This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. In this blog, we will discuss: What is the Open Table format (OTF)? These formats are transforming how organizations manage large datasets. Why should we use it?
It is a critical and powerful tool for scalable discovery of relevant data and data flows, which supports privacy controls across Metas systems. In this blog, we will delve into an early stage in PAI implementation: data lineage. Data lineage enables us to efficiently navigate these assets and protect user data.
Datasets are the repository of information that is required to solve a particular type of problem. Datasets play a crucial role and are at the heart of all Machine Learning models. Datasets are often related to a particular type of problem and machine learning models can be built to solve those problems by learning from the data.
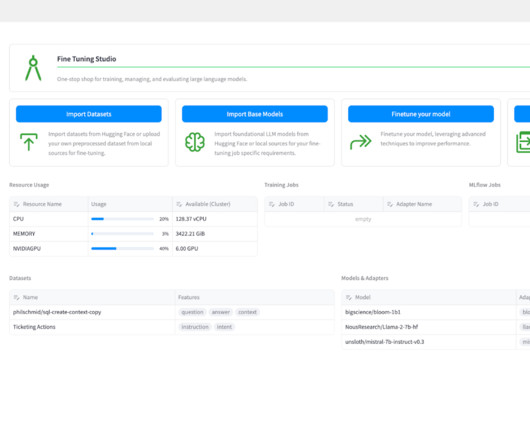
Fine Tuning Studio enables users to track the location of all datasets, models, and model adapters for training and evaluation. The goal is to fine tune a small, cost-effective model that , based on customer input, can extract an appropriate “action” (think API call) that the downstream system should take for the customer.
Over the past four weeks, I took a break from blogging and LinkedIn to focus on building nao. AI companies are aiming for the moon—AGI—promising it will arrive once OpenAI develops a system capable of generating at least $100 billion in profits. Meanwhile, the AI landscape remains unpredictable.
Whether you are working on a personal project, learning the concepts, or working with datasets for your company, the primary focus is a data acquisition and data understanding. In this article, we will look at 31 different places to find free datasets for data science projects. What is a Data Science Dataset?
Summary The majority of blog posts and presentations about data engineering and analytics assume that the consumers of those efforts are internal business users accessing an environment controlled by the business. The biggest challenge with modern data systems is understanding what data you have, where it is located, and who is using it.
The vast tapestry of data types spanning structured, semi-structured, and unstructured data means data professionals need to be proficient with various data formats such as ORC, Parquet, Avro, CSV, and Apache Iceberg tables, to cover the ever growing spectrum of datasets – be they images, videos, sensor data, or other type of media content.
In this blog learn how we automated column-level drift detection in batch datasets at Uber scale, reducing the median time to detect issues in critical datasets by 5X. Data quality is of paramount importance at Uber, powering critical decisions and features.
Building a large scale unsupervised model anomaly detection system — Part 1 Distributed Profiling of Model Inference Logs By Anindya Saha , Han Wang , Rajeev Prabhakar Introduction LyftLearn is Lyft’s ML Platform. In a previous blog post , we explored the architecture and challenges of the platform.
I found the blog to be a fresh take on the skill in demand by layoff datasets. DeepSeek continues to impact the Data and AI landscape with its recent open-source tools, such as Fire-Flyer File System (3FS) and smallpond. The blog provides an excellent analysis of smallpond compared to Spark and Daft.
A little over a year ago, we shared a blog post about our journey to enhance customers meal planning experience with personalized recipe recommendations. We explained how a system that learns from your tastes and habits could solve this issue, ultimately making the daily task of choosing meals both effortless and inspiring.
It requires a state-of-the-art system that can track and process these impressions while maintaining a detailed history of each profiles exposure. In this multi-part blog series, we take you behind the scenes of our system that processes billions of impressions daily.
In this blog, we will go through the technical design and share some offline and online results for our LLM-based search relevance pipeline. Pin Text Representations Pins on Pinterest are rich multimedia entities that feature images, videos, and other contents, often linked to external webpages or blogs.
The blog highlights how moving from 6-character base-64 to 20-digit base-2 file distribution brings more distribution in S3 and reduces request failures. The blog is a good summary of how to use Snowflake QUERY_TAG to measure and monitor query performance. The blog post made me curious to understand DataFusion's internals.
