This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As Uber’s business grew, we scaled our Apache Hadoop (referred to as ‘Hadoop’ in this article) deployment to 21000+ hosts in 5 years, to support the various analytical and machine learning use cases.
In this episode of Unapologetically Technical, I interview Adrian Woodhead, a distinguished software engineer at Human and a true trailblazer in the European Hadoop ecosystem. ” Dont forget to subscribe to my YouTube channel to get the latest on Unapologetically Technical!
But is it truly revolutionary, or is it destined to repeat the pitfalls of past solutions like Hadoop? Danny authored a thought-provoking article comparing Iceberg to Hadoop , not on a purely technical level, but in terms of their hype cycles, implementation challenges, and the surrounding ecosystems.
With the evolution of storage formats like Apache Parquet and Apache ORC and query engines like Presto and Apache Impala , the Hadoop ecosystem has the potential to become a general-purpose, unified serving layer for workloads that can tolerate latencies … The post Hudi: Uber Engineering’s Incremental Processing Framework on Apache Hadoop appeared (..)
For organizations considering moving from a legacy data warehouse to Snowflake, looking to learn more about how the AI Data Cloud can support legacy Hadoop use cases, or assessing new options if your current cloud data warehouse just isn’t scaling anymore, it helps to see how others have done it.
Ready to boost your Hadoop Data Lake security on GCP? Our latest blog dives into enabling security for Uber’s modernized batch data lake on Google Cloud Storage!
Prior the introduction of CDP Public Cloud, many organizations that wanted to leverage CDH, HDP or any other on-prem Hadoop runtime in the public cloud had to deploy the platform in a lift-and-shift fashion, commonly known as “Hadoop-on-IaaS” or simply the IaaS model. Introduction.
Ozone natively provides Amazon S3 and Hadoop Filesystem compatible endpoints in addition to its own native object store API endpoint and is designed to work seamlessly with enterprise scale data warehousing, machine learning and streaming workloads. Ozone Namespace Overview. STORED AS TEXTFILE. and Cloudera Manager version 7.4.4.
Apache Ozone is compatible with Amazon S3 and Hadoop FileSystem protocols and provides bucket layouts that are optimized for both Object Store and File system semantics. This blog post is intended to provide guidance to Ozone administrators and application developers on the optimal usage of the bucket layouts for different applications.
Hadoop initially led the way with Big Data and distributed computing on-premise to finally land on Modern Data Stack — in the cloud — with a data warehouse at the center. In order to understand today's data engineering I think that this is important to at least know Hadoop concepts and context and computer science basics.
The first time that I really became familiar with this term was at Hadoop World in New York City some ten or so years ago. But, let’s make one thing clear – we are no longer that Hadoop company. But, What Happened to Hadoop? This was the gold rush of the 21st century, except the gold was data. We hope to see you there.
Apache Ozone is a distributed object store built on top of Hadoop Distributed Data Store service. In this blog, we will look into the Apache Ozone metadata and the related Apache Ratis metadata in detail and give best practices for different scenarios. . For details of Ozone Security, please refer to our early blog [1].
That's where Hadoop comes into the picture. Hadoop is a popular open-source framework that stores and processes large datasets in a distributed manner. Organizations are increasingly interested in Hadoop to gain insights and a competitive advantage from their massive datasets. Why Are Hadoop Projects So Important?
In this post, we focus on how we enhanced and extended Monarch , Pinterest’s Hadoop based batch processing system, with FGAC capabilities. In the next section, we elaborate how we integrated CVS into Hadoop to provide FGAC capabilities for our Big Data platform. QueryBook uses OAuth to authenticate users.
This blog post describes the advantages of real-time ETL and how it increases the value gained from Snowflake implementations. If you have Snowflake or are considering it, now is the time to think about your ETL for Snowflake.
Let’s further explore the impact of data in this industry as we count down the top 5 financial services blog posts of 2022. #5 Many institutions need to access key customer data from mainframe applications and integrate that data with Hadoop and Spark to power advanced insights. But what does that look like in practice?
