This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this blog, we will delve into an early stage in PAI implementation: data lineage. This took Meta multiple years to complete across our millions of disparate data assets, and well cover each of these more deeply in future blog posts: Inventorying involves collecting various code and data assets (e.g.,
Understanding DataSchema requires grasping schematization , which defines the logical structure and relationships of data assets, specifying field names, types, metadata, and policies. Creating a canonical representation for compliance tools. Accurate understanding of data, enabling the application of privacy safeguards at scale.
And for that future to be a reality, data teams must shift their attention to metadata, the new turf war for data. The need for unified metadata While open and distributed architectures offer many benefits, they come with their own set of challenges. Data teams actually need to unify the metadata. Open data is the future.
The blog highlights how moving from 6-character base-64 to 20-digit base-2 file distribution brings more distribution in S3 and reduces request failures. The blog is a good summary of how to use Snowflake QUERY_TAG to measure and monitor query performance. The blog post made me curious to understand DataFusion's internals.
To remove this bottleneck, we built AvroTensorDataset , a TensorFlow dataset for reading, parsing, and processing Avro data. Today, we’re excited to open source this tool so that other Avro and Tensorflow users can use this dataset in their machine learning pipelines to get a large performance boost to their training workloads.
In this blog, we will go through the technical design and share some offline and online results for our LLM-based search relevance pipeline. Pin Text Representations Pins on Pinterest are rich multimedia entities that feature images, videos, and other contents, often linked to external webpages or blogs.
This blog post expands on that insightful conversation, offering a critical look at Iceberg's potential and the hurdles organizations face when adopting it. In the mid-2000s, Hadoop emerged as a groundbreaking solution for processing massive datasets. If not handled correctly, managing this metadata can become a bottleneck.
Now With Actionable, Automatic, Data Quality Dashboards Imagine a tool that can point at any dataset, learn from your data, screen for typical data quality issues, and then automatically generate and perform powerful tests, analyzing and scoring your data to pinpoint issues before they snowball. Announcing DataOps Data Quality TestGen 3.0:
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. In this blog, we will discuss: What is the Open Table format (OTF)? These formats are transforming how organizations manage large datasets. Why should we use it?
In this multi-part blog series, we take you behind the scenes of our system that processes billions of impressions daily. Architecture Overview The first pivotal step in managing impressions begins with the creation of a Source-of-Truth (SOT) dataset.
In the previous blog post in this series, we walked through the steps for leveraging Deep Learning in your Cloudera Machine Learning (CML) projects. To try and predict this, an extensive dataset including anonymised details on the individual loanee and their historical credit history are included. Get the Dataset. Introduction.
In this blog post, we will ingest a real world dataset into Ozone, create a Hive table on top of it and analyze the data to study the correlation between new vaccinations and new cases per country using a Spark ML Jupyter notebook in CML. Learn more about the impacts of global data sharing in this blog, The Ethics of Data Exchange.
The Grab blog delights me since I have tried to do this many times. A cross-encoder teacher model, fine-tuned on human-labeled data and enriched Pin metadata, was distilled into a lightweight student model using semi-supervised learning over billions of impressions. Kudos to the Grab team for building a docs-as-code system.
The data architecture layer is one such area where growing datasets have pushed the limits of scalability and performance. The data explosion has to be met with new solutions, that’s why we are excited to introduce the next generation table format for large scale analytic datasets within Cloudera Data Platform (CDP) – Apache Iceberg.
Summary The majority of blog posts and presentations about data engineering and analytics assume that the consumers of those efforts are internal business users accessing an environment controlled by the business. Atlan is the metadata hub for your data ecosystem. Atlan is the metadata hub for your data ecosystem.
In this blog post, we’ll explore key strategies that data teams should adopt to prepare for the year ahead. Embrace Version Control for Data and Code: Just as software developers use version control for code, DataOps involves tracking versions of datasets and data transformation scripts.
This is part of our series of blog posts on recent enhancements to Impala. Apache Impala is synonymous with high-performance processing of extremely large datasets, but what if our data isn’t huge? So clearly Impala is used extensively with datasets both small and large. Metadata Caching. More on this below.
