This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this blog post I'll share with you a list of Java and Scala classes I use almost every time in data engineering projects. We all have our habits and as programmers, libraries and frameworks are definitely a part of the group. The part for Python will follow next week!
Lucas’ story is shared by lots of beginner Scala developers, which is why I wanted to post it here on the blog. I’ve watched thousands of developers learn Scala from scratch, and, like Lucas, they love it! If you want to learn Scala well and fast, take a look at my Scala Essentials course at Rock the JVM.
For over 2 decades, Java has been the mainstay of app development. Another reason for its popularity is its cross-platform and cross-browser compatibility, making applications written in Java highly portable. These very qualities gave rise to the need for reusability of code, version control, and other tools for Java developers.
Snowflakes Snowpark is a game-changing feature that enables data engineers and analysts to write scalable data transformation workflows directly within Snowflake using Python, Java, or Scala.
This typically involved a lot of coding with Java, Scala or similar technologies. The post Cloudera acquires Eventador to accelerate Stream Processing in Public & Hybrid Clouds appeared first on Cloudera Blog. Stay tuned for more product updates coming soon!
you could write the same pipeline in Java, in Scala, in Python, in SQL, etc.—with I won't delve into every announcement here, but for more details, SELECT has written a blog covering the 28 announcements and takeaways from the Summit. Databricks sells a toolbox, you don't buy any UX. 3) Spark 4.0
CDE supports Scala, Java, and Python jobs. For example, a Java program running Spark with specific configurations. The post Delivering Modern Enterprise Data Engineering with Cloudera Data Engineering on Azure appeared first on Cloudera Blog. CDE also support Airflow job types. . A job run is an execution of a job.
In recent years, quite a few organizations have preferred Java to meet their data science needs. From ERPs to web applications, Navigation Systems to Mobile Applications, Java has been facilitating advancement for more than a quarter of a century now. Is Learning Java Mandatory? So let us get to it.
To expand the capabilities of the Snowflake engine beyond SQL-based workloads, Snowflake launched Snowpark , which added support for Python, Java and Scala inside virtual warehouse compute. You can read more about their experience with Snowpark Container Services in this two-part blog series ( part 1 , part 2 ).
They no longer have to depend on any skilled Java or Scala developers to write special programs to gain access to such data streams. . To execute such real-time queries, the skills are typically in the hands of a select few in the organization who possess unique skills like Scala or Java and can write code to get such insights.
This data engineering skillset typically consists of Java or Scala programming skills mated with deep DevOps acumen. It’s also worth noting that even those with Java skills will often prefer to work with SQL – if for no other reason than to share the workload with others in their organization that only know SQL.
This article is all about choosing the right Scala course for your journey. How should I get started with Scala? Do you have any tips to learn Scala quickly? How to Learn Scala as a Beginner Scala is not necessarily aimed at first-time programmers. Which course should I take?
And now with Snowpark we have opened the engine to Python, Java, and Scala developers, who are accelerating development and performance of their workloads, including IQVIA for data engineering, EDF Energy for feature engineering, Bridg for machine learning (ML) processing, and more.
There is also a great article about ANN on Elastic blog by Julie Tibshirani - read it, you won't regret it. The application is written in Scala and using a Java High Level REST Client, which got deprecated in Elasticsearch 7.15.0 However: It’s in Java. Upgrading the Elasticsearch API to be able to work with version 8.x
The thought of learning Scala fills many with fear, its very name often causes feelings of terror. The truth is Scala can be used for many things; from a simple web application to complex ML (Machine Learning). The name Scala stands for “scalable language.” So what companies are actually using Scala?
This data engineering skill set typically consists of Java or Scala programming skills mated with deep DevOps acumen. They no longer have to depend on any skilled Java or Scala developers to write special programs to gain access to such data streams. A rare breed.
Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java. Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java.
In part 1 of this blog we discussed how Cloudera DataFlow for the Public Cloud (CDF-PC), the universal data distribution service powered by Apache NiFi, can make it easy to acquire data from wherever it originates and move it efficiently to make it available to other applications in a streaming fashion. Use case recap.
