This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Unlocking Data Team Success: Are You Process-Centric or Data-Centric? We’ve identified two distinct types of data teams: process-centric and data-centric. We’ve identified two distinct types of data teams: process-centric and data-centric. They work in and on these pipelines.
The blog emphasizes the importance of starting with a clear client focus to avoid over-engineering and ensure user-centric development. link] Gunnar Morling: Revisiting the Outbox Pattern The blog is an excellent summary of the path we crossed with the outbox pattern and the challenges ahead.
The blog is an excellent summarization of the common patterns emerging in GenAI platforms. Adopting LLM in SQL-centric workflow is particularly interesting since companies increasingly try text-2-SQL to boost data usage. Pipeline breakpoint feature. A key highlight for me is the following features from Maestro.
Bronze layers can also be the raw database tables. We have also seen a fourth layer, the Platinum layer , in companies’ proposals that extend the Data pipeline to OneLake and Microsoft Fabric. The need to copy data across layers, manage different schemas, and address data latency issues can complicate data pipelines.
link] Sponsored: DoubleCloud - More than just ClickHouse ClickHouse is the fastest, most resource-efficient OLAP database, which queries billions of rows in milliseconds and is trusted by thousands of companies for real-time analytics. The author highlights the structured approach to building data infrastructure, data management, and metrics.
As the databases professor at my university used to say, it depends. Using SQL to run your search might be enough for your use case, but as your project requirements grow and more advanced features are needed—for example, enabling synonyms, multilingual search, or even machine learning—your relational database might not be enough.
The fact that ETL tools evolved to expose graphical interfaces seems like a detour in the history of data processing, and would certainly make for an interesting blog post of its own. Storage and compute is cheaper than ever, and with the advent of distributed databases that scale out linearly, the scarcer resource is engineering time.
This blog discusses quantifications, types, and implications of data. Structured data can be defined as data that can be stored in relational databases, and unstructured data as everything else. The word “data” is ubiquitous in narratives of the modern world. And data, the thing itself, is vital to the functioning of that world.
This introductory blog focuses on an overview of our journey. Future blogs will provide deeper dives into each service, sharing insights and lessons learned from this process. Future blogs will provide deeper dives into each service, sharing insights and lessons learned from this process.
Take Astro (the fully managed Airflow solution) for a test drive today and unlock a suite of features designed to simplify, optimize, and scale your data pipelines. The blog is a good overview of various components in a typical data stack. Get Guide → Marc Olson: Continuous reinvention: A brief history of block storage at AWS.
For modern data engineers using Apache Spark, DE offers an all-inclusive toolset that enables data pipeline orchestration, automation, advanced monitoring, visual troubleshooting, and a comprehensive management toolset for streamlining ETL processes and making complex data actionable across your analytic teams. Job Deployment Made Simple.
2) Why High-Quality Data Products Beats Complexity in Building LLM Apps - Ananth Packildurai I will walk through the evolution of model-centric to data-centric AI and how data products and DPLM (Data Product Lifecycle Management) systems are vital for an organization's system. link] Nvidia: What Is Sovereign AI?
Data Engineering is typically a software engineering role that focuses deeply on data – namely, data workflows, data pipelines, and the ETL (Extract, Transform, Load) process. Data Engineers are engineers responsible for uncovering trends in data sets and building algorithms and data pipelines to make raw data beneficial for the organization.
The DataKitchen Platform serves as a process hub that builds temporary analytic databases for daily and weekly ad hoc analytics work. These limited-term databases can be generated as needed from automated recipes (orchestrated pipelines and qualification tests) stored and managed within the process hub. . The DataOps Advantage
SQL – A database may be used to build data warehousing, combine it with other technologies, and analyze the data for commercial reasons with the help of strong SQL abilities. Pipeline-centric: Pipeline-centric Data Engineers collaborate with data researchers to maximize the use of the info they gather.
This blog is for anyone who was interested but unable to attend the conference, or anyone interested in a quick summary of what happened there. Use cases such as fraud monitoring, real-time supply chain insight, IoT-enabled fleet operations, real-time customer intent, and modernizing analytics pipelines are driving development activity.
Kubernetes is a container-centric management software that allows the creation and deployment of containerized applications with ease. Here is a sample YAML file used to create a pod with the postgres database. To read more about Kubernetes and deployment, you can refer to the Best Kubernetes Course Online.
A curated list of the top 9 must read blogs on data. At the end of 2022 we decided to collect the blogs we enjoyed the most over the year. The data world is in turmoil and lots of exciting things happen every day, week and year. Happy reading!
Treating data as a product is more than a concept; it’s a paradigm shift that can significantly elevate the value that business intelligence and data-centric decision-making have on the business. Data pipelines Data integrity Data lineage Data stewardship Data catalog Data product costing Let’s review each one in detail.
With One Lake serving as a primary multi-cloud repository, Fabric is designed with an open, lake-centric architecture. Mirroring (a data replication capability) : Access and manage any database or warehouse from Fabric without switching database clients; Mirroring will be available for Azure Cosmos DB, Azure SQL DB, Snowflake, and Mongo DB.
In this blog post, we will see the top Automation testing tools used in the software industry. We can test all three layers of an application interface, the service layer and the database layer from a single console of UFT as it provides a graphical user interface. The tool is easy to use and facilitates fast creation.
