This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Additionally, multiple copies of the same data locked in proprietary systems contribute to version control issues, redundancies, staleness, and management headaches. It leverages knowledge graphs to keep track of all the data sources and data flows, using AI to fill the gaps so you have the most comprehensive metadata management solution.
Modern large-scale recommendation systems usually include multiple stages where retrieval aims at retrieving candidates from billions of candidate pools, and ranking predicts which item a user tends to engage from the trimmed candidate set retrieved from early stages [2]. General multi-stage recommendation system design in Pinterest.
Summary Metadata is the lifeblood of your data platform, providing information about what is happening in your systems. A variety of platforms have been developed to capture and analyze that information to great effect, but they are inherently limited in their utility due to their nature as storage systems.
It is a critical and powerful tool for scalable discovery of relevant data and data flows, which supports privacy controls across Metas systems. In this blog, we will delve into an early stage in PAI implementation: data lineage. Data lineage enables us to efficiently navigate these assets and protect user data.
Shane diagrams Monte Carlo’s architecture, explaining how it uses agents, metadata, and query logs to provide lineage and monitor data health across complex stacks (Snowflake, Databricks, etc.). We then dive deep into Monte Carlo Data, defining data observability and the crucial concept of “data downtime” (TTD + TTR).
Meta’s vast and diverse systems make it particularly challenging to comprehend its structure, meaning, and context at scale. We discovered that a flexible and incremental approach was necessary to onboard the wide variety of systems and languages used in building Metas products. We believe that privacy drives product innovation.
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. In this blog, we will discuss: What is the Open Table format (OTF)? These systems are built on open standards and offer immense analytical and transactional processing flexibility.
It can manage billions of small and large files that are difficult to handle by other distributed file systems. As an important part of achieving better scalability, Ozone separates the metadata management among different services: . Ozone Manager (OM) service manages the metadata of the namespace such as volume, bucket and keys.
The key to those solutions is a robust and flexible metadata management system. LinkedIn has gone through several iterations on the most maintainable and scalable approach to metadata, leading them to their current work on DataHub. What were you using at LinkedIn for metadata management prior to the introduction of DataHub?
Summary The majority of blog posts and presentations about data engineering and analytics assume that the consumers of those efforts are internal business users accessing an environment controlled by the business. Atlan is the metadata hub for your data ecosystem. How is everyone going to find the data they need, and understand it?
And for that future to be a reality, data teams must shift their attention to metadata, the new turf war for data. The need for unified metadata While open and distributed architectures offer many benefits, they come with their own set of challenges. Data teams actually need to unify the metadata. Open data is the future.
The blog highlights how moving from 6-character base-64 to 20-digit base-2 file distribution brings more distribution in S3 and reduces request failures. The blog is a good summary of how to use Snowflake QUERY_TAG to measure and monitor query performance.
In August, we wrote about how in a future where distributed data architectures are inevitable, unifying and managing operational and business metadata is critical to successfully maximizing the value of data, analytics, and AI. It is a critical feature for delivering unified access to data in distributed, multi-engine architectures.
The Kafka Streams API boasts a number of capabilities that make it well suited for maintaining the global state of a distributed system. At Imperva, we took advantage of Kafka Streams to build shared state microservices that serve as fault-tolerant, highly available single sources of truth about the state of objects in our system.
This will allow a data office to implement access policies over metadata management assets like tags or classifications, business glossaries, and data catalog entities, laying the foundation for comprehensive data access control. First, a set of initial metadata objects are created by the data steward.
In this blog post, we will talk about a single Ozone cluster with the capabilities of both Hadoop Core File System (HCFS) and Object Store (like Amazon S3). A unified storage architecture that can store both files and objects and provide a flexible, scalable, and high-performance system. Bucket types. release version.
This blog post expands on that insightful conversation, offering a critical look at Iceberg's potential and the hurdles organizations face when adopting it. Hadoop achieved this through distributed processing and storage, using a framework called MapReduce and the Hadoop Distributed File System (HDFS). Trino, Spark, Snowflake, DuckDB).