Why do data scientists prefer Python over Java? Java vs Python for Data Science- Which is better? Which has a better future: Python or Java in 2021? This blog aims to answer all questions on how Java vs Python compare for data science and which should be the programming language of your choice for doing data science in 2021.
I will show how to implement this use case in this blog post. Using the Java interface to OpenCV , it should be possible to process a RTSP (Real-Time Streaming Protocol) image stream, extract individual frames, and detect motion. First of all, you will need one or more IP cameras to retrieve the images for processing.
In this blog post, we will see the top Automation testing tools used in the software industry. Can use Selenium API with programming languages like Java, C#, Ruby, Python, Perl PHP, Javascript, R, etc. The performance tool supports languages like Java, Scala, Groovy, Ruby, and more. Supports cross-browser testing.
Leveraging the full power of a functional programming language In Zalando Dublin, you will find that most engineering teams are writing their applications using Scala. We will try to explain why that is the case and the reasons we love Scala. How I came to use Scala I have been working with JVM for the last 18 years.
Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java. Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java.
The developers must understand lower-level languages like Java and Scala and be familiar with the streaming APIs. appeared first on Cloudera Blog. Need Experts with Special Skills – The challenge with streaming analytics is that few experts are in the field and often hard to hire. Watch a video. Contact an expert.
In this blog post, we will delve into six such capabilities – comprehensive cross-cloud replication, zero copy database and schema clone, collation support, stored procedures, multi-table transactions, and transparent online upgrade – that every enterprise must consider while choosing their data platforms.
Skill-based roles cannot rapidly respond to customer requests – Imagine a project where different parts are written in Java, Scala, and Python. We’ll cover some of the potential challenges facing data mesh enterprise architectures in our next blog. Data professionals are not perfectly interchangeable.
In this blog post we will use what we have learned in this Data Vault blog series to support the data preparation requirements for ML on Snowflake, using Data Vault patterns for modeling and automation. Based on Tecton blog So is this similar to data engineering pipelines into a data lake/warehouse?
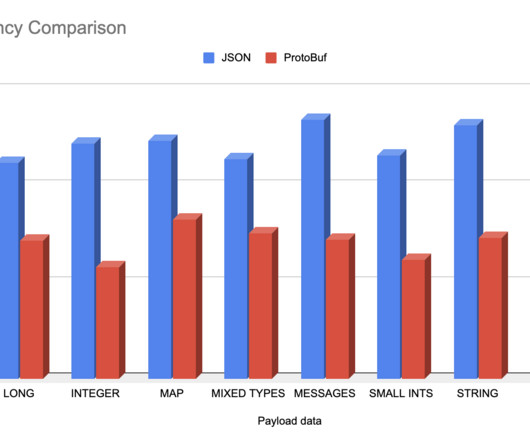
In this blog post, we’ll discuss some of the challenges we faced with JSON and the process we used to evaluate new solutions and ultimately move forward with Google Protocol Buffers (Protobuf) as a replacement. When we looked for a JSON replacement, we wanted an alternative that satisfied a few criteria.
Even though Spark is written in Scala, you can interact with Spark with multiple languages like Spark, Python, and Java. Getting started with Apache Spark You’ll need to ensure you have Apache Spark, Scala, and the latest Java version installed. In my case, I needed aws-java-sdk-bundle 1.11.375 for Apache Spark 3.2.0.
This blog explores the pathway to becoming a successful Databricks Certified Apache Spark Developer and presents an overview of everything you need to know about the role of a Spark developer. Python, Java, and Scala knowledge are essential for Apache Spark developers. Creating Spark/Scala jobs to aggregate and transform data.
Read the first blog here. join( """{. HBase allows for this through Bulk Operations and is supported for Spark programs written in Scala and Java. For more information on those operations using Scala or Java look at this link [link]. Get/Scan Operations. Using Catalogs. getOrCreate(). Troubleshooting.
