This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Most academic datasets pale in comparison to the complexity and volume of user interactions in real-world environments, where data is typically locked away inside companies due to privacy concerns and commercial value. Below is a brief survey of key datasets currently shaping the field. Yelp Open Dataset Contains 8.6M
Events Data + AI Summit Data + AI World Tour Data Intelligence Days Event Calendar Blog and Podcasts Databricks Blog Explore news, product announcements, and more Databricks Mosaic Research Blog Discover the latest in our Gen AI research Data Brew Podcast Let’s talk data! REGISTER Ready to get started?
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. For more information regarding this, refer to our previous blog.
Currently, he is focusing on content creation and writing technical blogs on machine learning and data science technologies. Abid Ali Awan ( @1abidaliawan ) is a certified data scientist professional who loves building machine learning models.
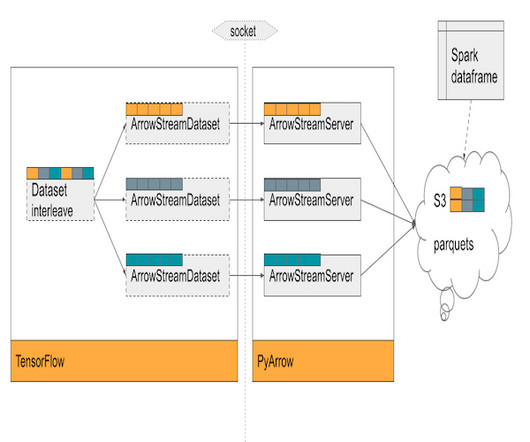
These models handle large tabular datasets with small parameter spaces, requiring innovative data solutions. This blog post delves into our journey of optimizing training time using TensorFlow and Horovod, along with the development of ArrowStreamServer, our in-house library for low-latency data streaming and serving.
fetchall() print("nMonth by affluency of passangers") print(segmented_result) Conclusion DuckDB is a high-performance OLAP database built for data professionals who need to explore and analyze large datasets efficiently.
Currently, he is focusing on content creation and writing technical blogs on machine learning and data science technologies. Abid Ali Awan ( @1abidaliawan ) is a certified data scientist professional who loves building machine learning models.
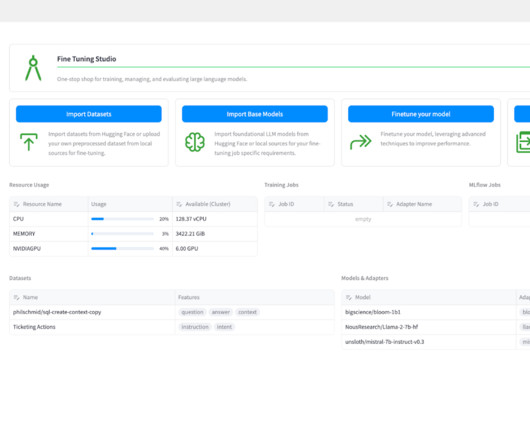
Fine Tuning Studio enables users to track the location of all datasets, models, and model adapters for training and evaluation. We can import this dataset on the Import Datasets page. The goal is to train an adapter for this base model that gives it better predictive capabilities for our specific dataset. Model Selection.
The first step is to work on cleaning it and eliminating the unwanted information in the dataset so that data analysts and data scientists can use it for analysis. Interact with the data scientists team and assist them in providing suitable datasets for analysis. That needs to be done because raw data is painful to read and work with.
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter AI Agents in Analytics Workflows: Too Early or Already Behind? Here, SQL stepped in.
In this blog, we will delve into an early stage in PAI implementation: data lineage. This took Meta multiple years to complete across our millions of disparate data assets, and well cover each of these more deeply in future blog posts: Inventorying involves collecting various code and data assets (e.g.,
Why it matters: Every dataset tells a story, but statistics helps you figure out which parts of that story are real. Calculate summary statistics and run relevant statistical tests on real-world datasets. You can start with clean data from sources like seaborns built-in datasets, then graduate to messier real-world data.
