This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
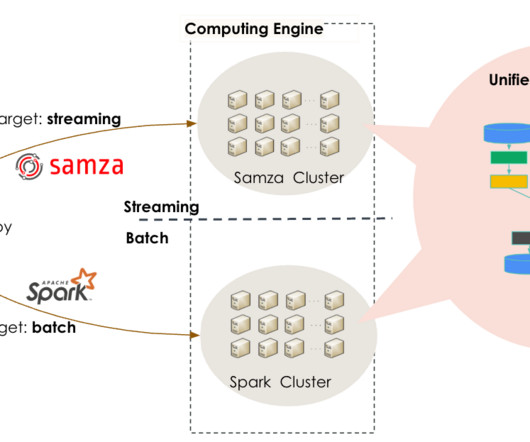
In 2010, they introduced Apache Kafka , a pivotal Big Data ingestion backbone for LinkedIn’s real-time infrastructure. To transition from batch-oriented processing and respond to Kafka events within minutes or seconds, they built an in-house distributed event streaming framework, Apache Samza. hours to 25 minutes).
Aggregator Leaf Tailer (ALT) is the data architecture favored by web-scale companies, like Facebook, LinkedIn, and Google, for its efficiency and scalability. In this blog post, I will describe the Aggregator Leaf Tailer architecture and its advantages for low-latency data processing and analytics.
In the past, we often used lambdaarchitecture for processing jobs, meaning that our developers used two different systems for batch and stream processing. In this blog post, we will share our progress, challenges, and lessons learned from implementing Apache Beam. one side is Kafka, the other side is HDFS).
Data streamed in is queryable in conjunction with historical data, avoiding need for LambdaArchitecture. Figure 1 below shows a standard architecture for a Real-Time Data Warehouse. Deep Dive into Time Series and Event Analytics Specialized RTDW , featuring Apache Druid, Apache Hive, Apache Kafka, and Cloudera DataViz.
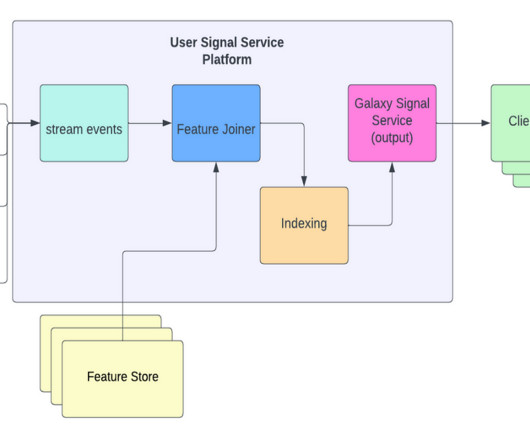
So our user sequence real-time indexing pipeline is composed of a Flink job that reads the relevant events as they come into our Kafka streams, fetches the desired features for each event from our feature services, and stores the enriched events into our KV store system. To explore life at Pinterest, visit our Careers page.
Lambdaarchitecture: A combination of both batch and real-time processing, the lambdaarchitecture has three layers. The lambdaarchitecture ensures completeness of data with minimal latency. In this blog, we discussed how it benefits business in the long run. It is useful for Big Data ingestion.
The blog highlights that the job is not just writing SQL but providing a strategic business solution for an organization. The blog is very educative for me about measuring the lifetime value of a customer and segmentation on buying behavior. The BTYD model is excellent for building a recommendation engine and marketing personalization.
And, out of these professions, this blog will discuss the data engineering job role. This architecture shows that simulated sensor data is ingested from MQTT to Kafka. The data in Kafka is analyzed with Spark Streaming API, and the data is stored in a column store called HBase. This is called Hot Path.
It talks about how to get adoption in your organization, a sample implementation, and the contract-driven architecture. link] Capital One: Democratizing machine learning It is an exciting blog post + video interview from Capital One focusing on the people and technology aspect of democratizing the machine learning practice across the org.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














Let's personalize your content