This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In your blog post that explains the design decisions for how Timescale is implemented you call out the fact that the inserted data is largely append only which simplifies the index management. Is timescale compatible with systems such as Amazon RDS or GoogleCloud SQL? What impact has the 10.0
A scalable, distributed, peer-to-peer NoSQL database, Scylla is a perfect fit for consuming the variety, velocity, and volume of data (often time-series) coming directly from users, devices, and sensors spread across geographic locations. We use the GoogleCloud API to automate the deployment of a ScyllaDB cluster. Ansible 2.3.
In this blog, we will talk about the future of database management. Get ready to discover fascinating insights, uncover mind-boggling facts, and explore the transformative potential of cutting-edge technologies like blockchain, cloud computing, and artificial intelligence. Examples include Amazon DynamoDB and GoogleCloud Datastore.
This blog is your comprehensive guide to Google BigQuery, its architecture, and a beginner-friendly tutorial on how to use Google BigQuery for your data warehousing activities. This blog presents a detailed overview of Google BigQuery and its architecture. What is Google BigQuery Used for? Search no more!
Dazu gesellen sich Datenbanken wie der PostgreSQL, Maria DB oder Microsoft SQL Server sowie CosmosDB oder einfachere Cloud-Speicher wie der Microsoft Blobstorage, Amazon S3 oder GoogleCloud Storage. Beispiele für verbreitete NoSQL-Datenbanken sind MongoDB, CouchDB, Cassandra oder Neo4J.
These tools include both open-source and commercial options, as well as offerings from major cloud providers like AWS, Azure, and GoogleCloud. Database management: Data engineers should be proficient in storing and managing data and working with different databases, including relational and NoSQL databases.
Are you confused about choosing the best cloud platform for your next data engineering project ? AWS vs. GCP blog compares the two major cloud platforms to help you choose the best one. So, are you ready to explore the differences between two cloud giants, AWS vs. googlecloud? Let’s get started!
Databases and Data Warehousing: Engineers need in-depth knowledge of SQL (88%) and NoSQL databases (71%), as well as data warehousing solutions like Hadoop (61%). Cloud Platforms: Understanding cloud services from providers like AWS (mentioned in 80% of job postings), Azure (66%), and GoogleCloud (56%) is crucial.
Databases and Data Warehousing: Engineers need in-depth knowledge of SQL (88%) and NoSQL databases (71%), as well as data warehousing solutions like Hadoop (61%). Cloud Platforms: Understanding cloud services from providers like AWS (mentioned in 80% of job postings), Azure (66%), and GoogleCloud (56%) is crucial.
In this respect, the purpose of the blog is to explain what is a data engineer , describe their duties to know the context that uses data, and explain why the role of a data engineer is central. Databases: Knowledgeable about SQL and NoSQL databases. What Does a Data Engineer Do?
HBase is a distributed, scalable NoSQL database that enterprises use to power applications that need random, real time read/write access to semi-structured data. Testing also conducted on Hewlett Packard Enterprise servers and GoogleCloud Platform . Intel does not guarantee any costs or cost reduction.
He also has more than 10 years of experience in big data, being among the few data engineers to work on Hadoop Big Data Analytics prior to the adoption of public cloud providers like AWS, Azure, and GoogleCloud Platform. Deepak regularly shares blog content and similar advice on LinkedIn.
Before Confluent Cloud was announced , a managed service for Apache Kafka did not exist. This blog post goes over: The complexities that users will run into when self-managing Apache Kafka on the cloud and how users can benefit from building event streaming applications with a fully managed service for Apache Kafka.
Whether you are a newbie or an experienced individual, if you want to explore more about the concepts of MLOPS, then you just click on the right blog. But before we begin, Let’s have a look at what we will be covering in this blog: What is MLOPS? Why do we need MLOPS? Components of MLOPS MLOPS Roadmap for 2024 What is MLOPS?
market share, while all of its rivals combined, Microsoft Azure (29.4%), GoogleCloud (3.0%), and IBM (2.6%), do not even reach that percentage. That shows how much AWS has to offer, and you must know about it if you’re a cloud computing enthusiast. I will explore the top 10 AWS applications and their use cases in this blog.
For a data engineer career, you must have knowledge of data storage and processing technologies like Hadoop, Spark, and NoSQL databases. Cloud Data Engineer A cloud data engineer designs, builds, and maintains data infrastructures to run on cloud platforms such as AWS or GoogleCloud.
