This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The key to those solutions is a robust and flexible metadata management system. LinkedIn has gone through several iterations on the most maintainable and scalable approach to metadata, leading them to their current work on DataHub. What were you using at LinkedIn for metadata management prior to the introduction of DataHub?
Put another way, courtesy of Spencer Ruport: LISTENERS are what interfaces Kafka binds to. Apache Kafka ® is a distributed system. When a client (producer/consumer) starts, it will request metadata about which broker is the leader for a partition—and it can do this from any broker. Is anyone listening? Brokers in the cloud (e.g.,
Data powers Uber’s global marketplace, enabling more reliable and seamless user experiences across our products for riders, … The post Databook: Turning Big Data into Knowledge with Metadata at Uber appeared first on Uber Engineering Blog.
Apache-Kafka ® -based applications stand out for their ability to decouple producers and consumers using an event log as an intermediate layer. This article describes how to instrument Kafka-based applications with distributed tracing capabilities in order to make dataflows between event-based components more visible.
The Kafka Streams API boasts a number of capabilities that make it well suited for maintaining the global state of a distributed system. At Imperva, we took advantage of Kafka Streams to build shared state microservices that serve as fault-tolerant, highly available single sources of truth about the state of objects in our system.
link] Confluent: Guide to Consumer Offsets - Manual Control, Challenges, and the Innovations of KIP-1094 The article provides a comprehensive guide to Kafka consumer offsets, explaining their role in tracking consumption progress and the importance of manual offset control for reliability and exactly-once semantics (EOS).
We know that Apache Kafka ® is great when you’re dealing with streams, allowing you to conveniently look at streams as tables. Kafka already allows you to look at data as streams or tables; graphs are a third option, a more natural representation with a lot of grounding in theory for some use cases. 8, and so on.
In this blog post, we’ll explore what CDC is, why it’s important, and our journey of implementing Generic CDC solutions for all online databases at Pinterest. Calls the data plane Apache Kafka® Connect API to obtain information about the current state of the system, such as the status of currently running connectors and their configurations.
As a distributed system for collecting, storing, and processing data at scale, Apache Kafka ® comes with its own deployment complexities. To simplify all of this, different providers have emerged to offer Apache Kafka as a managed service. Before Confluent Cloud was announced , a managed service for Apache Kafka did not exist.
The blog took out the last edition’s recommendation on AI and summarized the current state of AI adoption in enterprises. The simplistic model expressed in the blog made it easy for me to reason about the transactional system design. Kafka is probably the most reliable data infrastructure in the modern data era.
DoorDash’s Engineering teams revamped Kafka Topic creation by replacing a Terraform/Atlantis based approach with an in-house API, Infra Service. DoorDash’s Real-Time Streaming Platform, or RTSP, team is under the Data Platform organization and manages over 2,500 Kafka Topics across five clusters.
Previously in 3 Ways to Prepare for Disaster Recovery in Multi-Datacenter Apache Kafka Deployments , we provided resources for multi-datacenter designs, centralized schema management, prevention of cyclic repetition of messages, and automatic consumer offset translation to automatically resume applications.
With the release of Apache Kafka ® 2.1.0, Kafka Streams introduced the processor topology optimization framework at the Kafka Streams DSL layer. In what follows, we provide some context around how a processor topology was generated inside Kafka Streams before 2.1, Kafka Streams topology generation 101.
In this multi-part blog series, we take you behind the scenes of our system that processes billions of impressions daily. These extracted events are then routed to an Apache Kafka topic for immediate processing needs and simultaneously stored in an Apache Iceberg table for long-term retention and historical analysis.
It covers nine categories: storage systems, data lake platforms, processing, integration, orchestration, infrastructure, ML/AI, metadata management, and analytics. I found the blog to be a comprehensive roadmap for data engineering in 2025. The proposal discusses how Kafka will implement queue functionality similar to SQS and RabbitMQ.
The Grab blog delights me since I have tried to do this many times. A cross-encoder teacher model, fine-tuned on human-labeled data and enriched Pin metadata, was distilled into a lightweight student model using semi-supervised learning over billions of impressions. Kudos to the Grab team for building a docs-as-code system.
Get Your Copy → Walmart: Reliably Processing Trillions of Kafka Messages Per Day Consumer rebalancing and Head-of-line (HOL) blocking are some of the most common challenges while operating Kafka at scale. The blog explains KIP-932 and its potential benefits. The blog explains KIP-932 and its potential benefits.
