This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Unlocking Data Team Success: Are You Process-Centric or Data-Centric? We’ve identified two distinct types of data teams: process-centric and data-centric. We’ve identified two distinct types of data teams: process-centric and data-centric. They work in and on these pipelines.
With Astro, you can build, run, and observe your data pipelines in one place, ensuring your mission critical data is delivered on time. This blog captures the current state of Agent adoption, emerging software engineering roles, and the use case category. link] Jack Vanlightly: Table format interoperability, future or fantasy?
The blog emphasizes the importance of starting with a clear client focus to avoid over-engineering and ensure user-centric development. link] Gunnar Morling: Revisiting the Outbox Pattern The blog is an excellent summary of the path we crossed with the outbox pattern and the challenges ahead.
One thing that stands out to me is As AI-driven data workflows increase in scale and become more complex, modern data stack tools such as drag-and-drop ETL solutions are too brittle, expensive, and inefficient for dealing with the higher volume and scale of pipeline and orchestration approaches. We all bet on 2025 being the year of Agents.
CDP Data Engineering offers an all-inclusive toolset that enables data pipeline orchestration, automation, advanced monitoring, visual profiling, and a comprehensive management toolset for streamlining ETL processes and making complex data actionable across your analytic teams. . A key aspect of ETL or ELT pipelines is automation.
We have also seen a fourth layer, the Platinum layer , in companies’ proposals that extend the Data pipeline to OneLake and Microsoft Fabric. The need to copy data across layers, manage different schemas, and address data latency issues can complicate data pipelines. However, this architecture is not without its challenges.
However, that's also something we're re-thinking with our warehouse-centric strategy. Contact Info Kevin LinkedIn Blog Hanhan LinkedIn Parting Question From your perspective, what is the biggest gap in the tooling or technology for data management today? Let us know if you have opinions there!
The blog is an excellent summarization of the common patterns emerging in GenAI platforms. Adopting LLM in SQL-centric workflow is particularly interesting since companies increasingly try text-2-SQL to boost data usage. Pipeline breakpoint feature. A key highlight for me is the following features from Maestro.
At EVOLVE in Singapore, the Manila Electric Company, Meralco , won the Cloudera 2024 Data Impact Award in the Leadership and Transformation category for its customer-centric and data-driven transformation. The post The Global Impact of Cloudera in Our Daily Lives appeared first on Cloudera Blog. You can see the rest for yourself here.
The resulting solution was SnowPatrol, an OSS app that alerts on anomalous Snowflake usage, powered by ML Airflow pipelines. The performance issue impacts the users' productivity, and the blog explains how the data team built a custom LookML validator integrated with the IDE to improve its performance.
This introductory blog focuses on an overview of our journey. Future blogs will provide deeper dives into each service, sharing insights and lessons learned from this process. Future blogs will provide deeper dives into each service, sharing insights and lessons learned from this process.
Look at details of volumes/buckets/keys/containers/pipelines/datanodes. Given a file, find out what nodes/pipeline is it part of. Cloudera will publish separate blog posts with results of performance benchmarks. The post Apache Ozone and Dense Data Nodes appeared first on Cloudera Blog. Cisco Data Intelligence Platform.
NVidia released Eagle a vision-centric multimodal LLM — Look at the example in the Github repo, given an image and a user input the LLM is able to answer things like "Describe the image in detail" or "Which car in the picture is more aerodynamic" based on a drawing. How the UK football rely heavily on data?
Next, it needed to enhance the company’s customer-centric approach for a needs-based alignment of products and services. We are positive that our continuing partnership with Cloudera and Blutech Consulting will be foundational to our customer-centric approach, considerably improving our customer responsiveness,” he said.
For modern data engineers using Apache Spark, DE offers an all-inclusive toolset that enables data pipeline orchestration, automation, advanced monitoring, visual troubleshooting, and a comprehensive management toolset for streamlining ETL processes and making complex data actionable across your analytic teams. Job Deployment Made Simple.
These external partnerships along with our internal fashion specialists and labellers were fundamental in helping us design the experience from both a technical and human-centric perspective. To learn more about engineering at Pinterest, check out the rest of our Engineering Blog and visit our Pinterest Labs site.
This blog discusses quantifications, types, and implications of data. The activity in the field of learning with limited data is reflected in a variety of courses , workshops , reports , blogs and a large number of academic papers (a curated list of which can be found here ). Quantifications of data. Addressing the challenges of data.