This foundational layer is a repository for various data types, from transaction logs and sensor data to social media feeds and system logs. The Medallion architecture is a framework that allows data engineers to build organized and analysis-ready datasets in a lakehouse environment. How do you ensure data quality in every layer?
Meta’s vast and diverse systems make it particularly challenging to comprehend its structure, meaning, and context at scale. We discovered that a flexible and incremental approach was necessary to onboard the wide variety of systems and languages used in building Metas products. We believe that privacy drives product innovation.
In recent years, while managing Pinterests EC2 infrastructure, particularly for our essential online storage systems, we identified a significant challenge: the lack of clear insights into EC2s network performance and its direct impact on our applications reliability and performance. 4xl with up to 12.5
The article summarizes the recent macro trends in AI and data engineering, focusing on Vibe coding, human-in-the-loop system design, and rapid simplification of developer tooling. The Grab blog delights me since I have tried to do this many times. Kudos to the Grab team for building a docs-as-code system.
In this blog post, we’ll explore what CDC is, why it’s important, and our journey of implementing Generic CDC solutions for all online databases at Pinterest. This is crucial for applications that require up-to-date information, such as fraud detection systems or recommendation engines. What is Change Data Capture?
In this blog, well explore Building an ETL Pipeline with Snowpark by simulating a scenario where commerce data flows through distinct data layersRAW, SILVER, and GOLDEN.These tables form the foundation for insightful analytics and robust business intelligence. Built clean, enriched datasets in the SILVER layer.
link] Intuit: Revolutionizing Knowledge Discovery with GenAI to Transform Document Management Intuit writes about using a dual-loop system to build a GenAI-powered pipeline to improve knowledge discovery in its technical documentation. years of manual effort!!! Check out the full report for more insights and DataOps trends!
Building a large scale unsupervised model anomaly detection system — Part 2 Building ML Models with Observability at Scale By Rajeev Prabhakar , Han Wang , Anindya Saha Photo by Octavian Rosca on Unsplash In our previous blog we discussed the different challenges we faced for model monitoring and our strategy for addressing some of these problems.
A “Knowledge Management System” (KMS) allows businesses to collate this information in one place, but not necessarily to search through it accurately. Ultimately, Ollama and Cloudera provide enterprise-grade access to localized LLM models, to scale GenAI applications and build robust Knowledge Management systems.
In this blog post, we’ll explore fundamental concepts, intermediate strategies, and cutting-edge techniques that are shaping the future of data engineering. Filling in missing values could involve leveraging other company data sources or even third-party datasets.
Manager, Engineering | At Pinterest, we operate a large-scale online machine learning inference system, where feature caching plays a critical role to achieve optimal efficiency. Background Recommender systems are fundamental to Pinterest’s mission to inspire users to create a life they love.
MoEs necessitate less compute for pre-training compared to dense models, facilitating the scaling of model and dataset size within similar computational budgets. I found the product blog from QuantumBlack gives a view of data quality in unstructured data. The system design is an excellent reminder of thinking from a user's perspective.
By learning the details of smaller datasets, they better balance task-specific performance and resource efficiency. It is seamlessly integrated across Meta’s platforms, increasing user access to AI insights, and leverages a larger dataset to enhance its capacity to handle complex tasks. What are Small language models?
However, due to the absence of a control group in these countries, we adopt a synthetic control framework ( blog post ) to estimate the counterfactual scenario. Before starting any math, we need to ensure a high quality historical dataset. Data quality plays a huge role in this work.
In this blog post, we will ingest a real world dataset into Ozone, create a Hive table on top of it and analyze the data to study the correlation between new vaccinations and new cases per country using a Spark ML Jupyter notebook in CML. Learn more about the impacts of global data sharing in this blog, The Ethics of Data Exchange.
The blog highlights the advantages of GNN over traditional machine learning models, which struggle to discern relationships between various entities, such as users and restaurants, and edges, such as order. Canva writes about the evolution of experimentation system design and the current state of the function.
