This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
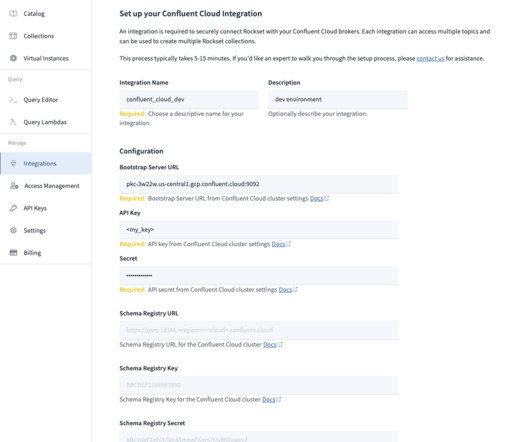
As a distributed system for collecting, storing, and processing data at scale, Apache Kafka ® comes with its own deployment complexities. To simplify all of this, different providers have emerged to offer Apache Kafka as a managed service. Before Confluent Cloud was announced , a managed service for Apache Kafka did not exist.
Kafka can continue the list of brand names that became generic terms for the entire type of technology. In this article, we’ll explain why businesses choose Kafka and what problems they face when using it. In this article, we’ll explain why businesses choose Kafka and what problems they face when using it. What is Kafka?
In your blog post that explains the design decisions for how Timescale is implemented you call out the fact that the inserted data is largely append only which simplifies the index management. The landscape of time series databases is extensive and oftentimes difficult to navigate.
In light of this, we’ll share an emerging machine-to-machine (M2M) architecture pattern in which MQTT, Apache Kafka ® , and Scylla all work together to provide an end-to-end IoT solution. MQTT Proxy + Apache Kafka (no MQTT broker). On the other hand, Apache Kafka may deal with high-velocity data ingestion but not M2M.
In this blog post, we will discuss such technologies. NoSQL databases are designed for scalability and flexibility, making them well-suited for storing big data. The most popular NoSQL database systems include MongoDB, Cassandra, and HBase. It is especially true in the world of big data.
The profile service will publish the changes in profiles, including address changes to an Apache Kafka ® topic, and the quote service will subscribe to the updates from the profile changes topic, calculate a new quote if needed and publish the new quota to a Kafka topic so other services can subscribe to the updated quote event.
It points to best practices for anyone writing Kafka Connect connectors. In a nutshell, the document states that sources and sinks are verified as Gold if they’re functionally equivalent to Kafka Connect connectors. Over the years, we’ve since seen wide adoption of Kafka Connect.
MongoDB has grown from a basic JSON key-value store to one of the most popular NoSQL database solutions in use today. Options For Change Data Capture on MongoDB Apache Kafka The native CDC architecture for capturing change events in MongoDB uses Apache Kafka. The Rockset solution requires neither Kafka nor Debezium.
Data Hub – has expanded to support all stages of the data lifecycle: Collect – Flow Management (Apache NiFi), Streams Management (Apache Kafka) and Streaming Analytics (Apache Flink). CDP Operational Database (2) – an autonomous, multimodal, autoscaling database environment supporting both NoSQL and SQL.
Text mining is an advanced analytical approach used to make sense of Big Data that comes in textual forms such as emails, tweets, researches, and blog posts. NoSQL databases. NoSQL databases, also known as non-relational or non-tabular databases, use a range of data models for data to be accessed and managed. Apache Kafka.
There is no need for other frameworks to apply their “magic” on top of Apache Kafka ® but instead stay in the pure event-first paradigm. Brokered systems like Kafka provide huge buffers (the default in Kafka is two weeks) which negate the need for explicit flow control for the vast majority of use cases.
Finally, apart from your academic degree and extra skills, you can also learn to channel your skills practically by taking on small projects such as creating an app, writing blogs, or even exploring data analysis to gather more information. KafkaKafka is an open-source processing software platform.
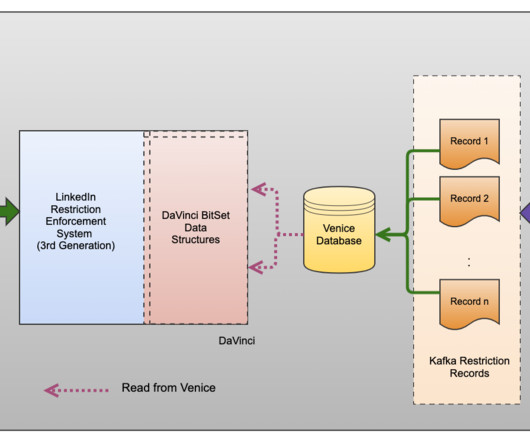
In a previous blog post, we talked about how we built our anti-abuse platform using CASAL. In this blog post, we'll go deeper into how we manage account restrictions. Espresso’s tight integration with LinkedIn’s Brooklin –a near real-time data streaming framework–enabled seamless data streaming through Kafka messages.
We even open-sourced the code and wrote a detailed blog post about how we built our serverless analytics app on clickstream data , because that's what we love. SQL over NoSQL SQL is making a strong comeback with more modern systems embracing SQL and an overwhelming 84% of respondents preferring SQL over NoSQL.
