This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Aggregator Leaf Tailer (ALT) is the data architecture favored by web-scale companies, like Facebook, LinkedIn, and Google, for its efficiency and scalability. In this blog post, I will describe the Aggregator Leaf Tailer architecture and its advantages for low-latency data processing and analytics.
This blog post is my note after reading the paper: The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded, Out-of-Order Data Processing. In the rest of this blog, we will see how Google enables this contribution. Triggering at completion estimates such as watermarks.
In the past, we often used lambdaarchitecture for processing jobs, meaning that our developers used two different systems for batch and stream processing. In this blog post, we will share our progress, challenges, and lessons learned from implementing Apache Beam.
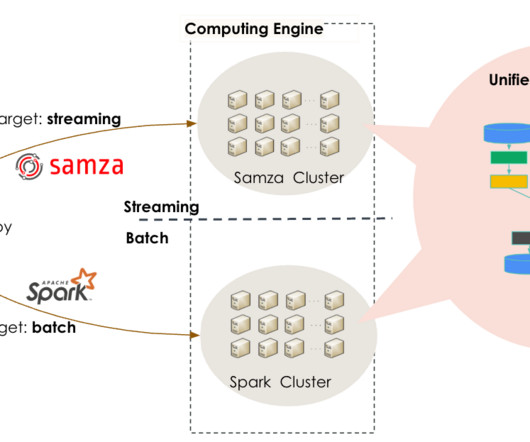
This framework, along with Apache Spark for batch processing, formed the basis of LinkedIn’s lambdaarchitecture for data processing jobs. The lambdaarchitecture approach led to operational complexity and inefficiencies, because it required maintaining two different codebases and two different engines for batch and streaming data.
For future work, we are looking into both more efficient and scalable data storage solutions, such as event compression or online-offline lambdaarchitecture, as well as more scalable online model inference capability integrated into the streaming platform. To explore life at Pinterest, visit our Careers page.
Data streamed in is queryable in conjunction with historical data, avoiding need for LambdaArchitecture. Figure 1 below shows a standard architecture for a Real-Time Data Warehouse. In addition, we have a webinar and blog explaining how you can use Apache Kudu and Apache Impala to create a time series application within CDP.
Embedded content: [link] We'll be doing more videos like this in the future, so sign up for notices from our blog and join our community so you don't miss them.
Lambdaarchitecture: A combination of both batch and real-time processing, the lambdaarchitecture has three layers. The lambdaarchitecture ensures completeness of data with minimal latency. In this blog, we discussed how it benefits business in the long run.
We'll be publishing more posts in the series in the near future, so subscribe to our blog so you don't miss them! LambdaArchitecture: Too Many Compromises A decade ago, a multitiered database architecture called Lambda began to emerge. Google and other web-scale companies also use ALT.
It talks about how to get adoption in your organization, a sample implementation, and the contract-driven architecture. link] Capital One: Democratizing machine learning It is an exciting blog post + video interview from Capital One focusing on the people and technology aspect of democratizing the machine learning practice across the org.
And, out of these professions, this blog will discuss the data engineering job role. The current architecture is called Lambdaarchitecture, where you can handle both real-time streaming data and batch data. The data engineering projects mentioned in this blog might seem challenging.
The blog highlights that the job is not just writing SQL but providing a strategic business solution for an organization. The blog is very educative for me about measuring the lifetime value of a customer and segmentation on buying behavior. The BTYD model is excellent for building a recommendation engine and marketing personalization.
This project is a LambdaArchitecture program that tracks Chicago's streets' traffic conditions, including congestion and safety. Recommendation System Online services often provide access to thousands, millions, or even billions of items, including goods, advertisements, video clips, movies, music, blog entries, and so forth.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















Let's personalize your content