And, with largers datasets come better solutions. We will cover all such details in this blog. Use Athena in AWS to perform big data analysis on massively voluminous datasets without worrying about the underlying infrastructure or the cost associated with that infrastructure. Best suited for large unstructured datasets.
This blog introduces the concept of time series forecasting models in the most detailed form. The blog's last two parts cover various use cases of these models and projects related to time series analysis and forecasting problems. This blog will explore these use cases with practical time series forecasting model examples.
Part 1: 10 Hard Skills You Need Our Top 5 Free Course Recommendations --> Get the FREE ebook The Great Big Natural Language Processing Primer and The Complete Collection of Data Science Cheat Sheets along with the leading newsletter on Data Science, Machine Learning, AI & Analytics straight to your inbox.
Over the past four weeks, I took a break from blogging and LinkedIn to focus on building nao. A large international scientist collaboration released The Well : 2 massive datasets from physics simulation (15TB) to astronomical scientific data (100TB). They aim produce the same innovation as ImageNet produced for image recognition.
Read this blog if you are interested in exploring business intelligence projects examples that highlight different strategies for increasing business growth. One can use their dataset to understand how they work out the whole process of the supply chain of various products and their approach towards inventory management.
In this blog, you will find a list of interesting data mining projects that beginners and professionals can use. FAQs on Data Mining Projects 15 Top Data Mining Projects Ideas Data Mining involves understanding the given dataset thoroughly and concluding insightful inferences from it.
This blog will explore 15 exciting AWS DevOps project ideas that can help you gain hands-on experience with these powerful tools and services. You can use publicly available datasets like the Ames Housing or California Housing Prices datasets. Table of Contents Why Should You Practice AWS DevOps Projects?
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter Building a Custom PDF Parser with PyPDF and LangChain PDFs look simple — until you try to parse (..)
Currently, he is focusing on content creation and writing technical blogs on machine learning and data science technologies. Abid holds a Masters degree in technology management and a bachelors degree in telecommunication engineering.
This blog will explore the fundamentals of NLTK, its key features, and how to use it to perform various NLP tasks such as tokenization, stemming, and POS Tagging. As the name suggests, the NLTK WordNet Lemmatizer has learned its lemmatizing abilities from the WordNet dataset. We will use the movie reviews dataset from NLTK.
This blog covers all the steps to master data preparation with machine learning datasets. In building machine learning projects , the basics involve preparing datasets. In this blog, you will learn how to prepare data for machine learning projects. Imagine yourself as someone who is learning Jazz dance form.
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter 5 Error Handling Patterns in Python (Beyond Try-Except) Stop letting errors crash your app.
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter 7 Cool Python Projects to Automate the Boring Stuff Get more done in less time with these 7 beginner-friendly (..)
In this blog, we will go through the technical design and share some offline and online results for our LLM-based search relevance pipeline. Pin Text Representations Pins on Pinterest are rich multimedia entities that feature images, videos, and other contents, often linked to external webpages or blogs.
Bid goodbye to worries related to such problems with this blog, as it covers an appropriate and effective solution to the problem of limited data available for training machine learning and deep learning models. Ultimately, the most important countermeasure against overfitting is adding more and better quality data to the training dataset.
With the global data volume projected to surge from 120 zettabytes in 2023 to 181 zettabytes by 2025, PySpark's popularity is soaring as it is an essential tool for efficient large scale data processing and analyzing vast datasets. Resilient Distributed Datasets (RDDs) are the fundamental data structure in Apache Spark.
In this blog, we'll explore some exciting machine learning case studies that showcase the potential of this powerful emerging technology. This blog will explore in depth how machine learning applications are used for solving real-world problems. The study is based on the dataset of passengers aboard the Titanic when it sank in 1912.
In this blog post, we’ll explore what CDC is, why it’s important, and our journey of implementing Generic CDC solutions for all online databases at Pinterest. Change Data Capture (CDC) is a crucial technology that enables organizations to efficiently track and capture changes in their databases. What is Change Data Capture? or its affiliates.
