This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It leverages knowledge graphs to keep track of all the data sources and data flows, using AI to fill the gaps so you have the most comprehensive metadata management solution. Together, Cloudera and Octopai will help reinvent how customers manage their metadata and track lineage across all their data sources.
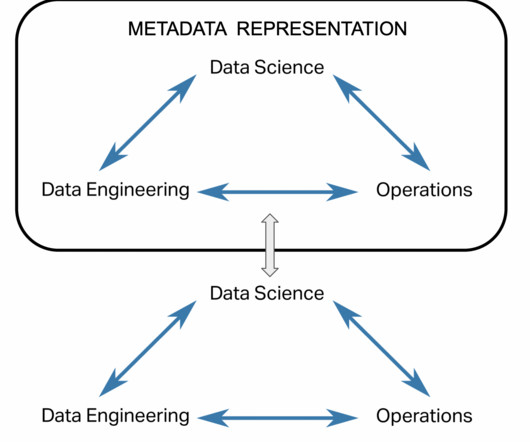
Summary Metadata is the lifeblood of your data platform, providing information about what is happening in your systems. In order to level up their value a new trend of active metadata is being implemented, allowing use cases like keeping BI reports up to date, auto-scaling your warehouses, and automated data governance.
As an important part of achieving better scalability, Ozone separates the metadata management among different services: . Ozone Manager (OM) service manages the metadata of the namespace such as volume, bucket and keys. Datanode service manages the metadata of blocks, containers and pipelines running on the datanode. .
In this blog, we will delve into an early stage in PAI implementation: data lineage. This took Meta multiple years to complete across our millions of disparate data assets, and well cover each of these more deeply in future blog posts: Inventorying involves collecting various code and data assets (e.g.,
And for that future to be a reality, data teams must shift their attention to metadata, the new turf war for data. The need for unified metadata While open and distributed architectures offer many benefits, they come with their own set of challenges. Data teams actually need to unify the metadata. Open data is the future.
This will allow a data office to implement access policies over metadata management assets like tags or classifications, business glossaries, and data catalog entities, laying the foundation for comprehensive data access control. First, a set of initial metadata objects are created by the data steward.
The blog highlights how moving from 6-character base-64 to 20-digit base-2 file distribution brings more distribution in S3 and reduces request failures. The blog is a good summary of how to use Snowflake QUERY_TAG to measure and monitor query performance. The blog post made me curious to understand DataFusion's internals.
In August, we wrote about how in a future where distributed data architectures are inevitable, unifying and managing operational and business metadata is critical to successfully maximizing the value of data, analytics, and AI. It is a critical feature for delivering unified access to data in distributed, multi-engine architectures.
Managing metadata has become crucial to any organization’s data strategy in today’s data-driven world. This is where metadata management tools come into play. Nowadays, businesses face the challenge of effectively managing their growing and complex data volumes.
And specifically, I was reading one of your blog posts recently that talked about the dark ages of data. It could be metadata that you weren’t capturing before. The post The Struggle Between Data Dark Ages and LLM Accuracy appeared first on Cloudera Blog. Here are some key takeaways from Ray in that conversation.
To tackle the problem, we attach a piece of model version metadata to each ANN search service host, which contains a mapping from model name to the latest model version. The metadata is generated together with the index. It has the top user coverage and top three save rates.
A Guest Post by Ole Olesen-Bagneux In this blog post I would like to describe a new data team, that I call ‘the data discovery team’. And that is what the data discovery team that I propose in this blog post should work on: searching for data. In an enterprise data reality, searching for data is a bit of a hassle.
In this blog, we will go through the technical design and share some offline and online results for our LLM-based search relevance pipeline. Pin Text Representations Pins on Pinterest are rich multimedia entities that feature images, videos, and other contents, often linked to external webpages or blogs.
In this blog, well address this challenge by building a metadata-driven solution using a JavaScript stored procedure that dynamically maps and loads only the required columns from multiple CSV files into their respective Snowflake tables. Metadata Proc Step 4: Execute the Stored Procedure.
This blog post expands on that insightful conversation, offering a critical look at Iceberg's potential and the hurdles organizations face when adopting it. This ecosystem includes: Catalogs: Services that manage metadata about Iceberg tables (e.g., If not handled correctly, managing this metadata can become a bottleneck.