Blogging As a software developer, you have more knowledge than an average blogger. You can take this to your advantage and start your own website, writing blogs about software development, AI (Artificial Intelligence) and ML (Machine Learning), etc. Also, a Sun Certified Oracle Java Certification for Programmers will do.
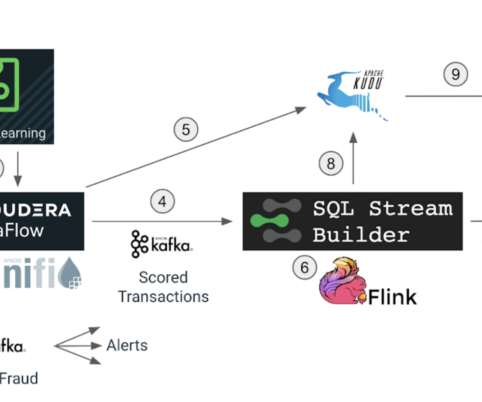
I had introduced Cloudera SQL Stream Builder in my earlier blog pos t and how it augments the powerful stream processing capabilities of the Cloudera DataFlow (CDF) platform by accelerating time to market and democratizing access to real-time data using continuous SQL. For a live demo of this product, attend our webinar on 2nd June.
It provides high-level APIs in Java, Scala, Python, and R and an optimized engine that supports general execution graphs. sudo apt-get install oracle-java8-installer The above command creates a java-8-oracle Directory in /usr/lib/jvm/ directory in your machine. The below command should show the java version.
This blog offers a comprehensive explanation of the data skills you must acquire, the top data science online courses , career paths in data science, and how to create a portfolio to become a data scientist. However, the language of choice ought to be one of the popular ones, like Python, R, or Scala. Who can Become Data Scientist?
If you are not familiar with the above-mentioned concepts, we suggest you to follow the links above to learn more about each of them in our blog posts. Also, they must have in-depth knowledge of data processing languages like Python, Scala, or SQL. .); machine learning and deep learning models; and business intelligence tools.
In this blog, we provide a few examples that show how organizations put deep learning to work. CDSW provides data scientists with a browser-based development environment for Python, R, and Scala. With Scala and Python APIs, the software provides broad support for deep learning model development and inference. Deeplearning4j.
In a previous blog of this series, Turning Streams Into Data Products , we talked about the increased need for reducing the latency between data generation/ingestion and producing analytical results and insights from this data. This blog will be published in two parts. This is what we call the first-mile problem. The use case.
This blog post goes over: The complexities that users will run into when self-managing Apache Kafka on the cloud and how users can benefit from building event streaming applications with a fully managed service for Apache Kafka. Before Confluent Cloud was announced , a managed service for Apache Kafka did not exist.
DE supports Scala, Java, and Python jobs. The post Introducing CDP Data Engineering: Purpose Built Tooling For Accelerating Data Pipelines appeared first on Cloudera Blog. For a data engineer that has already built their Spark code on their laptop, we have made deployment of jobs one click away.
Get to know more about measures of dispersion through our blogs. Spark is most notably easy to use, and it’s easy to write applications in Java, Scala, Python, and R. Programs can be written in Java, Scala, Python, and SQL, and Flink offers support for event-time processing and state management.
This blog aims to answer two questions as illustrated in the diagram below: How have stream processing requirements and use cases evolved as more organizations shift to “streaming first” architectures and attempt to build streaming analytics pipelines? The post Turning Streams Into Data Products appeared first on Cloudera Blog.
In this blog post, we will discuss such technologies. Spark provides an interactive shell that can be used for ad-hoc data analysis, as well as APIs for programming in Java, Python, and Scala. It is especially true in the world of big data. Spark is a fast and general-purpose cluster computing system.
In this blog we’ll dive into the latest announcements on Snowpark client libraries and server side enhancements on warehouses. For additional details on Snowpark Container Services, refer to our launch blog available here.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content