This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This belief has led us to developing Privacy Aware Infrastructure (PAI) , which offers efficient and reliable first-class privacy constructs embedded in Meta infrastructure to address different privacy requirements, such as purpose limitation , which restricts the purposes for which data can be processed and used. Hack, C++, Python, etc.)
Performance is one of the key, if not the most important deciding criterion, in choosing a Cloud DataWarehouse service. In today’s fast changing world, enterprises have to make data driven decisions quickly and for that they rely heavily on their datawarehouse service. . Cloudera DataWarehouse vs HDInsight.
In a previous blog post on CDW performance, we compared Azure HDInsight to CDW. In this blog post, we compare Cloudera DataWarehouse (CDW) on Cloudera Data Platform (CDP) using Apache Hive-LLAP to EMR 6.0 (also powered by Apache Hive-LLAP) on Amazon using the TPC-DS 2.9 More on this later in the blog.
Data powers Uber’s global marketplace, enabling more reliable and seamless user experiences across our products for riders, … The post Databook: Turning Big Data into Knowledge with Metadata at Uber appeared first on Uber Engineering Blog.
Over the years, the technology landscape for data management has given rise to various architecture patterns, each thoughtfully designed to cater to specific use cases and requirements. These patterns include both centralized storage patterns like datawarehouse , data lake and data lakehouse , and distributed patterns such as data mesh.
To ensure comprehensive protection, it is essential to apply the necessary steps to all systems that store or process data, including distributed systems (web systems, chat, mobile and backend services) and datawarehouses. Consider the data flow from online systems to the datawarehouse, as shown in the diagram below.
Cloud datawarehouses allow users to run analytic workloads with greater agility, better isolation and scale, and lower administrative overhead than ever before. The results demonstrate superior price performance of Cloudera DataWarehouse on the full set of 99 queries from the TPC-DS benchmark. Introduction.
By Anupom Syam Background At Netflix, our current datawarehouse contains hundreds of Petabytes of data stored in AWS S3 , and each day we ingest and create additional Petabytes. Some of the optimizations are prerequisites for a high-performance datawarehouse.
The blog highlights how moving from 6-character base-64 to 20-digit base-2 file distribution brings more distribution in S3 and reduces request failures. link] Jon Osborn: Best Practices for Using QUERY_TAG in Snowflake The modern datawarehouses are good at running at scale, given the cost is not a constraint.
Making a decision on a cloud datawarehouse is a big deal. Modernizing your data warehousing experience with the cloud means moving from dedicated, on-premises hardware focused on traditional relational analytics on structured data to a modern platform.
Snowflake was founded in 2012 around its datawarehouse product, which is still its core offering, and Databricks was founded in 2013 from academia with Spark co-creator researchers, becoming Apache Spark in 2014. It adds metadata, read, write and transactions that allow you to treat a Parquet file as a table.
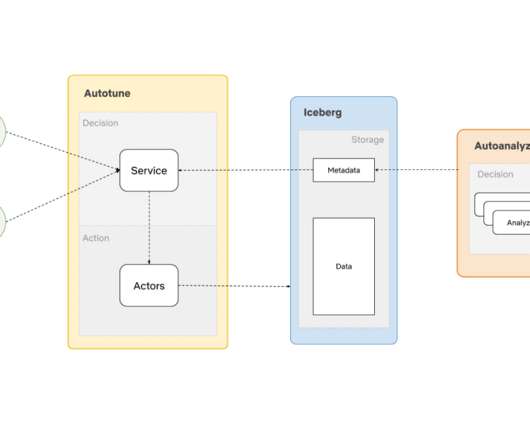
In this blog, we will share with you in detail how Cloudera integrates core compute engines including Apache Hive and Apache Impala in Cloudera DataWarehouse with Iceberg. We will publish follow up blogs for other data services. Iceberg basics Iceberg is an open table format designed for large analytic workloads.
Some of the most powerful results come from combining complementary superpowers, and the “dynamic duo” of Apache Hive LLAP and Apache Impala, both included in Cloudera DataWarehouse , is further evidence of this. Both Impala and Hive can operate at an unprecedented and massive scale, with many petabytes of data.
This blog post expands on that insightful conversation, offering a critical look at Iceberg's potential and the hurdles organizations face when adopting it. This ecosystem includes: Catalogs: Services that manage metadata about Iceberg tables (e.g., Compute Engines: Tools that query and process data stored in Iceberg tables (e.g.,
Open Table Format (OTF) architecture now provides a solution for efficient data storage, management, and processing while ensuring compatibility across different platforms. In this blog, we will discuss: What is the Open Table format (OTF)? First, we create an Iceberg table in Snowflake and then insert some data.
