This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Hiring managers agree that “Java is one of the most in-demand and essential skill for Hadoop jobs. But how do you get one of those hot javahadoop jobs ? You have to ace those pesky javahadoop job interviews artfully. To demonstrate your java and hadoop skills at an interview, preparation is vital.
Hadoop initially led the way with Big Data and distributed computing on-premise to finally land on Modern Data Stack — in the cloud — with a data warehouse at the center. In order to understand today's data engineering I think that this is important to at least know Hadoop concepts and context and computer science basics.
Hadoop was first made publicly available as an open source in 2011, since then it has undergone major changes in three different versions. Apache Hadoop 3 is round the corner with members of the Hadoop community at Apache Software Foundation still testing it. The major release of Hadoop 3.x x vs. Hadoop 3.x
Hadoop has now been around for quite some time. But this question has always been present as to whether it is beneficial to learn Hadoop, the career prospects in this field and what are the pre-requisites to learn Hadoop? The availability of skilled big data Hadoop talent will directly impact the market.
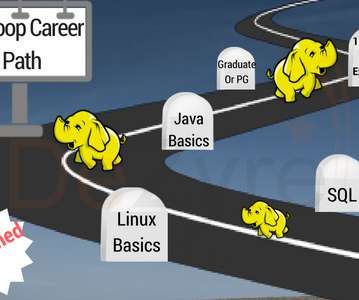
Let’s help you out with some detailed analysis on the career path taken by hadoop developers so you can easily decide on the career path you should follow to become a Hadoop developer. What do recruiters look for when hiring Hadoop developers? Do certifications from popular Hadoop distribution providers provide an edge?
Good old data warehouses like Oracle were engine + storage, then Hadoop arrived and was almost the same you had an engine (MapReduce, Pig, Hive, Spark) and HDFS, everything in the same cluster, with data co-location. you could write the same pipeline in Java, in Scala, in Python, in SQL, etc.—with Here we go again.
Choosing the right Hadoop Distribution for your enterprise is a very important decision, whether you have been using Hadoop for a while or you are a newbie to the framework. Different Classes of Users who require Hadoop- Professionals who are learning Hadoop might need a temporary Hadoop deployment.
That's where Hadoop comes into the picture. Hadoop is a popular open-source framework that stores and processes large datasets in a distributed manner. Organizations are increasingly interested in Hadoop to gain insights and a competitive advantage from their massive datasets. Why Are Hadoop Projects So Important?
In this blog post, we will discuss such technologies. If you pursue the MSc big data technologies course, you will be able to specialize in topics such as Big Data Analytics, Business Analytics, Machine Learning, Hadoop and Spark technologies, Cloud Systems etc. It is especially true in the world of big data.
A lot of people who wish to learn hadoop have several questions regarding a hadoop developer job role - What are typical tasks for a Hadoop developer? How much java coding is involved in hadoop development job ? What day to day activities does a hadoop developer do?
Why do data scientists prefer Python over Java? Java vs Python for Data Science- Which is better? Which has a better future: Python or Java in 2021? This blog aims to answer all questions on how Java vs Python compare for data science and which should be the programming language of your choice for doing data science in 2021.
This job requires a handful of skills, starting from a strong foundation of SQL and programming languages like Python , Java , etc. They achieve this through a programming language such as Java or C++. It is considered the most commonly used and most efficient coding language for a Data engineer and Java, Perl, or C/ C++.
We know that big data professionals are far too busy to searching the net for articles on Hadoop and Big Data which are informative and factually accurate. We have taken the time and listed 10 best Hadoop articles for you. To read the complete article, click here 2) How much Java is required to learn Hadoop?
And so spawned from this research paper, the big data legend - Hadoop and its capabilities for processing enormous amount of data. Same is the story, of the elephant in the big data room- “Hadoop” Surprised? Yes, Doug Cutting named Hadoop framework after his son’s tiny toy elephant. Why use Hadoop?
In the early days, many companies simply used Apache Kafka ® for data ingestion into Hadoop or another data lake. Some Kafka and Rockset users have also built real-time e-commerce applications , for example, using Rockset’s Java, Node.js However, Apache Kafka is more than just messaging.
It is possible today for organizations to store all the data generated by their business at an affordable price-all thanks to Hadoop, the Sirius star in the cluster of million stars. With Hadoop, even the impossible things look so trivial. So the big question is how is learning Hadoop helpful to you as an individual?