To enable LGIM to better utilize its wealth of data, LGIM required a centralized platform that made internal data discovery easy for all teams and could securely integrate external partners and third-party outsourced data pipelines. The post Cloudera Customer Story appeared first on Cloudera Blog. Please read the full story here.
The data pipelines must contend with a high level of complexity – over seventy data sources and a variety of cadences, including daily/weekly updates and builds. Perhaps more importantly, data engineers and scientists may change any part of the automated pipelines related to data at any time. That’s the power of DataOps automation.
Since it’s all part of Snowflake’s single platform, data engineers and developers can also perform inference by programmatically calling the built-in or fine-tuned models, like in pipelines with Streams and Tasks or in applications. Learn More: Learn more about how Snowflake is building a data-centric platform for generative AI and LLM.
It involves many moving parts, from data preparation to building indexing and query pipelines. Building an indexing pipeline at scale with Kafka Connect. Moving data while adapting it to the requirements of your search product is a common integration point when building infrastructure like the one described in this blog post.
Data engineers spend countless hours troubleshooting broken pipelines. Data plays a central role in modern organisations; the centricity here is not just a figure of speech, as data teams often sit between traditional IT and different business functions. More can be found in this blog. But what do data quality issues look like?
2) Why High-Quality Data Products Beats Complexity in Building LLM Apps - Ananth Packildurai I will walk through the evolution of model-centric to data-centric AI and how data products and DPLM (Data Product Lifecycle Management) systems are vital for an organization's system. link] Nvidia: What Is Sovereign AI?
Take Astro (the fully managed Airflow solution) for a test drive today and unlock a suite of features designed to simplify, optimize, and scale your data pipelines. The blog is a good overview of various components in a typical data stack. The blog narrates the shift-left approach in data governance with three critical principles.
This blog post focuses on the scope and the goals of the recommendation system, and explores some of the most recent changes the Rider team has made to better serve Lyft’s riders. This blog mostly focuses on the mode selector to explain how rankings have evolved in the past years and briefly touches on the post request cross-sells.
The fact that ETL tools evolved to expose graphical interfaces seems like a detour in the history of data processing, and would certainly make for an interesting blog post of its own. Data is simply too centric to the company’s activity to have limitation around what roles can manage its flow.
It is amusing for a human being to write an article about artificial intelligence in a time when AI systems, powered by machine learning (ML), are generating their own blog posts. I frequently check Pipeline Runs and Sensor Ticks, but, often verify with Dagit.”
Data Engineering is typically a software engineering role that focuses deeply on data – namely, data workflows, data pipelines, and the ETL (Extract, Transform, Load) process. Data Engineers are engineers responsible for uncovering trends in data sets and building algorithms and data pipelines to make raw data beneficial for the organization.
Kubernetes is a container-centric management software that allows the creation and deployment of containerized applications with ease. To check if the Pod is running in the Kubernetes cluster: Command: kubectl get pods --watch --show-labels Learn more about DevOps and writing pipelines with the Best DevOps Courses Online.
These limited-term databases can be generated as needed from automated recipes (orchestrated pipelines and qualification tests) stored and managed within the process hub. . The data pipelines must contend with a high level of complexity – over seventy data sources and various cadences, including daily/weekly updates and builds.
In this blog, we will cover: About Python About Amazon About BeautifulSoup Library Hands-On Conclusion About Python Python is a high-level, interpreted, and versatile programming language known for its simplicity and readability. With its global reach and customer-centric approach, Amazon remains a top choice for online shopping worldwide.
Treating data as a product is more than a concept; it’s a paradigm shift that can significantly elevate the value that business intelligence and data-centric decision-making have on the business. Data pipelines Data integrity Data lineage Data stewardship Data catalog Data product costing Let’s review each one in detail.
This blog is for anyone who was interested but unable to attend the conference, or anyone interested in a quick summary of what happened there. Use cases such as fraud monitoring, real-time supply chain insight, IoT-enabled fleet operations, real-time customer intent, and modernizing analytics pipelines are driving development activity.
Pipeline-centric: Pipeline-centric Data Engineers collaborate with data researchers to maximize the use of the info they gather. Data Engineers focused on pipelines require a solid understanding of decentralized technology and computer engineering. They are frequently found in midsize businesses.
A curated list of the top 9 must read blogs on data. At the end of 2022 we decided to collect the blogs we enjoyed the most over the year. The data world is in turmoil and lots of exciting things happen every day, week and year. Happy reading!
Editors Note: 🔥 DEW is thrilled to announce a developer-centric Data Eng & AI conference in the tech hub of Bengaluru, India, on October 12th! LinkedIn write about Hoptimator for auto generated Flink pipeline with multiple stages of systems. See how it works today. Can't we use the vector feature in the existing databases?