Today’s customers have a growing need for a faster end to end data ingestion to meet the expected speed of insights and overall business demand. This ‘need for speed’ drives a rethink on building a more modern datawarehouse solution, one that balances speed with platform cost management, performance, and reliability.
The fact that ETL tools evolved to expose graphical interfaces seems like a detour in the history of data processing, and would certainly make for an interesting blog post of its own. Sure, there’s a need to abstract the complexity of data processing, computation and storage.
Consensus seeking Whether you think that old-school data warehousing concepts are fading or not, the quest to achieve conformed dimensions and conformed metrics is as relevant as it ever was. The datawarehouse needs to reflect the business, and the business should have clarity on how it thinks about analytics.
How self-service data warehousing frees IT resources. Cloudera DataWarehouse (CDW) is a cloud service and an integral part of the newly released Cloudera Data Platform (CDP). Key features are: Highly scalable and performant open-source engines for BI and data warehousing workloads. Simplified provisioning.
Summary The majority of blog posts and presentations about data engineering and analytics assume that the consumers of those efforts are internal business users accessing an environment controlled by the business. Atlan is the metadata hub for your data ecosystem.
Note that where a TRUNCATE PARTITION is typically a “free” metadata operation, a DELETE operation may be expensive and that should be taken into considerations. This means that ideally the logic in source control describes how to build the full state of the datawarehouse throughout all time periods.
The most commonly used one is dataflow project , which helps folks in managing their data pipeline repositories through creation, testing, deployment and few other activities. It lets you create YAML formatted mock data files based on selected tables, columns and a few rows of data from the Netflix datawarehouse.
This is part 2 in this blog series. You can read part 1, here: Digital Transformation is a Data Journey From Edge to Insight. The first blog introduced a mock connected vehicle manufacturing company, The Electric Car Company (ECC), to illustrate the manufacturing data path through the data lifecycle.
Data volume and velocity, governance, structure, and regulatory requirements have all evolved and continue to. Despite these limitations, datawarehouses, introduced in the late 1980s based on ideas developed even earlier, remain in widespread use today for certain business intelligence and data analysis applications.
We are proud to announce the general availability of Cloudera Altus DataWarehouse , the only cloud data warehousing service that brings the warehouse to the data. Modern data warehousing for the cloud. Modern data warehousing for the cloud. Using Cloudera Altus for your cloud datawarehouse.
Datafold also helps automate regression testing of ETL code with its Data Diff feature that instantly shows how a change in ETL or BI code affects the produced data, both on a statistical level and down to individual rows and values. RudderStack’s smart customer data pipeline is warehouse-first.
Our investments in a lakeless datawarehouse, modern analytics platform, and strong master data practices have made data a core strategic capability. This blog reflects on key milestones, cultural shifts, and personal growth along theway. Our journey is well-documented in Picnic tech blog posts.
At TCS , we help companies shift their enterprise datawarehouse (EDW) platforms to the cloud as well as offering IT services. We’re extremely familiar with just how tricky a cloud migration can be, especially when it involves moving historical business data. Use separate datawarehouses for cost-effective data loading.
The blog highlights the advantages of GNN over traditional machine learning models, which struggle to discern relationships between various entities, such as users and restaurants, and edges, such as order. The author highlights Paimon’s consistency model by examining the metadata model.
Overview This blog post describes support for materialized views for the Iceberg table format. It brings the reliability and simplicity of SQL tables to big data while enabling engines like Hive, Impala, Spark, Trino, Flink, and Presto to work with the same tables at the same time. Starting from the CDW Public Cloud DWX-1.6.1
Cloudera and Accenture demonstrate strength in their relationship with an accelerator called the Smart Data Transition Toolkit for migration of legacy datawarehouses into Cloudera Data Platform. Accenture’s Smart Data Transition Toolkit . Are you looking for your datawarehouse to support the hybrid multi-cloud?
Since the value of data quickly drops over time, organizations need a way to analyze data as it is generated. To avoid disruptions to operational databases, companies typically replicate data to datawarehouses for analysis.
Data engineering inherits from years of data practices in US big companies. Hadoop initially led the way with Big Data and distributed computing on-premise to finally land on Modern Data Stack — in the cloud — with a datawarehouse at the center. My advice on this point is to learn from others.