It serves as a foundation for the entire data management strategy and consists of multiple components including data pipelines; , on-premises and cloud storage facilities – data lakes , data warehouses , data hubs ;, data streaming and Big Data analytics solutions ( Hadoop , Spark , Kafka , etc.);
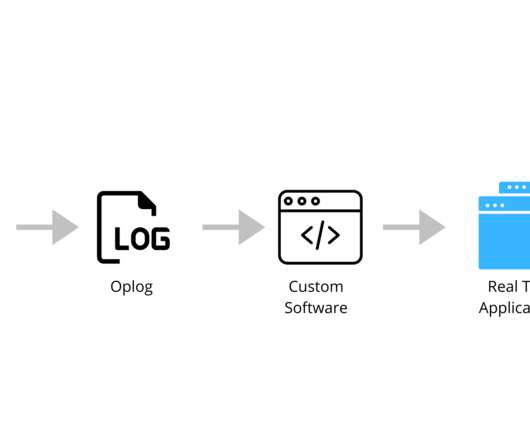
According to over 40,000 developers, MongoDB is the most popular NOSQL database in use right now. This blog post will look at three of them: tailing MongoDB with an oplog, using MongoDB change streams, and using a Kafka connector. MongoDB has a Kafka connector that can sync data in both directions.
CDC with Update Timestamps and Kafka One of the simplest ways to implement a CDC solution in both MySQL and Postgres is by using update timestamps. Kafka Connect also has connectors to target systems that can then write these records for you. To simplify this process we can use Kafka Connect.
In the previous blog posts, we looked at application development concepts and how Cloudera Operational Database (COD) interacts with other CDP services. In this blog post, let us see how easy it is to create a COD instance, and deploy a sample application that runs on that COD instance. . Apache HBase (NoSQL), Java, Maven: Read-Write.
Release – The first major release of NoSQL database in five years! Rack-aware Kafka streams – Kafka has already been rack-aware for a while, which gives its users more confidence. 5 Reasons to Choose Pulsar Over Kafka – The author states his bias upfront, which is nice. Cassandra 4.0
Release – The first major release of NoSQL database in five years! Rack-aware Kafka streams – Kafka has already been rack-aware for a while, which gives its users more confidence. 5 Reasons to Choose Pulsar Over Kafka – The author states his bias upfront, which is nice. Cassandra 4.0
NoSQL – This alternative kind of data storage and processing is gaining popularity. The term “NoSQL” refers to technology that is not dependent on SQL, to put it simply. Kafka – Kafka is an open-source framework for processing that can handle real-time data flows.
A common thread in many MongoDB and broader NoSQL discussions is the tight coupling between schema design and query patterns. The blog explains how to use single field indexes and compound indexes in the MongoDB context. Change Streams An Introduction to Change Streams The final recommendation comes from the MongoDB blog itself.
Databases and Data Warehousing: Engineers need in-depth knowledge of SQL (88%) and NoSQL databases (71%), as well as data warehousing solutions like Hadoop (61%). Data Pipeline Tools: Familiarity with tools such as Apache Kafka (mentioned in 71% of job postings) and Apache Spark (66%) is vital.
Databases and Data Warehousing: Engineers need in-depth knowledge of SQL (88%) and NoSQL databases (71%), as well as data warehousing solutions like Hadoop (61%). Data Pipeline Tools: Familiarity with tools such as Apache Kafka (mentioned in 71% of job postings) and Apache Spark (66%) is vital.
Folks have definitely tried, and while Apache Kafka® has become the standard for event-driven architectures, it still struggles to replace your everyday PostgreSQL database instance in the modern application stack. You can learn more about Confluent vs. Kafka over on Confluent’s site.
Our esteemed roundtable included leading practitioners, thought leaders and educators in the space, including: Ben Rogojan , aka Seattle Data Guy , is a data engineering and data science consultant (now based in the Rocky Mountain city of Denver) with a popular YouTube channel , Medium blog , and newsletter.
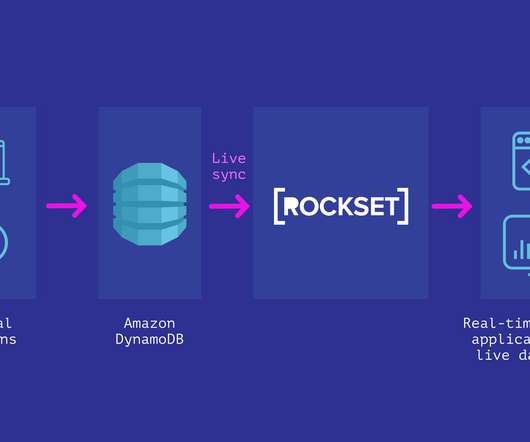
In this blog post I compare options for real-time analytics on DynamoDB - Elasticsearch , Athena, and Spark - in terms of ease of setup, maintenance, query capability, latency. DynamoDB has been one of the most popular NoSQL databases in the cloud since its introduction in 2012.
The new databases that have emerged during this time have adopted names such as NoSQL and NewSQL, emphasizing that good old SQL databases fell short when it came to meeting the new demands. Apache Cassandra is one of the most popular NoSQL databases. Kafka Streams supports fault-tolerant stateful applications.
