This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As part of this, we are also supporting Snowpipe Streaming as an ingestion method for our Snowflake Connector for Kafka. Now we are able to ingest our data in near real time directly from Kafka topics to a Snowflake table, drastically reducing the cost of ingestion and improving our SLA from 15 minutes to within 60 seconds.
How cool would it be to build your own burglar alarm system that can alert you before the actual event takes place simply by using a few network-connected cameras and analyzing the camera images with Apache Kafka ® , Kafka Streams, and TensorFlow? I will show how to implement this use case in this blog post.
The blog highlights how emerging AI tools automate otherwise cognitively intensive manual tasks to bring reliability in software engineering. link] Uber: Fixrleak - Fixing Java Resource Leaks with GenAI Another interesting article from Uber demonstrates how AI significantly accelerates the reliability effects.
As a distributed system for collecting, storing, and processing data at scale, Apache Kafka ® comes with its own deployment complexities. To simplify all of this, different providers have emerged to offer Apache Kafka as a managed service. Before Confluent Cloud was announced , a managed service for Apache Kafka did not exist.
Using Jaeger tracing, I’ve been able to answer an important question that nearly every Apache Kafka ® project that I’ve worked on posed: how is data flowing through my distributed system? Distributed tracing with Apache Kafka and Jaeger. Example of a Kafka project with Jaeger tracing. What does this all mean?
I’ve written an event sourcing bank simulation in Clojure (a lisp build for Java virtual machines or JVMs) called open-bank-mark , which you are welcome to read about in my previous blog post explaining the story behind this open source example. The schemas are also useful for generating specific Java classes.
Apache-Kafka ® -based applications stand out for their ability to decouple producers and consumers using an event log as an intermediate layer. This article describes how to instrument Kafka-based applications with distributed tracing capabilities in order to make dataflows between event-based components more visible.
In the early days, many companies simply used Apache Kafka ® for data ingestion into Hadoop or another data lake. However, Apache Kafka is more than just messaging. Some Kafka and Rockset users have also built real-time e-commerce applications , for example, using Rockset’s Java, Node.js
Together, MongoDB and Apache Kafka ® make up the heart of many modern data architectures today. Integrating Kafka with external systems like MongoDB is best done though the use of Kafka Connect. The official MongoDB Connector for Apache Kafka is developed and supported by MongoDB engineers. Getting started.
Following part 1 and part 2 of the Spring for Apache Kafka Deep Dive blog series, here in part 3 we will discuss another project from the Spring team: Spring Cloud Data Flow , which focuses on enabling developers to easily develop, deploy, and orchestrate event streaming pipelines based on Apache Kafka ®. Command Line Shell.
As discussed in part 2, I created a GitHub repository with Docker Compose functionality for starting a Kafka and Confluent Platform environment, as well as the code samples mentioned below. We used Groovy instead of Java to write our UDFs, so we’ve applied the groovy plugin. gradlew composeUp. Note: When executing./gradlew
Apache Kafka ® and its surrounding ecosystem, which includes Kafka Connect, Kafka Streams, and KSQL, have become the technology of choice for integrating and processing these kinds of datasets. Microservices, Apache Kafka, and Domain-Driven Design (DDD) covers this in more detail. Example: Severstal.
The Kafka Streams API boasts a number of capabilities that make it well suited for maintaining the global state of a distributed system. At Imperva, we took advantage of Kafka Streams to build shared state microservices that serve as fault-tolerant, highly available single sources of truth about the state of objects in our system.
Previously in 3 Ways to Prepare for Disaster Recovery in Multi-Datacenter Apache Kafka Deployments , we provided resources for multi-datacenter designs, centralized schema management, prevention of cyclic repetition of messages, and automatic consumer offset translation to automatically resume applications.
link] Confluent: Guide to Consumer Offsets - Manual Control, Challenges, and the Innovations of KIP-1094 The article provides a comprehensive guide to Kafka consumer offsets, explaining their role in tracking consumption progress and the importance of manual offset control for reliability and exactly-once semantics (EOS).
Kafka can continue the list of brand names that became generic terms for the entire type of technology. In this article, we’ll explain why businesses choose Kafka and what problems they face when using it. In this article, we’ll explain why businesses choose Kafka and what problems they face when using it. What is Kafka?