This blog post gives an overview on the big data analytics job market growth in India which will help the readers understand the current trends in big data and hadoop jobs and the big salaries companies are willing to shell out to hire expert Hadoop developers. It’s raining jobs for Hadoop skills in India.
Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java. Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java.
The toughest challenges in business intelligence today can be addressed by Hadoop through multi-structured data and advanced big data analytics. Big data technologies like Hadoop have become a complement to various conventional BI products and services. Big data, multi-structured data, and advanced analytics.
As open source technologies gain popularity at a rapid pace, professionals who can upgrade their skillset by learning fresh technologies like Hadoop, Spark, NoSQL, etc. From this, it is evident that the global hadoop job market is on an exponential rise with many professionals eager to tap their learning skills on Hadoop technology.
Confused over which framework to choose for big data processing - Hadoop MapReduce vs. Apache Spark. This blog helps you understand the critical differences between two popular big data frameworks. Hadoop and Spark are popular apache projects in the big data ecosystem. Confused Hadoop vs. Spark – Which One is Better?
In one of our previous articles we had discussed about Hadoop 2.0 YARN framework and how the responsibility of managing the Hadoop cluster is shifting from MapReduce towards YARN. In one of our previous articles we had discussed about Hadoop 2.0 Here we will highlight the feature - high availability in Hadoop 2.0
The technology was written in Java and Scala in LinkedIn to solve the internal problem of managing continuous data flows. In former times, Kafka worked with Java only. The hybrid data platform supports numerous Big Data frameworks including Hadoop and Spark , Flink, Flume, Kafka, and many others. Kafka vs Hadoop.
There are numerous large books with a lot of superfluous java information but very little practical programming help. This book introduces data scientists to the Hadoop ecosystem and its tools for big data analytics. This book introduces data scientists to the Hadoop ecosystem and its tools for big data analytics.
In this comprehensive blog, we delve into the foundational aspects and intricacies of the machine learning landscape. Knowledge of C++ helps to improve the speed of the program, while Java is needed to work with Hadoop and Hive, and other tools that are essential for a machine learning engineer.
Understanding the Hadoop architecture now gets easier! This blog will give you an indepth insight into the architecture of hadoop and its major components- HDFS, YARN, and MapReduce. We will also look at how each component in the Hadoop ecosystem plays a significant role in making Hadoop efficient for big data processing.
Java Client applications accessing a secure HBase cluster using HBase Java Client API must authenticate themselves against same security domain for HBase with one of the following approaches: The user running the client application must have acquired kerberos credentials prior to launching the application.
In this blog, I will explain the top 10 job roles you can choose per your interests and outline their salaries. Some prevalent programming languages like Python and Java have become necessary even for bankers who have nothing to do with them. Skills Required: Good command of programming languages such as C, C++, Java, and Python.
For the majority of Spark’s existence, the typical deployment model has been within the context of Hadoop clusters with YARN running on VM or physical servers. DE supports Scala, Java, and Python jobs. The post Introducing CDP Data Engineering: Purpose Built Tooling For Accelerating Data Pipelines appeared first on Cloudera Blog.
It provides high-level APIs in Java, Scala, Python, and R and an optimized engine that supports general execution graphs. Prerequisites This guide assumes that you are using Ubuntu and that Hadoop 2.7 Hadoop should be installed on your Machine. Now, test whether Java is installed properly or not by checking the version of Java.
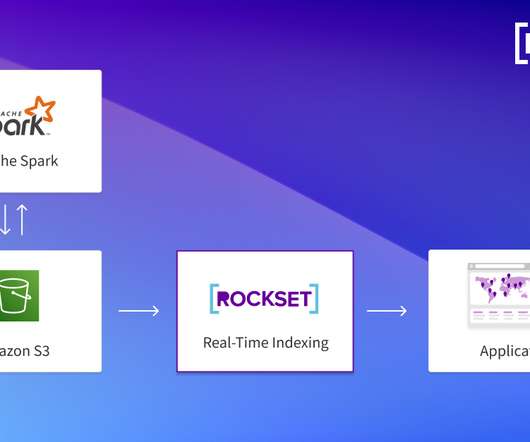
This blog post will present a simple “hello world” kind of example on how to get data that is stored in S3 indexed and served by an Apache Solr service hosted in a Data Discovery and Exploration cluster in CDP. We will only cover AWS and S3 environments in this blog. We will only cover AWS and S3 environments in this blog.