Editors Note: 🔥 DEW is thrilled to announce a developer-centric Data Eng & AI conference in the tech hub of Bengaluru, India, on October 12th! LinkedIn write about Hoptimator for auto generated Flink pipeline with multiple stages of systems. Can't we use the vector feature in the existing databases?
One paper suggests that there is a need for a re-orientation of the healthcare industry to be more "patient-centric". Furthermore, clean and accessible data, along with data driven automations, can assist medical professionals in taking this patient-centric approach by freeing them from some time-consuming processes.
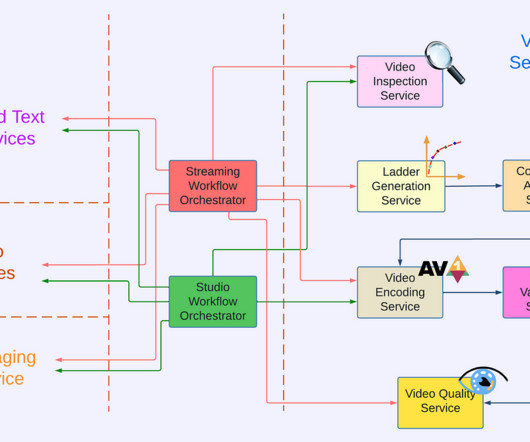
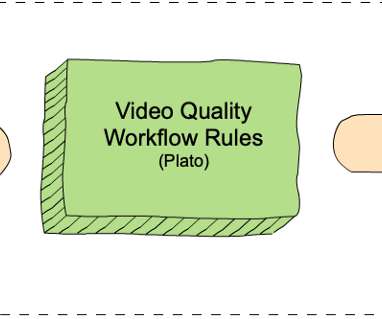
Moorthy and Zhi Li Introduction Measuring video quality at scale is an essential component of the Netflix streaming pipeline. Cosmos is a computing platform for workflow-driven, media-centric microservices. by Christos G. Bampis , Chao Chen , Anush K. We call this system Cosmos.
Learn more in our detailed guide to data lineage visualization (coming soon) Integration with Multiple Data Sources Data lineage tools are designed to integrate with a wide range of data sources, including databases, data warehouses, and cloud-based data platforms. One of the unique features of Atlan is its human-centric design.
As a result, a less senior team member was made responsible for modifying a production pipeline. When you architect for flexibility, quality, rapid deployment, and real-time data monitoring (in addition to your customer requirements), you move towards a DataOps-centric data engineering practice. A better ETL tool?
These are particularly frustrating, because while they are breaking data pipelines constantly, it’s not their fault. As Convoy Head of Product, Data Platform, Chad Sanderson wrote in our blog , “The data in production tables are not intended for analytics or machine learning. He suggested : “Private vs. public methods.
Owing to the vitality of application software, businesses are actively seeking professionals with excellent technical expertise and a consumer-centric mindset to develop more practical application software systems that enhance customer experience. Database An automated data-keeping system is what a database management system (DBMS) is.
Looking for a position to test my skills in implementing data-centric solutions for complicated business challenges. Example 6: A well-qualified Cloud Engineer is looking for a position responsible for developing and maintaining automated CI/CD and deploying pipelines to support platform automation.
This blog outlines best practices from customers I have helped migrate from Elasticsearch to Rockset , reducing risk and avoiding common pitfalls. Elasticsearch has become ubiquitous as an index centric datastore for search and rose in tandem with the popularity of the internet and Web2.0.
In this blog, we’d like to give you a glimpse into some of the major developments in Picnic Tech in 2023. Combining efficient incident handling, establishing resilience by design, and strict adherence to SLOs are pivotal in ensuring our services remain resilient, reliable, stable, and user-centric. Join us and have a read!
The choice of tools and adopting the right methodologies becomes the drive for any business and in this the selection on the database technologies is very crucial. The second normal form ensures eliminating the repeating groups from the design and thus eliminating partial dependencies in the database relations if any.
This typically results in long-running ETL pipelines that cause decisions to be made on stale or old data. Business-Focused Operation Model: Teams can shed countless hours of managing long-running and complex ETL pipelines that do not scale. This noticeably saves time on copying and drastically reduces data storage costs.
We shall now move forward in this Java Tutorial for beginners blog by explaining each aspect of Java. . In serialization, an object is converted into a stream of bytes that can be stored in a file, transmitted through a network, or written to a database. Why Should You Learn Java? . There are more than 9.6
Best Certification Courses in Full-Stack Development In this blog, we will delve into the top 20 Full-Stack Developer courses that can help you embark on this exciting career journey or take your existing skills to new heights. Looking to explore more Full-Stack Web Development Courses with certification? Keep reading!
Best Certification Courses in Full-Stack Development In this blog, we will delve into the top 20 Full-Stack Developer courses that can help you embark on this exciting career journey or take your existing skills to new heights. Looking to explore more Full-Stack Web Development Courses with certification? Keep reading!
Storing events in a stream and connecting streams via stream processors provide a generic, data-centric, distributed application runtime that you can use to build ETL, event streaming applications, applications for recording metrics and anything else that has a real-time data requirement. Four pillars of event streaming. Avro or Protobuf ).
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content