
How to JOIN datasets in Polars … compared to Pandas.
Confessions of a Data Guy
APRIL 6, 2024
It’s been a while since I wrote about Polars on this blog, I’ve been remiss. appeared first on Confessions of a Data Guy.

Confessions of a Data Guy
APRIL 6, 2024
It’s been a while since I wrote about Polars on this blog, I’ve been remiss. appeared first on Confessions of a Data Guy.

Netflix Tech
NOVEMBER 12, 2024
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. For more information regarding this, refer to our previous blog.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.
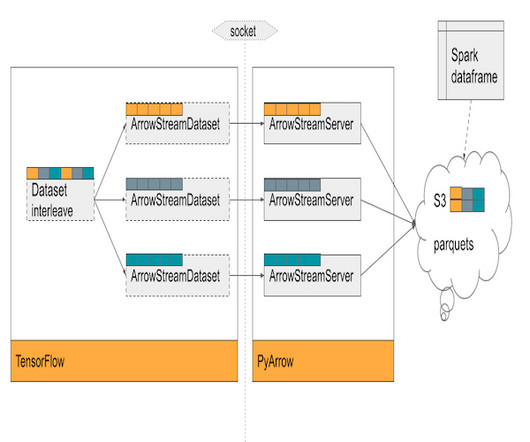
Yelp Engineering
JANUARY 21, 2025
These models handle large tabular datasets with small parameter spaces, requiring innovative data solutions. This blog post delves into our journey of optimizing training time using TensorFlow and Horovod, along with the development of ArrowStreamServer, our in-house library for low-latency data streaming and serving.

Knowledge Hut
APRIL 26, 2024
Datasets are the repository of information that is required to solve a particular type of problem. Datasets play a crucial role and are at the heart of all Machine Learning models. Datasets are often related to a particular type of problem and machine learning models can be built to solve those problems by learning from the data.
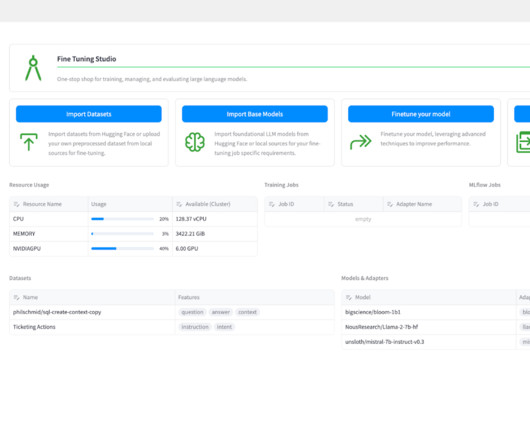
Cloudera
NOVEMBER 13, 2024
Fine Tuning Studio enables users to track the location of all datasets, models, and model adapters for training and evaluation. We can import this dataset on the Import Datasets page. The goal is to train an adapter for this base model that gives it better predictive capabilities for our specific dataset. Model Selection.

Knowledge Hut
NOVEMBER 28, 2023
Whether you are working on a personal project, learning the concepts, or working with datasets for your company, the primary focus is a data acquisition and data understanding. In this article, we will look at 31 different places to find free datasets for data science projects. What is a Data Science Dataset?

LinkedIn Engineering
JUNE 15, 2023
To remove this bottleneck, we built AvroTensorDataset , a TensorFlow dataset for reading, parsing, and processing Avro data. Today, we’re excited to open source this tool so that other Avro and Tensorflow users can use this dataset in their machine learning pipelines to get a large performance boost to their training workloads.

Expert insights. Personalized for you.








































Let's personalize your content