We expand on this feature later in this blog. Atlas / Kafka integration provides metadata collection for Kafa producers/consumers so that consumers can manage, govern, and monitor Kafkametadata and metadata lineage in the Atlas UI. Deep Dive 2: Atlas / Kafka integration. x, and 6.3.x,
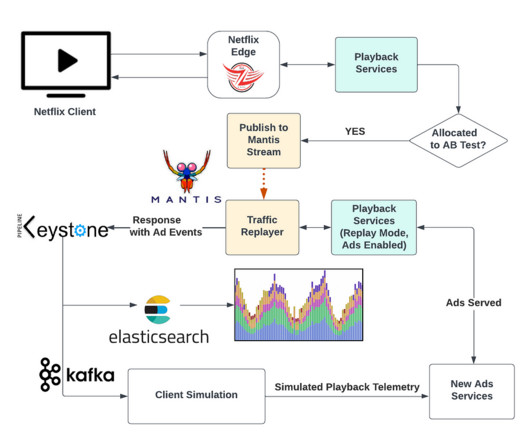
In this blog post, we’ll discuss the methods we used to ensure a successful launch, including: How we tested the system Netflix technologies involved Best practices we developed Realistic Test Traffic Netflix traffic ebbs and flows throughout the day in a sinusoidal pattern. Basic with ads was launched worldwide on November 3rd.
In this blog, I will demonstrate the value of Cloudera DataFlow (CDF) , the edge-to-cloud streaming data platform available on the Cloudera Data Platform (CDP) , as a Data integration and Democratization fabric. Data and Metadata: Data inputs and data outputs produced based on the application logic. Introduction.
Kafka can continue the list of brand names that became generic terms for the entire type of technology. In this article, we’ll explain why businesses choose Kafka and what problems they face when using it. In this article, we’ll explain why businesses choose Kafka and what problems they face when using it. What is Kafka?
The customer also wanted to utilize the new features in CDP PvC Base like Apache Ranger for dynamic policies, Apache Atlas for lineage, comprehensive Kafka streaming services and Hive 3 features that are not available in legacy CDH versions. Support Kafka connectivity to HDFS, AWS S3 and Kafka Streams. Kafka, SRM, SMM.
Below a diagram describing what I think schematises data platforms: Data storage — you need to store data in an efficient manner, interoperable, from the fresh to the old one, with the metadata. It adds metadata, read, write and transactions that allow you to treat a Parquet file as a table. Databricks bought Tabular for $1b.
In part 1 , we discussed an event streaming architecture that we implemented for a customer using Apache Kafka ® , KSQL from Confluent, and Kafka Streams. In part 3, we’ll explore using Gradle to build and deploy KSQL user-defined functions (UDFs) and Kafka Streams microservices. Sample repository. gradlew composeUp.
It provides abstractions and tools for the translation of lakehouse table format metadata. You can also read Timo detailed post on Mixpanel blog and why SCD are the best thing for product analytics. Apache Kafka overview — If you're not familiar with Kafka this is a great overview. His chart are great.
Joe Reis launched his Substack — Joe is the co-author of the great The Fundamentals of Data Engineering and his blog already have 2 articles I deeply recommend: No extra credit for complexity & Groundhog Days. This time Apple engineers shared at Trino—good old Presto for lost people—Summit how they use it.
A central component of data ingestion infrastructure at Pinterest is our PubSub stack, and the Logging Platform team currently runs deployments of Apache Kafka and MemQ. years since our previous blog post, PSC has been battle-tested at large scale in Pinterest with notably positive feedback and results.
Summary The majority of blog posts and presentations about data engineering and analytics assume that the consumers of those efforts are internal business users accessing an environment controlled by the business. Atlan is the metadata hub for your data ecosystem. Hevo]([link] Are you sick of repetitive, time-consuming ELT work?
From this release, Streams Messaging templates will support scaling with automatic rebalancing allowing you to grow or shrink your Apache Kafka cluster based on demand. Kafka Scaling. There will now be two specific hostgroups for Kafka Brokers; These are the Core_broker and Broker host groups. Atlas Schema Registry Integration.