In this blog, we will go through the technical design and share some offline and online results for our LLM-based search relevance pipeline. Pin Text Representations Pins on Pinterest are rich multimedia entities that feature images, videos, and other contents, often linked to external webpages or blogs.
link] LinkedIn: Powering Apache Pinot ingestion with Hoptimator LinkedIn discusses Hoptimator, a system that enables consumer-driven, managed ingestion pipelines, specifically for Apache Pinot. It highlights the benefits of committing the leader epoch alongside the offset.
The blog took out the last edition’s recommendation on AI and summarized the current state of AI adoption in enterprises. The simplistic model expressed in the blog made it easy for me to reason about the transactional system design. Kafka is probably the most reliable data infrastructure in the modern data era.
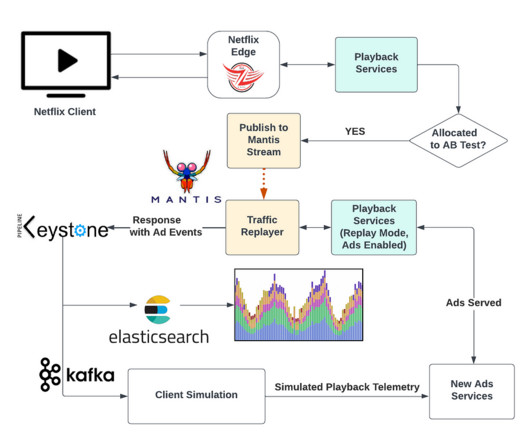
In this blog post, we’ll discuss the methods we used to ensure a successful launch, including: How we tested the system Netflix technologies involved Best practices we developed Realistic Test Traffic Netflix traffic ebbs and flows throughout the day in a sinusoidal pattern. Basic with ads was launched worldwide on November 3rd.
Metadata is the information that provides context and meaning to data, ensuring it’s easily discoverable, organized, and actionable. Imagine a library with millions of books but no catalog system to organize them. This is what managing data without metadata feels like. What is Metadata? Chaos, right?
Foundation Capital: A System of Agents brings Service-as-Software to life software is no longer simply a tool for organizing work; software becomes the worker itself, capable of understanding, executing, and improving upon traditionally human-delivered services. It's good to know about Dapr and restate.dev.
It requires a state-of-the-art system that can track and process these impressions while maintaining a detailed history of each profiles exposure. In this multi-part blog series, we take you behind the scenes of our system that processes billions of impressions daily.
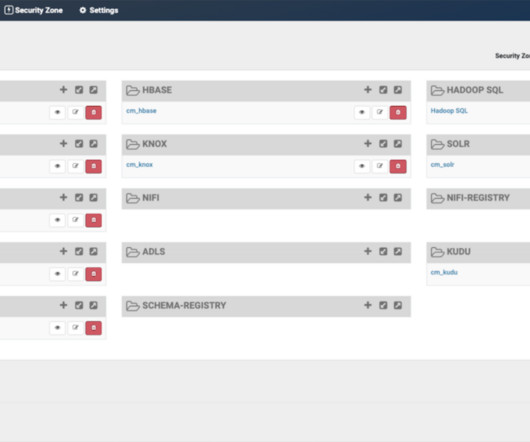
We are pleased to announce that Cloudera has been named a Leader in the 2022 Gartner ® Magic Quadrant for Cloud Database Management Systems. Many of our customers use multiple solutions—but want to consolidate data security, governance, lineage, and metadata management, so that they don’t have to work with multiple vendors.
This is part of our series of blog posts on recent enhancements to Impala. The commonly-accepted best practice in database system design for years is to use an exhaustive search strategy to consider all the possible variations of specific database operations in a query plan. Metadata Caching. More on this below.
In this blog post, we will explore the mitigation techniques that Snowflake offers, which fall into two categories: the Snowflake platform's default capabilities, which require no customer implementation, and capabilities that require customer implementation. Fail-Safe is not a new capability.
This blog is a collection of those insights, but for the full trendbook, we recommend downloading the PDF. Strong data governance also lays the foundation for better model performance, cost efficiency, and improved data quality, which directly contributes to regulatory compliance and more secure AI systems. No problem!