Your sunk costs are minimal and if a workload or project you are supporting becomes irrelevant, you can quickly spin down your cloud datawarehouses and not be “stuck” with unused infrastructure. Cloud deployments for suitable workloads gives you the agility to keep pace with rapidly changing business and data needs.
However, for all of our uncertified data, which remained the majority of our offline data, we lacked visibility into its quality and didn’t have clear mechanisms for up-leveling it. How could we scale the hard-fought wins and best practices of Midas across our entire datawarehouse?
While cloud-native, point-solution datawarehouse services may serve your immediate business needs, there are dangers to the corporation as a whole when you do your own IT this way. Cloudera DataWarehouse (CDW) is here to save the day! CDW is an integrated datawarehouse service within Cloudera Data Platform (CDP).
These lakes power mission critical large scale data analytics, business intelligence (BI), and machine learning use cases, including enterprise datawarehouses. In recent years, the term “data lakehouse” was coined to describe this architectural pattern of tabular analytics over data in the data lake.
Many organizations struggle to meet growing and variable datawarehouse demands. This is exactly what Cloudera Data Platform (CDP) provides to the Cloudera DataWarehouse. CDP is a data platform that is optimized for both business units and central IT. . Cloudera DataWarehouse Security.
analyst Sumit Pal, in “Exploring Lakehouse Architecture and Use Cases,” published January 11, 2022: “Data lakehouses integrate and unify the capabilities of datawarehouses and data lakes, aiming to support AI, BI, ML, and data engineering on a single platform.” Iceberg handles massive data born in the cloud.
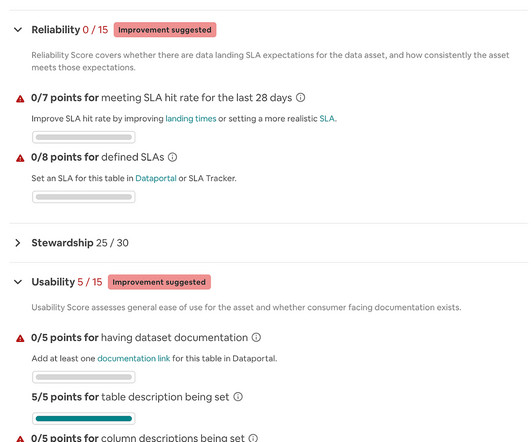
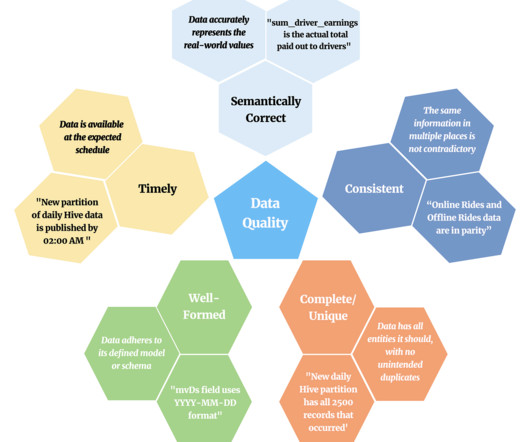
In this post we will define data quality at a high-level and explore our motivation to achieve better data quality. We will then introduce our in-house product, Verity, and showcase how it serves as a central platform for ensuring data quality in our Hive DataWarehouse. What and Where is Data Quality?
Cloudera Data Platform (CDP) scored among the top 10 vendors on all four Analytical Use Cases — DataWarehouse, Logical DataWarehouse, Data Lake and Operational Intelligence in the Critical Capabilities for Cloud Database Management Systems for Analytics Use Cases.
In the second part, we will focus on architectural patterns to implement data quality from a data contract perspective. Why is Data Quality Expensive? I won’t bore you with the importance of data quality in the blog. Event Routers can add additional metadata to the envelope of the event. How to Fix It?
With in-place table migration, you can rapidly convert to Iceberg tables since there is no need to regenerate data files. Only metadata will be regenerated. Newly generated metadata will then point to source data files as illustrated in the diagram below. . Data quality using table rollback. Metadata management .
So, embrace the power of Change Data Capture, and embark on a captivating journey where the magic of real-time data awaits. In this blog, we will cover: What Is CDC and Its Benefits? CDC also plays a crucial role in data integration and ETL processes. Where Is CDC Used and Who Uses It?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content