A central component of data ingestion infrastructure at Pinterest is our PubSub stack, and the Logging Platform team currently runs deployments of Apache Kafka and MemQ. years since our previous blog post, PSC has been battle-tested at large scale in Pinterest with notably positive feedback and results.
Here in part 4 of the Spring for Apache Kafka Deep Dive blog series, we will cover: Common event streaming topology patterns supported in Spring Cloud Data Flow. Create and manage event streaming pipelines, including a Kafka Streams application using Spring Cloud Data Flow. java -jar spring-cloud-dataflow-shell-2.1.0.RELEASE.jar.
The blog is an excellent summarization of the common patterns emerging in GenAI platforms. The blog Prompt Engineering for a Better SQL Code Generation With LLMs is a pretty good guide on applying prompt engineering to improve productivity. Swiggy recently wrote about its internal platform, Hermes, a text-to-SQL solution.
The blog posts How to Build and Deploy Scalable Machine Learning in Production with Apache Kafka and Using Apache Kafka to Drive Cutting-Edge Machine Learning describe the benefits of leveraging the Apache Kafka ® ecosystem as a central, scalable and mission-critical nervous system. For now, we’ll focus on Kafka.
Since all the flows were simple event processing, the NiFi flows were built out in a matter of hours (drag-and-drop) instead of months (coding in Java). . As you’ll see in this blog, NiFi is not only keeping up with Storm; it beats Storm by 4x throughput. . Nifi Flows. Take the next steps to: Learn about Cloudera Flow Management.
This typically involved a lot of coding with Java, Scala or similar technologies. The DataFlow platform has established a leading position in the data streaming market by unlocking the combined value and synergies of Apache NiFi, Apache Kafka and Apache Flink. Stay tuned for more product updates coming soon!
This is the first installment in a short series of blog posts about security in Apache Kafka. Secured Apache Kafka clusters can be configured to enforce authentication using different methods, including the following: SSL – TLS client authentication. We use the kafka-console-consumer for all the examples below.
In the previous posts in this series, we have discussed Kerberos , LDAP and PAM authentication for Kafka. In this post we will look into how to configure a Kafka cluster and client to use a TLS client authentication. TLS is assumed to be enabled for the Apache Kafka cluster, as it should be for every secure cluster.
In part 1 , we discussed an event streaming architecture that we implemented for a customer using Apache Kafka ® , KSQL from Confluent, and Kafka Streams. In part 3, we’ll explore using Gradle to build and deploy KSQL user-defined functions (UDFs) and Kafka Streams microservices. Sample repository. gradlew composeUp.
Part 1 of this blog series by Gwen Shapira explained the benefits of schemas, contracts between services, and compatibility checking for schema evolution. Actually, we recommend that you consider another alternative to self-managing Schema Registry, and the next blog post in this series reveals what that alternative is! Bad designs.
Distributed transactions are very hard to implement successfully, which is why we’ll introduce a log-inspired system such as Apache Kafka ®. Building an indexing pipeline at scale with Kafka Connect. Moving data into Apache Kafka with the JDBC connector. For this use case, we are going to use it as a source connector.
In the above scenario, we would have to update all five services to connect to Apache Kafka ® , create the event in all the appropriate places inside each service, and then produce that event to a Kafka topic. The first point to consider is if connecting to Kafka from all services is even possible.
This data engineering skillset typically consists of Java or Scala programming skills mated with deep DevOps acumen. It’s also worth noting that even those with Java skills will often prefer to work with SQL – if for no other reason than to share the workload with others in their organization that only know SQL. A rare breed.
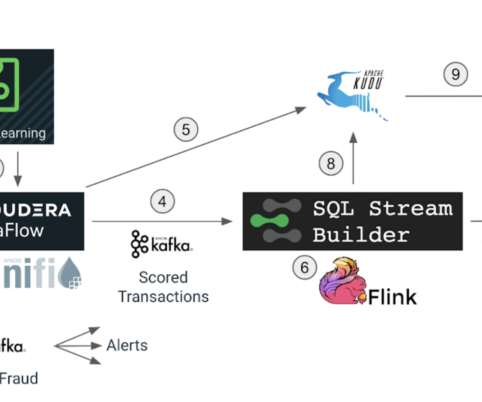
In part 1 of this blog we discussed how Cloudera DataFlow for the Public Cloud (CDF-PC), the universal data distribution service powered by Apache NiFi, can make it easy to acquire data from wherever it originates and move it efficiently to make it available to other applications in a streaming fashion.
