastructure.
ELT offers a solution to this challenge by allowing companies to extract data from various sources, load it into a central location, and then transform it for analysis. The ELT process relies heavily on the power and scalability of modern datastorage systems. The data is loaded as-is, without any transformation.
In this blog post, we will look into benchmark test results measuring the performance of Apache Hadoop Teragen and a directory/file rename operation with Apache Ozone (native o3fs) vs. Ozone S3 API*. The post Apache Ozone – A High Performance Object Store for CDP Private Cloud appeared first on Cloudera Blog. ZooKeeper 3.5.5
Structured data (such as name, date, ID, and so on) will be stored in regular SQL databases like Hive or Impala databases. There are also newer AI/ML applications that need datastorage, optimized for unstructured data using developer friendly paradigms like Python Boto API.
It means that there is a high risk of data loss but Apache Kafka solves this because it is distributed and can easily scale horizontally and other servers can take over the workload seamlessly. Kafka can also be used to stream data from IoT devices or sensors. We will come up with more such use cases in our upcoming blogs.
HBase is a column-oriented datastorage architecture that is formed on top of HDFS to overcome its limitations. The post Getting Started with Cloudera Data Platform Operational Database (COD) appeared first on Cloudera Blog. Build and run the applications. Apache HBase.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content