Database management: Data engineers should be proficient in storing and managing data and working with different databases, including relational and NoSQL databases. Data processing: Data engineers should know data processing frameworks like Apache Spark, Hadoop, or Kafka, which help process and analyze data at scale.
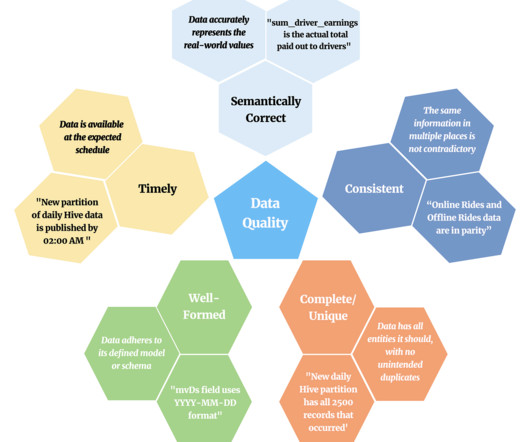
Finally, as the subject of this blog post, we can assess data quality via batch compute analytics on our data warehouse, providing a comprehensive albeit slower evaluation compared to the previously mentioned methods. These flow through Kafka , our event streaming platform, before being processed by Flink , our streaming compute framework.
We'll be publishing more posts in the series in the near future, so subscribe to our blog so you don't miss them! A platform such as Apache Kafka/Confluent , Spark or Amazon Kinesis for publishing that stream of event data. The event systems captured IoT and web events and stored them as log files.
In this blog post, we’ll discuss several other targeted strategies that we can use to speed up those problematic queries when the right circumstances are present. Just like relational databases, NoSQL databases like MongoDB also utilize indexes to speed up queries. Thus, MongoDB did not need to scan any collection documents at all.
Big Data Frameworks : Familiarity with popular Big Data frameworks such as Hadoop, Apache Spark, Apache Flink, or Kafka are the tools used for data processing. Implement ETL & Data Pipelines with Bash, Airflow & Kafka; architect, populate, deploy Data Warehouses; create BI reports & interactive dashboards.
For a data engineer career, you must have knowledge of data storage and processing technologies like Hadoop, Spark, and NoSQL databases. Understanding of Big Data technologies such as Hadoop, Spark, and Kafka. Knowledge of Hadoop, Spark, and Kafka. Read blogs, attend webinars, and take online courses.
Cloud Computing Cloud computing courses focus on deploying and managing big data platforms like Hadoop, Spark, Kafka etc on cloud infrastructure. Students work with SQL, NoSQL databases, Hadoop ecosystem, Spark, Kafka etc. Capstone projects involve analyzing company data to drive business strategy and decisions.
As open source technologies gain popularity at a rapid pace, professionals who can upgrade their skillset by learning fresh technologies like Hadoop, Spark, NoSQL, etc. Learning big data technologies will help Singaporeans fulfil the demand vs. supply shortage for analytics skills like Hadoop, Spark, Machine Learning, Cassandra, NoSQL, etc.
This blog helps you understand more about the data engineer salary in US. After the inception of databases like Hadoop and NoSQL, there's a constant rise in the requirement for processing unstructured or semi-structured data. Hope this blog gives you a clear understanding of data engineer salary in USA.
This blog compiles real-time data predictions from industry leaders so you know what’s coming in 2023. Move from batch-based stacks to real-time streaming data stacks Pairing an event streaming platform like Confluent Kafka or Kinesis with a batch-based data warehouse limits the value of the data to the organization.
Analytics on DynamoDB While NoSQL databases like DynamoDB generally have excellent scaling characteristics, they support only a limited set of operations that are focused on online transaction processing. As an operational database, DynamoDB is optimized for real-time transactions even when deployed across multiple geographic locations.
Deepak regularly shares blog content and similar advice on LinkedIn. She also runs dutchengineer.org, which features a blog and newsletter full of tips for landing your dream job in data science, and offers digital courses and one-on-one mentoring for data scientists and data engineers.
Translating the commands from source to target can be tricky especially if you’re capturing changes to a SQL database and reflecting them in a NoSQL database, as the way commands are written are different. Reference Debezium Architecture To handle the queuing of changes, Debezium uses Kafka.
” We hope that this blog post will solve all your queries related to crafting a winning LinkedIn profile. Highlight the Big Data Analytics Tools and Technologies You Know The world of analytics and data science is purely skills-based and there are ample skills and technologies like Hadoop, Spark, NoSQL, Python, R, Tableau, etc.
This blog will walk through the most popular and fascinating open source big data projects. CMAK Source: Github CMAK stands for Cluster Manager for Apache Kafka , previously known as Kafka Manager, is a tool for managing Apache Kafka clusters. CMAK is developed to help the Kafka community.
This blog covers the top 50 most frequently asked Azure interview questions and answers. Well, this Azure interview questions and answers blog will help you land your dream cloud computing job role! It is a cloud-based NoSQL database that deals mainly with modern app development. So, let's dive right into it!
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content