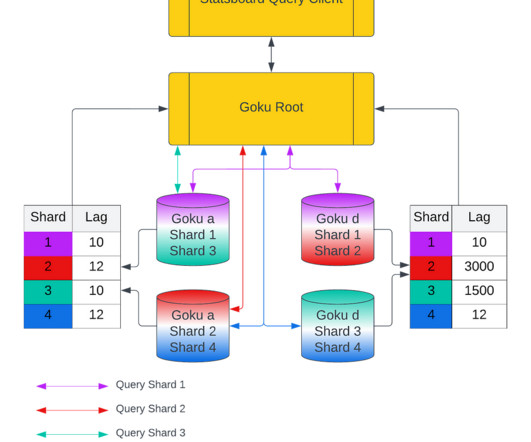
In the first blog, we will share a short summary on the GokuS and GokuL architecture, data format for Goku Long Term, and how we improved the bootstrap time for our storage and serving components. This is because the synthetic data points would be present in the retry kafka waiting to be pushed into the recovering host by the retry ingestor.
I won’t bore you with the importance of data quality in the blog. Since Kafka is almost synonymous with real-time data processing, we often call this a “Fronting Kafka” pattern. The Fronting Kafka pattern follows a two-cluster approach. Why is Data Quality Expensive? Now, Why is Data Quality Expensive?
In this blog post, we are going to share with you how Cloudera Stream Processing ( CSP ) is integrated with Apache Iceberg and how you can use the SQL Stream Builder ( SSB ) interface in CSP to create stateful stream processing jobs using SQL. Iceberg is a high-performance open table format for huge analytic data sets.
We built an asset management platform (AMP), codenamed Amsterdam , in order to easily organize and manage the metadata, schema, relations and permissions of these assets. Amsterdam service utilizes various solutions such as Cassandra , Kafka , Zookeeper , EvCache etc. This is the layer we’d like to focus on in this blog.
This blog post provides an overview of best practice for the design and deployment of clusters incorporating hardware and operating system configuration, along with guidance for networking and security as well as integration with existing enterprise infrastructure. Introduction and Rationale. Networking . Security integration.
In 2015, Cloudera became one of the first vendors to provide enterprise support for Apache Kafka, which marked the genesis of the Cloudera Stream Processing (CSP) offering. Today, CSP is powered by Apache Flink and Kafka and provides a complete, enterprise-grade stream management and stateful processing solution. Who is affected?
The profile service will publish the changes in profiles, including address changes to an Apache Kafka ® topic, and the quote service will subscribe to the updates from the profile changes topic, calculate a new quote if needed and publish the new quota to a Kafka topic so other services can subscribe to the updated quote event.
In this three-part blog post series, we introduce you to Psyberg , our incremental data processing framework designed to tackle such challenges! At Netflix, our backend microservices continuously generate real-time event data that gets streamed into Kafka. Given our role on this critical path, accuracy is paramount.
We are excited to announce the release of Confluent Cloud Schema Registry in general availability (GA), available in Confluent Cloud , our fully managed event streaming service based on Apache Kafka ®. Confluent Schema Registry provides a serving layer for your metadata and a RESTful interface for storing and retrieving Avro schemas.
Streaming data from Apache Kafka into Delta Lake is an integral part of Scribd’s data platform, but has been challenging to manage and scale. We use Spark Structured Streaming jobs to read data from Kafka topics and write that data into Delta Lake tables. To serve this need, we created kafka-delta-ingest.
Since the purpose of this blog is to show lineage for data that exists in Ozone, I’m going to do a simple transformation in the Spark shell and write the data out to Ozone. If you want to continue experimenting with Ozone and Atlas, you can try writing to Ozone via Kafka using our documented configuration examples.
In the rest of this blog, we will a) touch on the complexity of Netflix cloud landscape, b) discuss lineage design goals, ingestion architecture and the corresponding data model, c) share the challenges we faced and the learnings we picked up along the way, and d) close it out with “what’s next” on this journey. push or pull.
In this blog, we’ll highlight the key CDP aspects that provide data governance and lineage and show how they can be extended to incorporate metadata for non-CDP systems from across the enterprise. Extending Atlas’ metadata model. The example 1_typedef-server.json describes the server typedef used in this blog. .
Jeff Xiang | Senior Software Engineer, Logging Platform; Vahid Hashemian | Staff Software Engineer, LoggingPlatform When it comes to PubSub solutions, few have achieved higher degrees of ubiquity, community support, and adoption than Apache Kafka, which has become the industry standard for data transportation at large scale.
While it's well-known that Flink excels at filtering, joining and enriching streaming data from Apache Kafka® or Confluent Cloud , what is less known is that it is increasingly becoming ingrained in the end-to-end stack for AI-powered applications. These additional inputs are referred to as metadata filtering. What is RAG?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content