In this blog post, we will see the top Automation testing tools used in the software industry. The seamless integration of this automation testing tool with CI/CD pipelines makes creating extremely complex automated tests easy without writing a single code line. The tool is easy to use and facilitates fast creation.
One paper suggests that there is a need for a re-orientation of the healthcare industry to be more "patient-centric". Furthermore, clean and accessible data, along with data driven automations, can assist medical professionals in taking this patient-centric approach by freeing them from some time-consuming processes.
Pharmaceuticals : Pharmaceutical companies need to integrate sensitive data, including Personally Identifiable Information (PII), across the R&D pipeline to accelerate the development of life-saving medications. Healthcare : Healthcare providers are under pressure to leverage data to deliver patient centricity and a continuum of care.
Notable Data Lineage Tools and Solutions Let’s take a look at several notable data lineage tools that can improve the quality and efficiency of your data pipeline. One of the unique features of Atlan is its human-centric design. This helps to enhance data quality, facilitate data governance, and enable regulatory compliance.
link] Tweet Search System (EarlyBird) Design [link] Google AI: Data-centric ML benchmarking - Announcing DataPerf’s 2023 challenges Data is the new code: it is the training data that determines the maximum possible quality of an ML solution. As the author points out, it is simply not a scalable approach.
It provides familiar APIs for various data centric tasks, including data preparation, cleansing, preprocessing, model training, and deployments tasks. In the warehouse model, users can seamlessly run and operationalize data pipelines, ML models, and data applications with user-defined functions (UDFs) and stored procedures (sprocs).
With One Lake serving as a primary multi-cloud repository, Fabric is designed with an open, lake-centric architecture. You can use Copilot to build reports, summarize insights, build pipelines, and develop ML models. This preview will roll out in stages.
Storing events in a stream and connecting streams via stream processors provide a generic, data-centric, distributed application runtime that you can use to build ETL, event streaming applications, applications for recording metrics and anything else that has a real-time data requirement. Payment processing pipeline. Event flow model.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











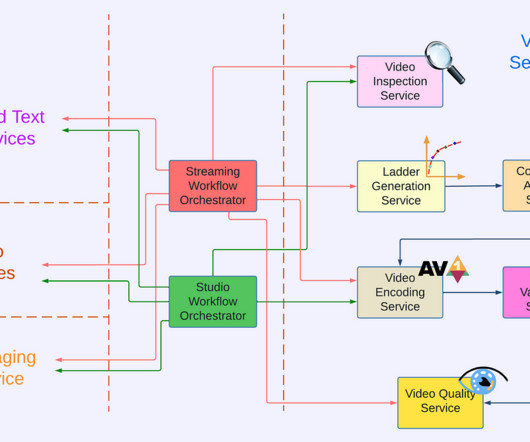




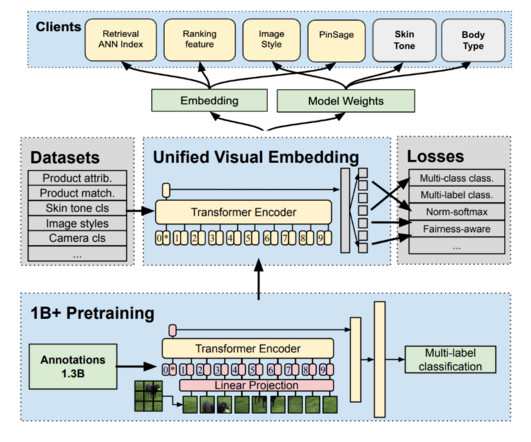





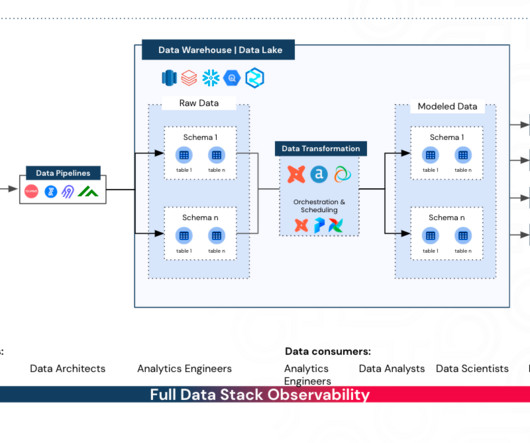



























Let's personalize your content