This activity is rather critical of migrating data, extending cloud and on-premises deployments, and getting data ready for analytics. In this all-encompassing tutorial blog, we are going to give a detailed explanation of the Copy activity with special attention to datastores, file type, and options. can be ingested in Azure.
Cloud Services Providers Platforms As companies are gradually becoming more inclined towards investing in cloud computing for storing their data instead of bulky hardware systems, engineers who can work on cloud computing tools are in demand. It nicely supports Hybrid Cloud Space. Subscription plans are not so flexible.
popular SQL and NoSQL database management systems including Oracle, SQL Server, Postgres, MySQL, MongoDB, Cassandra, and more; cloud storage services — Amazon S3, Azure Blob, and GoogleCloud Storage; message brokers such as ActiveMQ, IBM MQ, and RabbitMQ; Big Data processing systems like Hadoop ; and.
This blog helps you understand more about the data engineer salary in US. After the inception of databases like Hadoop and NoSQL, there's a constant rise in the requirement for processing unstructured or semi-structured data. Hope this blog gives you a clear understanding of data engineer salary in USA.
Students learn skills to build data pipelines, query data lakes and develop cloud-native applications using services from AWS, Azure and GoogleCloud. Students work with SQL, NoSQL databases, Hadoop ecosystem, Spark, Kafka etc.
Platforms like AWS Lambda, Azure Functions, and GoogleCloud Functions are popular choices. To stay updated on these trends, it’s essential to follow industry blogs, attend relevant webinars and conferences, participate in online communities and forums, and continuously explore and experiment with new technologies and tools.
Chad writes on data management, contracts, and products on his Substack blog and serves as an advisor and investor to several startups. She regularly contributes to IBM’s Journey to AI blog and shares her advice on LinkedIn around data strategy, data science, women in AI, data and analytics, data governance, and artificial intelligence.
You should also know DBMS and basics of SQL(Structured Query Language) and NoSQL databases because databases play an important role in storing and retrieving data in backend development. Take your first steps with a startup application such as a simple blog, an API, or a simple e-commerce application.
This blog will walk through the most popular and fascinating open source big data projects. Apache Beam Source: GoogleCloud Platform Apache Beam is an advanced unified programming open-source model launched in 2016. Furthermore, Cassandra is a NoSQL database in which all nodes are peers, rather than master-slave architecture.
This blog will take you through a relatively new career title in the data industry — AI Engineer. A data engineer is expected to be adept at using ETL (Extract, Transform and Load) tools and be able to work with both SQL and NoSQL databases. You can consider many other high-paying career options as a data enthusiast.
Cloud Computing : Knowledge of cloud platforms like AWS, Azure, or GoogleCloud is essential as these are used by many organizations to deploy their big data solutions. Develop working knowledge of NoSQL & Big Data using MongoDB, Cassandra, Cloudant, Hadoop, Apache Spark, Spark SQL, Spark ML, and Spark Streaming 18.
Translating the commands from source to target can be tricky especially if you’re capturing changes to a SQL database and reflecting them in a NoSQL database, as the way commands are written are different. The system needs to deal with transactional systems where changes are only applied on commit.
This blog is your one-stop solution for the top 100+ Data Engineer Interview Questions and Answers. In this blog, we have collated the frequently asked data engineer interview questions based on tools and technologies that are highly useful for a data engineer in the Big Data industry. that leverage big data analytics and tools.
As a disclaimer, this may not quite make sense in a corporate context, but since this is my blog, I'll do what I want. FAQ and remarks Why do you use GoogleCloud? However over the years I've met people working at these companies so I might have a few biais. I hope you'll enjoy this Data News Summer Edition.
We'll be publishing more posts in the series in the near future, so subscribe to our blog so you don't miss them! Most were cloud native ( Amazon Kinesis , GoogleCloud Dataflow) or were commercially adapted for the cloud ( Kafka ⇒ Confluent, Spark ⇒ Databricks). They were unaffordable for most companies.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














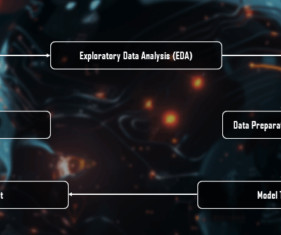















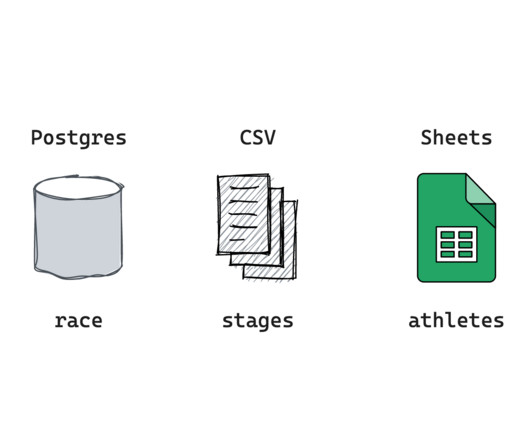







Let's personalize your content