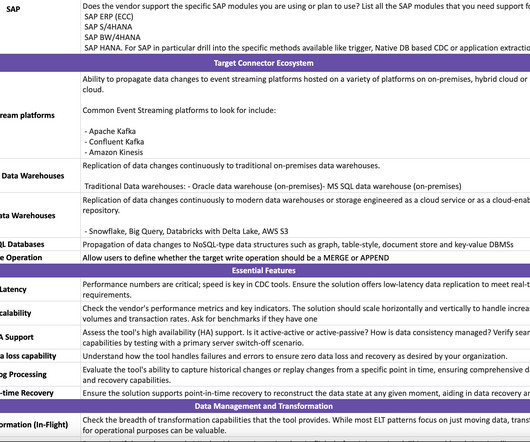
CDC Evaluation Guide Google Sheet Link: [link] CDC Evaluation Guide Github Link: [link] Change Data Capture (CDC) is a powerful technology in data engineering that allows for continuously capturing changes (inserts, updates, and deletes) made to source systems. Impacts source system performance during query execution.
This blog post expands on that insightful conversation, offering a critical look at Iceberg's potential and the hurdles organizations face when adopting it. In the mid-2000s, Hadoop emerged as a groundbreaking solution for processing massive datasets. Cost: Reducing storage and processing expenses. Speed: Accelerating data insights.
In this blog post, we’ll explore key strategies for future-proofing your data pipelines. These platforms enable scalable and distributed data processing, allowing data teams to efficiently handle massive datasets. APIs facilitate communication between different systems, allowing data to flow seamlessly across platforms.
This leads to systemic, stupid errors that waste hours. Change Management Given that useful datasets become widely used and derived in ways that results in large and complex directed acyclic graphs (DAGs) of dependencies, altering logic or source data tends to break and/or invalidate downstream constructs.
The blog is an excellent summarization of the common patterns emerging in GenAI platforms. Switching from Apache Spark to Ray improves compact 12X larger datasets than Apache Spark, improves cost efficiency by 91%, and processes 13X more data per hour. Swiggy recently wrote about its internal platform, Hermes, a text-to-SQL solution.
Besides simply looking for email addresses associated with spam, these systems notice slight indications of spam emails, like bad grammar and spelling, urgency, financial language, and so on. Such dialog systems are the hardest to pull off and are considered an unsolved problem in NLP. Language detection. Question answering.
transformers) became standardized, ML engineers started to show a growing appetite to iterate on datasets. While such dataset iterations can yield significant gains, we observed that only a handful of such experiments were conducted and productionized in the last six months. As model architecture building blocks (e.g.
In this blog post, we’ll explore key strategies that data teams should adopt to prepare for the year ahead. On average, engineers spend over half of their time maintaining existing systems rather than developing new solutions. Leveraging cloud-based platforms and distributed computing can help handle large datasets efficiently.
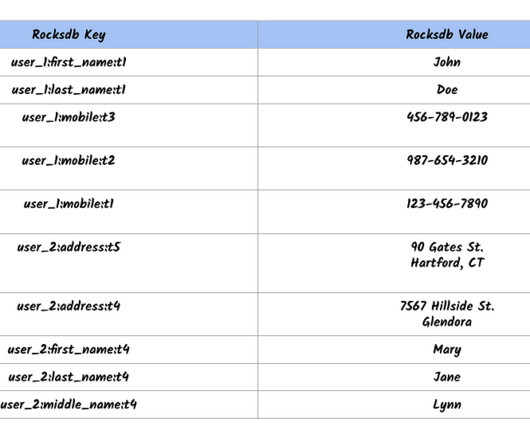
In 2020, anticipating the growing needs of the business and to simplify our storage offerings, we decided to consolidate our different key-value systems in the company into a single unified service called KVStore. Maintaining these disparate systems and building common functionality among them was adding a huge overhead to the teams.
Then, based on this information from the sample, defect or abnormality the rate for whole dataset is considered. Hypothesis testing is a part of inferential statistics which uses data from a sample to analyze results about whole dataset or population. It offers various blogs based on above mentioned technology in alphabetical order.
The new DeepSeek AI study paper goes into great detail about the system’s architecture, how it is trained, how it is optimized, and how it can be used in the real world. This blog will break down the research paper’s key aspects, helping you understand how DeepSeek AI works and why it stands out in the AI landscape.
The data architecture layer is one such area where growing datasets have pushed the limits of scalability and performance. The data explosion has to be met with new solutions, that’s why we are excited to introduce the next generation table format for large scale analytic datasets within Cloudera Data Platform (CDP) – Apache Iceberg.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content