In this blog post, we’ll explore what CDC is, why it’s important, and our journey of implementing Generic CDC solutions for all online databases at Pinterest. Kafka: Kafka stores metadata about connectors in several internal topics that are not exposed to end users. What is Change Data Capture? or its affiliates.
mock Generate or validate mock datasets. All the above commands are very likely to be described in separate future blog posts, but right now let’s focus on the dataflow sample command. " ) COMMENT "Example dataset brought to you by Dataflow. -v, --verbose Enables verbose mode. version Show the version and exit.
In this blog, we’ll highlight the key CDP aspects that provide data governance and lineage and show how they can be extended to incorporate metadata for non-CDP systems from across the enterprise. Extending Atlas’ metadata model. The example 1_typedef-server.json describes the server typedef used in this blog. .
How to analyze dataset performance and schema changes in Databand Eric Jones 2022-09-12 13:06:42 “Why did my dataset schema change?” Databand helps fix this problem by capturing the metadata from your datasets and then alerting you when dataset operations change unexpectedly. Yeah, we hear this question a lot too.
In this blog post, we’ll explore key strategies that data teams should adopt to prepare for the year ahead. Embrace Version Control for Data and Code: Just as software developers use version control for code, DataOps involves tracking versions of datasets and data transformation scripts.
The blog highlights the advantages of GNN over traditional machine learning models, which struggle to discern relationships between various entities, such as users and restaurants, and edges, such as order. The author highlights Paimon’s consistency model by examining the metadata model.
Change Management Given that useful datasets become widely used and derived in ways that results in large and complex directed acyclic graphs (DAGs) of dependencies, altering logic or source data tends to break and/or invalidate downstream constructs. Upstream changes will inevitably break and invalidate downstream entities in intricate ways.
In this blog post, we compare Cloudera Data Warehouse (CDW) on Cloudera Data Platform (CDP) using Apache Hive-LLAP to Microsoft HDInsight (also powered by Apache Hive-LLAP) on Azure using the TPC-DS 2.9 A TPC-DS 10TB dataset was generated in ACID ORC format and stored on the ADLS Gen 2 cloud storage. benchmark.
This is part 2 in this blog series. This blog series follows the manufacturing, operations and sales data for a connected vehicle manufacturer as the data goes through stages and transformations typically experienced in a large manufacturing company on the leading edge of current technology.
In a previous blog post on CDW performance, we compared Azure HDInsight to CDW. In this blog post, we compare Cloudera Data Warehouse (CDW) on Cloudera Data Platform (CDP) using Apache Hive-LLAP to EMR 6.0 (also powered by Apache Hive-LLAP) on Amazon using the TPC-DS 2.9 More on this later in the blog.
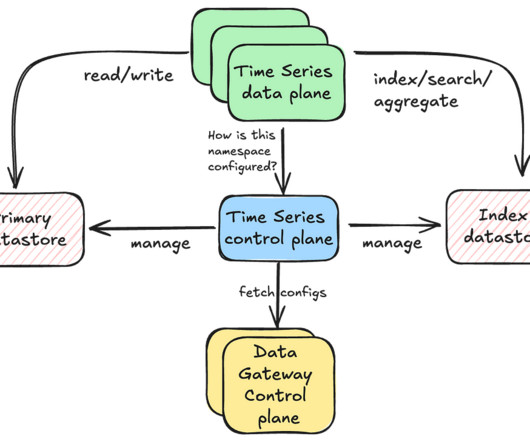
In previous blog posts, we introduced the Key-Value Data Abstraction Layer and the Data Gateway Platform , both of which are integral to Netflix’s data architecture. Configurability : TimeSeries offers a range of tunable options for each dataset, providing the flexibility needed to accommodate a wide array of use cases.
Catalog Integration: Our newly developed Catalog Integration feature allows you to seamlessly plug Snowflake into other Iceberg catalogs tracking table metadata. In this blog post, we’ll dive into the details of these features and the benefits for customers. In addition to Iceberg External Tables, we introduced Native Iceberg Tables.