It was designed as a native object store to provide extreme scale, performance, and reliability to handle multiple analytics workloads using either S3 API or the traditional Hadoop API. In this blog post, we will talk about a single Ozone cluster with the capabilities of both Hadoop Core File System (HCFS) and Object Store (like Amazon S3).
In this blog post, we will discuss such technologies. If you pursue the MSc big data technologies course, you will be able to specialize in topics such as Big Data Analytics, Business Analytics, Machine Learning, Hadoop and Spark technologies, Cloud Systems etc. It is especially true in the world of big data.
In this blog post, we will look into benchmark test results measuring the performance of Apache Hadoop Teragen and a directory/file rename operation with Apache Ozone (native o3fs) vs. Ozone S3 API*. We ran Apache Hadoop Teragen benchmark tests in a conventional Hadoop stack consisting of YARN and HDFS side by side with Apache Ozone.
How do you anticipate the evolving hardware, patterns, and tools for processing data to influence the types of storage formats that maintain or grow their popularity? How do you anticipate the evolving hardware, patterns, and tools for processing data to influence the types of storage formats that maintain or grow their popularity?
Thank you for every recommendation you do about the blog or the Data News. In between the Hadoop era, the modern data stack and the machine learning revolution everyone—but me—waits for. Data Engineering job market in Stockholm — Alexander shared on a personal blog his job research in Sweden.
Is there any utility in data vault modeling in a data lake context (S3, Hadoop, etc.)? Is there any utility in data vault modeling in a data lake context (S3, Hadoop, etc.)? How has the era of data lakes, unstructured/semi-structured data, and non-relational storage engines impacted the state of the art in data modeling?
In your blog post that explains the design decisions for how Timescale is implemented you call out the fact that the inserted data is largely append only which simplifies the index management. The landscape of time series databases is extensive and oftentimes difficult to navigate.
In this blog, we will discuss: What is the Open Table format (OTF)? The Hive format helped structure and partition data within the Hadoop ecosystem, but it had limitations in terms of flexibility and performance. Why should we use it? A Brief History of OTF A comparative study between the major OTFs. What is an Open Table Format?
In this blog post I will introduce a new feature that provides this behavior called the Ranger Resource Mapping Service (RMS). This means many manually implemented Ranger HDFS policies, Hadoop ACLs, or POSIX permissions created solely for this purpose can now be removed, if desired. The RMS was included in CDP Private Cloud Base 7.1.4
This blog post provides CDH users with a quick overview of Ranger as a Sentry replacement for Hadoop SQL policies in CDP. Apache Sentry is a role-based authorization module for specific components in Hadoop. It is useful in defining and enforcing different levels of privileges on data for users on a Hadoop cluster.
This blog post provides an overview of best practice for the design and deployment of clusters incorporating hardware and operating system configuration, along with guidance for networking and security as well as integration with existing enterprise infrastructure. Introduction and Rationale. IPV6 is not supported and should be disabled.
Using the Hadoop CLI. If you’re bringing your own, it’s as simple as creating the bucket in Ozone using the Hadoop CLI and putting the data you want there: hdfs dfs -mkdir ofs://ozone1/data/tpc/test. The post Generating and Viewing Lineage through Apache Ozone appeared first on Cloudera Blog. Don’t forget the trailing slash.
Cloudera will publish separate blog posts with results of performance benchmarks. Cisco UCS C240 M5 Rack Servers deliver a highly dense, cost-optimized, on-premises storage with broad infrastructure flexibility for object storage, Hadoop, and Big Data analytics solutions. Cisco Data Intelligence Platform.
As separate companies, we built on the broad Apache Hadoop ecosystem. We recognized the power of the Hadoop technology, invented by consumer internet companies, to deliver on that promise. As Arun’s blog makes clear, we see enormous potential in further advances in IoT, data warehousing and machine learning. Please join us !
Contact Info Ajay @acoustik on Twitter LinkedIn Mike LinkedIn Website @michaelfreedman on Twitter Timescale Website Documentation Careers timescaledb on GitHub @timescaledb on Twitter Parting Question From your perspective, what is the biggest gap in the tooling or technology for data management today?