In the second blog of the Universal Data Distribution blog series , we explored how Cloudera DataFlow for the Public Cloud (CDF-PC) can help you implement use cases like data lakehouse and data warehouse ingest, cybersecurity, and log optimization, as well as IoT and streaming data collection. Kafka REST Proxy for streaming data.
It offers a slick user interface for writing SQL queries to run against real-time data streams in Apache Kafka or Apache Flink. They no longer have to depend on any skilled Java or Scala developers to write special programs to gain access to such data streams. . SQL Stream Builder continuously runs SQL via Flink. Register NOW!
The idea in this blog post is to mix information coming from two distinct channels: the RSS feeds of sport-related newspapers and Twitter feeds of the FIFA Women’s World Cup. Ingesting Twitter data is very easy with Kafka Connect , a framework for connecting Kafka with external systems. Ingesting Twitter data. connector.state].
you could write the same pipeline in Java, in Scala, in Python, in SQL, etc.—with I won't delve into every announcement here, but for more details, SELECT has written a blog covering the 28 announcements and takeaways from the Summit. Accordingly to the press Snowflake and Confluent (Kafka) were also trying to buy Tabular.
In 2010, they introduced Apache Kafka , a pivotal Big Data ingestion backbone for LinkedIn’s real-time infrastructure. To transition from batch-oriented processing and respond to Kafka events within minutes or seconds, they built an in-house distributed event streaming framework, Apache Samza. hours to 25 minutes).
Why do data scientists prefer Python over Java? Java vs Python for Data Science- Which is better? Which has a better future: Python or Java in 2021? This blog aims to answer all questions on how Java vs Python compare for data science and which should be the programming language of your choice for doing data science in 2021.
Some of these improvements and features are: Flink JAR submission (for Java UDF’s). Run on your desktop or cloud node, connecting to Kafka or other sources/sinks via API calls to their respective clusters. We plan future blog posts on this workflow. Release Notes appeared first on Cloudera Blog. x compatibility.
The profile service will publish the changes in profiles, including address changes to an Apache Kafka ® topic, and the quote service will subscribe to the updates from the profile changes topic, calculate a new quote if needed and publish the new quota to a Kafka topic so other services can subscribe to the updated quote event.
In this particular blog post, we explain how Druid has been used at Lyft and what led us to adopt ClickHouse for our sub-second analytic system. Real-time Ingestion Events from our real-time analytics pipeline were configured to be sent into our internal Flink application, streamed to Kafka, and written into Druid.
The developers must understand lower-level languages like Java and Scala and be familiar with the streaming APIs. Streamings Messaging , powered by Apache Kafka, buffers and scales massive volumes of data streams for streaming analytics. appeared first on Cloudera Blog. Take the next step and learn more: Cloudera DataFlow.
In 2015, Cloudera became one of the first vendors to provide enterprise support for Apache Kafka, which marked the genesis of the Cloudera Stream Processing (CSP) offering. Today, CSP is powered by Apache Flink and Kafka and provides a complete, enterprise-grade stream management and stateful processing solution. Who is affected?
In SSB, today we are supporting JavaScript (JS) and Java UDFs, which can be used as a function with your data. But let’s assume we have already set up such a table, based off of a Kafka topic that has the ADSB data streaming through it, and we have named it airplanes. With UDFs you can really enhance the capabilities of your queries.
The previous blog post How to Build a UDF and/or UDAF in KSQL 5.0 creating custom KSQL functions is even easier when you leverage Maven , a tool for building and managing dependencies in Java projects. java ? ? ??? For this example, we’ll assume there’s a topic named api_logs in our Kafka cluster. my-udf/ ???
We’re introducing a new Rockset Integration for Apache Kafka that offers native support for Confluent Cloud and Apache Kafka, making it simpler and faster to ingest streaming data for real-time analytics. With the Kafka Integration, users no longer need to build, deploy or operate any infrastructure component on the Kafka side.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content