And, out of these professions, we will focus on the data engineering job role in this blog and list out a comprehensive list of projects to help you prepare for the same. Project Idea : Leverage Spotify's public datasets or simulated user activity data to identify listening patterns.
The decrease in the accuracy of a deep learning model after a few epochs implies that the model is learning from the characteristics of the dataset and not considering the features. Epoch refers to the iteration where the complete dataset is passed forward and backward through the neural network only once.
Synthetic data works by leveraging models to create artificial datasets that reflect what someone might find organically (in some alternate reality where more data actually exists), and then using that new data to train their own models. But is synthetic data a long-term solution? Probably not.
This blog delves into the six distinct types of data quality dashboards, examining how each fulfills a specific role in ensuring data excellence. Similarly, data teams might struggle to determine actionable steps if the metrics do not highlight specific datasets, systems, or processes contributing to poor data quality.
In this multi-part blog series, we take you behind the scenes of our system that processes billions of impressions daily. Architecture Overview The first pivotal step in managing impressions begins with the creation of a Source-of-Truth (SOT) dataset.
If you are keen on learning how to apply DevOps for Machine Learning on Microsoft Azure, then this blog is for you. This Azure MLOps blog will dive deep into Azure MLOps capabilities and give you an in-depth insight into building a fully automated training and deployment pipeline on Azure.
These platforms facilitate collaboration by allowing multiple annotators to work on the same dataset. Key features include: Collaborative Annotation : Multiple annotators can label the same dataset simultaneously. GPT Prompt Generation : Creates numerous examples to balance datasets.
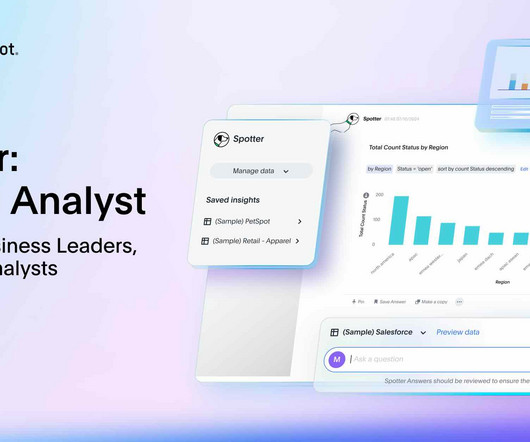
Level 2: Understanding your dataset To find connected insights in your business data, you need to first understand what data is contained in the dataset. Spotter quickly translates your datasets into business-friendly terminology so business users can confidently explore their data through natural language conversations.
ii) Targetted marketing through Customer Segmentation With user data for enhancing personalized song recommendations, Spotify uses this massive dataset for targeted ad campaigns and personalized service recommendations for its users. We have listed another music recommendations dataset for you to use for your projects: Dataset1.
The Medallion architecture is a framework that allows data engineers to build organized and analysis-ready datasets in a lakehouse environment. For instance, suppose a new dataset from an IoT device is meant to be ingested daily into the Bronze layer. How do you ensure data quality in every layer?
In this blog, you will find a detailed description of all you need to learn about probability and statistics for machine learning. The first one is to understand the dataset, and this is where you require knowledge of statistics. It will be of great help in deciding which algorithm will work for a given problem and dataset.
Datasets like Google Local, Amazon product reviews, MovieLens, Goodreads, NES, Librarything are preferable for creating recommendation engines using machine learning models. Dummy datasets like univariate time-series datasets, shampoo sales datasets , etc., for developing these kinds of projects. Let the FOMO kick in!
This blog presents the topmost useful machine learning applications in finance to help you understand how financial markets thrive by adopting AI and ML solutions. Also, remove all missing and NaN values from the dataset, as incomplete data is unnecessary. To start this machine learning project , download the Credit Risk Dataset.
Traditional databases may need help to provide the necessary performance when dealing with large datasets and complex queries. Data warehousing tools are designed to handle such scenarios efficiently, enabling faster query performance and analysis, even on massive datasets. Familiar SQL language for querying.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content