Metadata is the information that provides context and meaning to data, ensuring it’s easily discoverable, organized, and actionable. This is what managing data without metadata feels like. This is what managing data without metadata feels like. Effective metadata management is no longer a luxury—it’s a necessity.
Below a diagram describing what I think schematises data platforms: Data storage — you need to store data in an efficient manner, interoperable, from the fresh to the old one, with the metadata. It adds metadata, read, write and transactions that allow you to treat a Parquet file as a table.
This is part of our series of blog posts on recent enhancements to Impala. Metadata Caching. As Impala’s adoption grew the catalog service started to experience these growing pains, therefore recently we introduced two new features to alleviate the stress, On-demand Metadata and Zero Touch Metadata. More on this below.
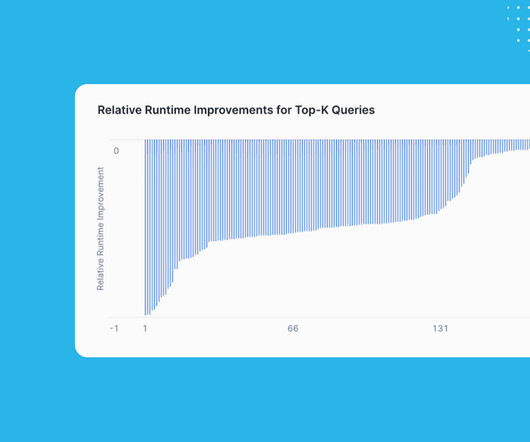
As we describe in this blog post , the top-k feature uses runtime information — namely, the current contents of the top-k elements — to skip micro-partitions where we can guarantee that they won’t contribute to the overall result. on average, with some queries also reaching up to 99.8% improvement. How does it work?
With this public preview, those external catalog options are either “GLUE”, where Snowflake can retrieve table metadata snapshots from AWS Glue Data Catalog, or “OBJECT_STORE”, where Snowflake retrieves metadata snapshots directly from the specified cloud storage location. With these three options, which one should you use?
Since the previous stable version ( 0.3.1 ), efforts have been made on three principal fronts: tooling (in particular the language server), the core language semantics (contracts, metadata, and merging), and the surface language (the syntax and the stdlib). The | symbol attaches metadata to fields.
The blog emphasizes the importance of starting with a clear client focus to avoid over-engineering and ensure user-centric development. link] Gunnar Morling: Revisiting the Outbox Pattern The blog is an excellent summary of the path we crossed with the outbox pattern and the challenges ahead.
Summary The majority of blog posts and presentations about data engineering and analytics assume that the consumers of those efforts are internal business users accessing an environment controlled by the business. Atlan is the metadata hub for your data ecosystem. Atlan is the metadata hub for your data ecosystem.
In this blog, I will demonstrate the value of Cloudera DataFlow (CDF) , the edge-to-cloud streaming data platform available on the Cloudera Data Platform (CDP) , as a Data integration and Democratization fabric. Data and Metadata: Data inputs and data outputs produced based on the application logic. Introduction.
In this blog, we will discuss: What is the Open Table format (OTF)? Then, we add another column called HASHKEY , add more data, and locate the S3 file containing metadata for the iceberg table. In the screenshot below, we can see that the metadata file for the Iceberg table retains the snapshot history. Why should we use it?
In our previous blogs, we explored how Picnics Page Platform transformed the way we build new featuresenabling faster iteration, tighter collaboration and less feature-specific complexity. In this blog, well dive into how we configure the pages within Picnics store. Now, were bringing this same principle to our app.
All the above commands are very likely to be described in separate future blog posts, but right now let’s focus on the dataflow sample command. This logic consists of the following parts: DDL code, table metadata information, data transformation and a few audit steps.
This blog is a collection of those insights, but for the full trendbook, we recommend downloading the PDF. VP of Architecture, Healthcare Industry Organizations will focus more on metadata tagging of existing and new content in the coming years. The technology for metadata management, data quality management, etc., No problem!
In this blog post, we’ll explore key strategies that data teams should adopt to prepare for the year ahead. Establish shared guidelines for data governance, including data quality, metadata management, and access controls. Implement CI/CD practices to ensure continuous delivery of data products.
It supports “fuzzy” search — the service takes in natural language queries and returns the most relevant text results, along with associated metadata. More details on the research behind the Cortex Search retrieval stack will be shared on our Snowflake Engineering Blog.