Get to know more about measures of dispersion through our blogs. Hadoop This open-source batch-processing framework can be used for the distributed storage and processing of big data sets. There are four main modules within Hadoop. Hadoop Common is where the libraries and utilities needed by other Hadoop modules reside.
In this blog post, we would like to share the performance improvements available in Apache HBase (HBase1 vs HBase2). . Hadoop) or a banking system to access and view account statements . sudo yum install java-11-openjdk. YCSB Workload C is a read only workload and performs . 100% READ operations. sudo apt install openjdk-11-jdk.
Even though Spark is written in Scala, you can interact with Spark with multiple languages like Spark, Python, and Java. Getting started with Apache Spark You’ll need to ensure you have Apache Spark, Scala, and the latest Java version installed. Make sure that your profile is set to the correct paths for Java, Spark, and such.
This is part of our series of blog posts on recent enhancements to Impala. For a more in-depth description of these phases please refer to Impala: A Modern, Open-Source SQL Engine for Hadoop. The post Keeping Small Queries Fast – Short query optimizations in Apache Impala appeared first on Cloudera Blog.
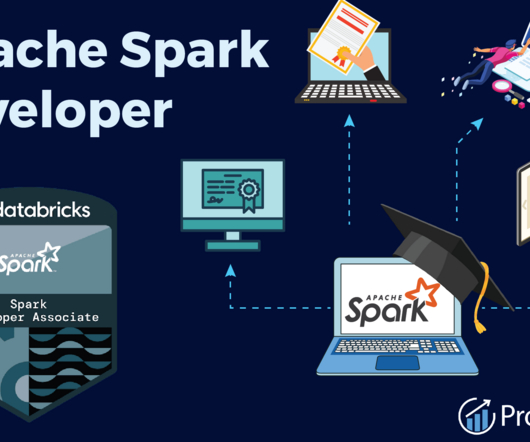
This blog explores the pathway to becoming a successful Databricks Certified Apache Spark Developer and presents an overview of everything you need to know about the role of a Spark developer. Python, Java, and Scala knowledge are essential for Apache Spark developers. Working knowledge of S3, Cassandra, or DynamoDB.
It serves as a foundation for the entire data management strategy and consists of multiple components including data pipelines; , on-premises and cloud storage facilities – data lakes , data warehouses , data hubs ;, data streaming and Big Data analytics solutions ( Hadoop , Spark , Kafka , etc.);
hdfs dfs -cat” on the file triggers a hadoop KMS API call to validate the “DECRYPT” access. However, we can continue without enabling TLS for the purpose of this blog. TO ' rangerkms '@'localhost' IDENTIFIED BY ' Hadoop_123 '; Download and install mysql java connector jar: $ wget [link]. tar zxvf mysql-connector-java-5.1.46.tar.gz.
Introduction Spark’s aim is to create a new framework that was optimized for quick iterative processing, such as machine learning and interactive data analysis while retaining Hadoop MapReduce’s scalability and fault-tolerant. Spark could indeed run by itself, on Apache Mesos, or on Apache Hadoop, which is the most common.
Data engineering involves a lot of technical skills like Python, Java, and SQL (Structured Query Language). For a data engineer career, you must have knowledge of data storage and processing technologies like Hadoop, Spark, and NoSQL databases. Understanding of Big Data technologies such as Hadoop, Spark, and Kafka.
The Ranger plugin base is available only in Java, as most Hadoop ecosystem projects, including Ranger, are written in Java. As such, Impala authorizes requests against the policies in the Hadoop SQL repository, including requests on Kudu-backed tables. Table ownership.
Reader's Choice: The topic for this article has been recommended by one of our Blog subscribers. How PayPal uses Hadoop? Before the advent of Hadoop, PayPal just let all the data go, as it was difficult to catch-all schema types on traditional databases. PayPal expands its Hadoop usage into HBase to leverage HDFS.
In this blog, we'll dive into some of the most commonly asked big data interview questions and provide concise and informative answers to help you ace your next big data job interview. Typically, data processing is done using frameworks such as Hadoop, Spark, MapReduce, Flink, and Pig, to mention a few. RDBMS stores structured data.
This blog post is my note after reading the paper: The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded, Out-of-Order Data Processing. In the rest of this blog, we will see how Google enables this contribution. MillWheel acts as the beneath stream execution engine.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content