In this blog post, we’ll explore what CDC is, why it’s important, and our journey of implementing Generic CDC solutions for all online databases at Pinterest. This is crucial for applications that require up-to-date information, such as fraud detection systems or recommendation engines. What is Change Data Capture?
In our previous blogs, we explored how Picnics Page Platform transformed the way we build new featuresenabling faster iteration, tighter collaboration and less feature-specific complexity. In this blog, well dive into how we configure the pages within Picnics store. Now, were bringing this same principle to our app.
That’s a dangerous mistake: with the advent of IaC for the cloud, configuration has become an important aspect of modern software systems, and a critical point of failure. A REPL nickel repl , a markdown documentation generator nickel doc and a nickel query command to retrieve metadata, types and contracts from code.
It covers nine categories: storage systems, data lake platforms, processing, integration, orchestration, infrastructure, ML/AI, metadata management, and analytics. I found the blog to be a comprehensive roadmap for data engineering in 2025. Let me know in the comments. link] All rights reserved ProtoGrowth Inc, India.
This will allow a data office to implement access policies over metadata management assets like tags or classifications, business glossaries, and data catalog entities, laying the foundation for comprehensive data access control. First, a set of initial metadata objects are created by the data steward.
In this blog post, we’ll explore key strategies that data teams should adopt to prepare for the year ahead. On average, engineers spend over half of their time maintaining existing systems rather than developing new solutions. Instead of driving innovation, data engineers often find themselves bogged down with maintenance tasks.
What are the technical systems that you are relying on to power the different data domains? What is your philosophy on enforcing uniformity in technical systems vs. relying on interface definitions as the unit of consistency? What are the technical systems that you are relying on to power the different data domains?
In this blog, I will demonstrate the value of Cloudera DataFlow (CDF) , the edge-to-cloud streaming data platform available on the Cloudera Data Platform (CDP) , as a Data integration and Democratization fabric. Data and Metadata: Data inputs and data outputs produced based on the application logic. Introduction.
Behind the scenes, a myriad of systems and services are involved in orchestrating the product experience. These backend systems are consistently being evolved and optimized to meet and exceed customer and product expectations. This blog series will examine the tools, techniques, and strategies we have utilized to achieve this goal.
Thanks to the Netflix internal lineage system (built by Girish Lingappa ) Dataflow migration can then help you identify downstream usage of the table in question. All the above commands are very likely to be described in separate future blog posts, but right now let’s focus on the dataflow sample command.
I honestly don’t have a solid answer, but this blog is an excellent overview of upskilling. The author emphasizes the importance of mastering state management, understanding "local first" data processing (prioritizing single-node solutions before distributed systems), and leveraging an asset graph approach for data pipelines.
link] Jack Vanlightly: A Cost Analysis Of Replication Vs. S3 Express One Zone In Transactional Data Systems S3 Express One Zone, with low latency and write ops certainty, is promising. Replication-based systems remain more economical at low to medium throughputs, especially with significant cross-AZ data transfer discounts.
Yet, while retrieval is a fundamental component of any AI application stack, creating a high-quality, high-performance RAG system remains challenging for most enterprises. It supports “fuzzy” search — the service takes in natural language queries and returns the most relevant text results, along with associated metadata.
The article summarizes the recent macro trends in AI and data engineering, focusing on Vibe coding, human-in-the-loop system design, and rapid simplification of developer tooling. The Grab blog delights me since I have tried to do this many times. Kudos to the Grab team for building a docs-as-code system.
In this three-part blog post series, we introduce you to Psyberg , our incremental data processing framework designed to tackle such challenges! Late-arriving data is essentially delayed data due to system retries, network delays, batch processing schedules, system outages, delayed upstream workflows, or reconciliation in source systems.
In this blog post, we will ingest a real world dataset into Ozone, create a Hive table on top of it and analyze the data to study the correlation between new vaccinations and new cases per country using a Spark ML Jupyter notebook in CML. Learn more about the impacts of global data sharing in this blog, The Ethics of Data Exchange.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content