In Part 2 of our blog series, we described how we were able to integrate Ray(™) into our existing ML infrastructure. In this blog post, we will discuss a second type of popular application of Ray(™) at Pinterest: offline batch inference of ML models. Dataset execution is pipelined so that multiple execution stages can run in parallel.
Overview This blog post describes support for materialized views for the Iceberg table format. Apache Iceberg is a high-performance open table format for petabyte-scale analytic datasets. The snapshotId of the source tables involved in the materialized view are also maintained in the metadata.
In this blog post, we will introduce speech and music detection as an enabling technology for a variety of audio applications in Film & TV, as well as introduce our speech and music activity detection (SMAD) system which we recently published as a journal article in EURASIP Journal on Audio, Speech, and Music Processing.
message Item ( Bytes key, Bytes value, Metadatametadata, Integer chunk ) Database Agnostic Abstraction The KV abstraction is designed to hide the implementation details of the underlying database, offering a consistent interface to application developers regardless of the optimal storage system for that use case. . "persistence_configuration":[
For example, writing a Spark dataset to Ozone or launching a DDL query in Hive that points to a location in Ozone. I’ve chosen those names because I’ll be using an easy method for generating and writing TPC-DS datasets, along with creating their corresponding Hive tables. Create a dataset from the customer table. With CDP 7.1.4
Sophisticated data practitioners and business analysts want access to new datasets that can help optimize their work and transform whole business functions. Traditionally, it all starts with onboarding and transforming the datasets and then building analytical models that create business value, which can take weeks or months.
Fast News ⚡️ End-to-end data lineage in AWS — AWS announced DataZone to bring lineage to your data assets , from the picture it can mixes datasets (?), It provides abstractions and tools for the translation of lakehouse table format metadata. I'm not sure I'm happy to see this on Atlassian blog.
Iceberg is a next-generation, cloud-native table format designed to be open and scalable to petabyte datasets. With innovations like hidden partitioning and metadata stored at the file level, Iceberg makes querying on very large data sets faster, while also making changes to data easier and safer.
Our cutting-edge Shared data experience (SDX) service provides a unified control plane for common security, governance and metadata management on all structured and unstructured data. The post Cloudera Named a Visionary in the Gartner MQ for Cloud DBMS appeared first on Cloudera Blog. Unlike software, ML models need continuous tuning.
It is a replicated, highly-available service that is responsible for managing the metadata for all objects stored in Ozone. In this blog post, we will highlight the work done recently to improve the performance of Ozone Manager to scale to exabytes of data. The hardware specifications are included at the end of this blog.
Therefore, alleviating the need to use different connectors, exotic and poorly maintained APIs, and other use-case specific workarounds to work with your datasets. . Iceberg is designed to be open and engine agnostic allowing datasets to be shared. 3: Open Performance.
Read this blog to understand everything about AWS Glue that makes it one of the most popular data integration solutions in the industry. Then, Glue writes the job's metadata into the embedded AWS Glue Data Catalog. For analyzing huge datasets, they want to employ familiar Python primitive types. billion by 2026?
In the rest of this blog, we will a) touch on the complexity of Netflix cloud landscape, b) discuss lineage design goals, ingestion architecture and the corresponding data model, c) share the challenges we faced and the learnings we picked up along the way, and d) close it out with “what’s next” on this journey. push or pull.
Once a dataset has been located, how does Amundsen simplify the process of accessing that data for analysis or further processing? Links Amundsen Data Council Presentation Strata Presentation Blog Post Lyft Airflow Podcast.__init__ Links Amundsen Data Council Presentation Strata Presentation Blog Post Lyft Airflow Podcast.__init__
The platform converges data cataloging, data ingestion, data profiling, data tagging, data discovery, and data exploration into a unified platform, driven by metadata. Modak Nabu reliably curates datasets for any line of business and personas, from business analysts to data scientists. Knowledge Graphs for the Business.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content