In this blog post, we will ingest a real world dataset into Ozone, create a Hive table on top of it and analyze the data to study the correlation between new vaccinations and new cases per country using a Spark ML Jupyter notebook in CML. Learn more about the impacts of global data sharing in this blog, The Ethics of Data Exchange.
It covers nine categories: storage systems, data lake platforms, processing, integration, orchestration, infrastructure, ML/AI, metadata management, and analytics. I found the blog to be a comprehensive roadmap for data engineering in 2025.
We expand on this feature later in this blog. Atlas / Kafka integration provides metadata collection for Kafa producers/consumers so that consumers can manage, govern, and monitor Kafka metadata and metadata lineage in the Atlas UI. Figure 8: Data lineage based on Kafka Atlas Hook metadata. x, and 6.3.x,
The blog explains KIP-932 and its potential benefits. link] Picnic: Open-sourcing dbt-score: lint model metadata with ease! The more metadata there is, the more readability of the model. It is often challenging as developers are not incentivized to produce quality metadata.
I honestly don’t have a solid answer, but this blog is an excellent overview of upskilling. [link] Georg Heiler: Upskilling data engineers What should I prefer for 2028, or how can I break into data engineering? These are common LinkedIn requests.
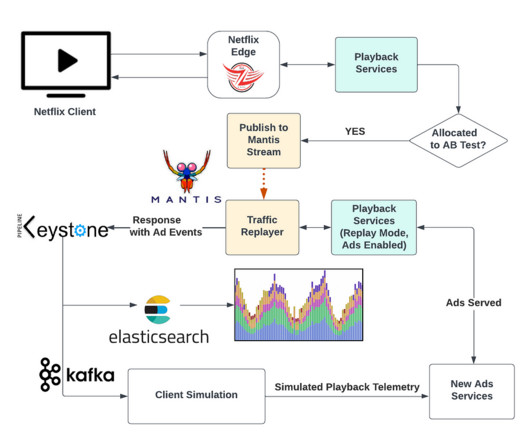
In this blog post, we’ll discuss the methods we used to ensure a successful launch, including: How we tested the system Netflix technologies involved Best practices we developed Realistic Test Traffic Netflix traffic ebbs and flows throughout the day in a sinusoidal pattern. Basic with ads was launched worldwide on November 3rd.
Contact Info LinkedIn Blog Parting Question From your perspective, what is the biggest gap in the tooling or technology for data management today? TimeXtender Logo]([link] TimeXtender is a holistic, metadata-driven solution for data integration, optimized for agility. When is a data mesh the wrong choice?
Companies such as Adobe , Expedia , LinkedIn , Tencent , and Netflix have published blogs about their Apache Iceberg adoption for processing their large scale analytics datasets. . In CDP we enable Iceberg tables side-by-side with the Hive table types, both of which are part of our SDX metadata and security framework.
In this three-part blog post series, we introduce you to Psyberg , our incremental data processing framework designed to tackle such challenges! It leverages Iceberg metadata to facilitate processing incremental and batch-based data pipelines. Given our role on this critical path, accuracy is paramount. Psyberg: The Game Changer!
Better Metadata Management Add Descriptions and Data Product tags to tables and columns in the Data Catalog for improved governance. Smarter Profiling & Test Generation Improved logic reduces false positives , making test results more accurate and actionable. DataOps just got more intelligent.
Fueled by businesses demand for democratized, self-service data, these architectures rely on effective metadata management and data governance for success. And, stay tuned for the next 2025 Planning Insights blog to explore more report highlights! It follows that 25% of respondents identify a data catalog as a top priority for 2024.
The Grab blog delights me since I have tried to do this many times. A cross-encoder teacher model, fine-tuned on human-labeled data and enriched Pin metadata, was distilled into a lightweight student model using semi-supervised learning over billions of impressions. Kudos to the Grab team for building a docs-as-code system.
Observability for your most secure data For your most sensitive, protected data, we understand even the metadata and telemetry about your workloads must be kept under close watch, and it must stay within your secured environment. The post Introducing Cloudera Observability Premium appeared first on Cloudera Blog.
By Abhinaya Shetty , Bharath Mummadisetty In the inaugural blog post of this series, we introduced you to the state of our pipelines before Psyberg and the challenges with incremental processing that led us to create the Psyberg framework within Netflix’s Membership and Finance data engineering team.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content