I started my current career path with Hortonworks in 2016, back when we still had to tell people what Hadoop was. Yes, the days of Hadoop are gone, but we did the impossible and built an even better data platform while still empowering open-source and the different teams. I found Apache NiFi especially interesting.
This blog post will discuss some of the common causes, which have nothing to do with technology and everything to do with poor planning. At the start of the big data era in the early 2010’s, implementing Hadoop was considered a prime resume builder. Today, the same pattern can be seen with cloud migrations.
link] Uber: Modernizing Uber’s Batch Data Infrastructure with Google Cloud Platform Uber is one of the largest Hadoop installations, with exabytes of data. The performance issue impacts the users' productivity, and the blog explains how the data team built a custom LookML validator integrated with the IDE to improve its performance.
Data Analytics with Hadoop: An Introduction for Data Scientists - Jenny Kim, Benjamin Bengfort "Data Analytics with Hadoop: An Introduction for Data Scientists" by Jenny Kim and Benjamin Bengfort, published by O'Reilly Media in 2016, is rated 4.0/5 Read various blog posts, articles, and Python tutorials.
One day, I decided to save the links on a blog created for the occasion, a few days later, 3 people subscribed. I was coming from the Hadoop world and BigQuery was a breath of fresh air. I even hired 2 awesome interns who helped me on the blog for a few months. Blog subscriptions bring me 300 € / month.
First, remember the history of Apache Hadoop. The two of them started the Hadoop project to build an open-source implementation of Google’s system. It staffed up a team to drive Hadoop forward, and hired Doug. Three years later, the core team of developers working inside Yahoo on Hadoop spun out to found Hortonworks.
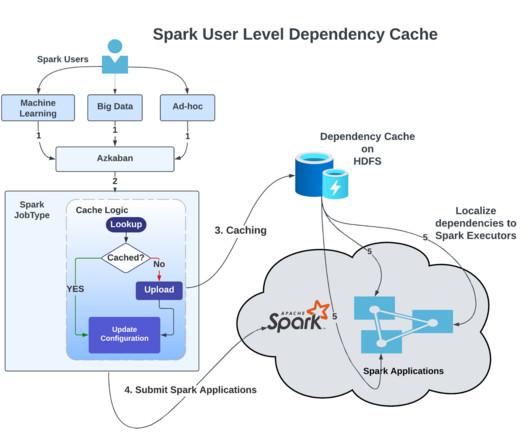
We execute nearly 100,000 Spark applications daily in our Apache Hadoop YARN (more on how we scaled YARN clusters here ). Every day, we upload nearly 30 million dependencies to the Apache Hadoop Distributed File System (HDFS) to run Spark applications.
Most of the Data engineers working in the field enroll themselves in several other training programs to learn an outside skill, such as Hadoop or Big Data querying, alongside their Master's degree and PhDs. Hadoop Platform Hadoop is an open-source software library created by the Apache Software Foundation.
For organizations who are considering moving from a legacy data warehouse to Snowflake, are looking to learn more about how the AI Data Cloud can support legacy Hadoop use cases, or are struggling with a cloud data warehouse that just isn’t scaling anymore, it often helps to see how others have done it.
In this blog, we explore the evolution of our in-house batch processing infrastructure and how it helps Robinhood work smarter. Hadoop-Based Batch Processing Platform (V1) Initial Architecture In our early days of batch processing, we set out to optimize data handling for speed and enhance developer efficiency.
Contact Info @jgperrin on Twitter Blog Parting Question From your perspective, what is the biggest gap in the tooling or technology for data management today? Contact Info @jgperrin on Twitter Blog Parting Question From your perspective, what is the biggest gap in the tooling or technology for data management today?
During Monarch’s inception in 2016, the most dominant batch processing technology around to build the platform was Apache Hadoop YARN. Now, eight years later, we have made the decision to move off of Apache Hadoop and onto our next generation Kubernetes (K8s) based platform. A major version upgrade to 3.x
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content