This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The blog emphasizes the importance of starting with a clear client focus to avoid over-engineering and ensure user-centric development. link] Gunnar Morling: Revisiting the Outbox Pattern The blog is an excellent summary of the path we crossed with the outbox pattern and the challenges ahead.
With Astro, you can build, run, and observe your data pipelines in one place, ensuring your mission critical data is delivered on time. This blog captures the current state of Agent adoption, emerging software engineering roles, and the use case category. link] Jack Vanlightly: Table format interoperability, future or fantasy?
This introductory blog focuses on an overview of our journey. Future blogs will provide deeper dives into each service, sharing insights and lessons learned from this process. Future blogs will provide deeper dives into each service, sharing insights and lessons learned from this process.
Collects and aggregates metadata from components and present cluster state. Metadata in cluster is disjoint across components. Look at details of volumes/buckets/keys/containers/pipelines/datanodes. Given a file, find out what nodes/pipeline is it part of. No one component can compute overall state of the cluster.
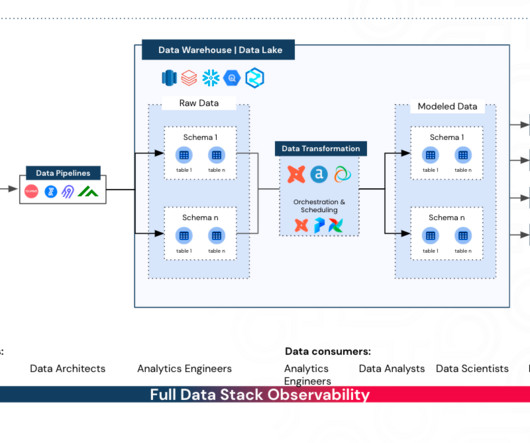
The fact that ETL tools evolved to expose graphical interfaces seems like a detour in the history of data processing, and would certainly make for an interesting blog post of its own. Data is simply too centric to the company’s activity to have limitation around what roles can manage its flow.
Kubernetes is a container-centric management software that allows the creation and deployment of containerized applications with ease. apiVersion: v1 kind: Pod metadata: name: Postgres spec: containers: - name: Postgres image: Postgres: 3.1 Here is a sample YAML file used to create a pod with the postgres database.
Take Astro (the fully managed Airflow solution) for a test drive today and unlock a suite of features designed to simplify, optimize, and scale your data pipelines. The blog is a good overview of various components in a typical data stack. The blog narrates the shift-left approach in data governance with three critical principles.
Data engineers spend countless hours troubleshooting broken pipelines. Data plays a central role in modern organisations; the centricity here is not just a figure of speech, as data teams often sit between traditional IT and different business functions. More can be found in this blog. But what do data quality issues look like?
Metadata Management Metadata, or ‘data about data’, is a crucial component of data management. Data lineage tools provide robust metadata management capabilities, allowing businesses to capture, store, and manage metadata associated with their data. This fosters a data-driven culture within the organization.
Editors Note: 🔥 DEW is thrilled to announce a developer-centric Data Eng & AI conference in the tech hub of Bengaluru, India, on October 12th! LinkedIn write about Hoptimator for auto generated Flink pipeline with multiple stages of systems. See how it works today. Write SQL queries without learning SQL?
Treating data as a product is more than a concept; it’s a paradigm shift that can significantly elevate the value that business intelligence and data-centric decision-making have on the business. Data pipelines Data integrity Data lineage Data stewardship Data catalog Data product costing Let’s review each one in detail.
Whether it’s streaming, batch, virtualized or not, using active metadata, or just plain old regular coding, it provides a good way for the data and analytics team to add continuous value to the organization.”. Be business-centric. Bergh added, “ DataOps is part of the data fabric. Education is the Biggest Challenge.
Furthermore, pipelines built downstream of core_data created a proliferation of duplicative and diverging metrics. When a metric is defined in Minerva, authors are required to provide important self-describing metadata. The tool clearly shows the step-by-step computation the Minerva pipeline will follow to generate the output.
Chad writes on data management, contracts, and products on his Substack blog and serves as an advisor and investor to several startups. She regularly contributes to IBM’s Journey to AI blog and shares her advice on LinkedIn around data strategy, data science, women in AI, data and analytics, data governance, and artificial intelligence.
This typically results in long-running ETL pipelines that cause decisions to be made on stale or old data. Business-Focused Operation Model: Teams can shed countless hours of managing long-running and complex ETL pipelines that do not scale. This enables an automated continuous integration/continuous deployment system (CI/CD).
Storing events in a stream and connecting streams via stream processors provide a generic, data-centric, distributed application runtime that you can use to build ETL, event streaming applications, applications for recording metrics and anything else that has a real-time data requirement. Payment processing pipeline. Event flow model.
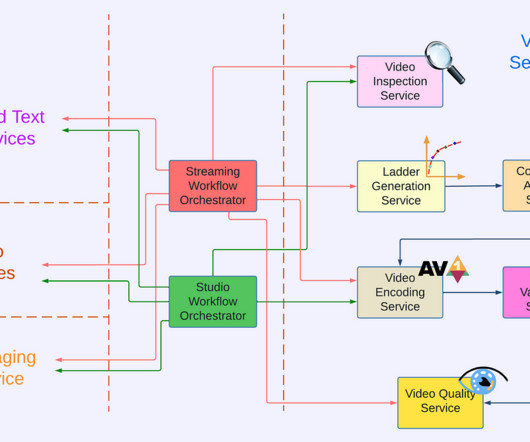
The article discusses common pitfalls such as absence bias and intervention bias while advocating for a user-centric approach that emphasizes evaluating retrieval accuracy through precision and recall, focusing on recall. link] BlaBlaCar: Data Pipelines Architecture at BlaBlaCar BlaBlaCar writes about its data pipeline architecture.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






















Let's personalize your content