This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Unlocking Data Team Success: Are You Process-Centric or Data-Centric? We’ve identified two distinct types of data teams: process-centric and data-centric. We’ve identified two distinct types of data teams: process-centric and data-centric. They work in and on these pipelines.
This blog post focuses on the scope and the goals of the recommendation system, and explores some of the most recent changes the Rider team has made to better serve Lyft’s riders. Introduction: Scope of the Recommendation System The recommendation system covers user experiences throughout the ride journey.
With Astro, you can build, run, and observe your data pipelines in one place, ensuring your mission critical data is delivered on time. This blog captures the current state of Agent adoption, emerging software engineering roles, and the use case category. Save Your Spot → Chirag Shah & Ryen W.
Foundation Capital: A System of Agents brings Service-as-Software to life software is no longer simply a tool for organizing work; software becomes the worker itself, capable of understanding, executing, and improving upon traditionally human-delivered services. 60+ speakers from LinkedIn, Shopify, Amazon, Lyft, Grammarly, Mistral, et al.
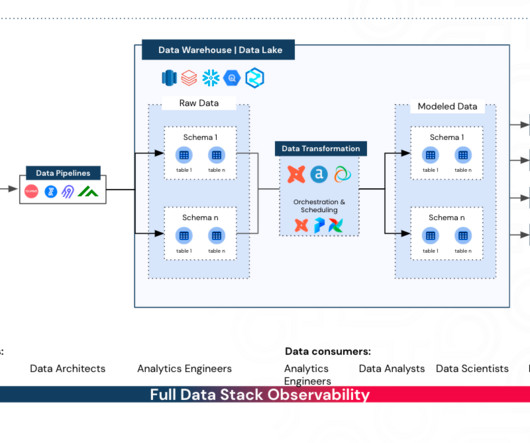
This foundational layer is a repository for various data types, from transaction logs and sensor data to social media feeds and system logs. We have also seen a fourth layer, the Platinum layer , in companies’ proposals that extend the Data pipeline to OneLake and Microsoft Fabric.
One thing that stands out to me is As AI-driven data workflows increase in scale and become more complex, modern data stack tools such as drag-and-drop ETL solutions are too brittle, expensive, and inefficient for dealing with the higher volume and scale of pipeline and orchestration approaches. We all bet on 2025 being the year of Agents.
The challenge is that most companies have a multitude of systems that contain fragments of the customer's interactions and stitching that together is complex and time consuming. Segment created the Unify product to reduce the burden of building a comprehensive view of customers and synchronizing it to all of the systems that need it.
The blog is an excellent summarization of the common patterns emerging in GenAI platforms. Adopting LLM in SQL-centric workflow is particularly interesting since companies increasingly try text-2-SQL to boost data usage. Pipeline breakpoint feature. A key highlight for me is the following features from Maestro.
This introductory blog focuses on an overview of our journey. Future blogs will provide deeper dives into each service, sharing insights and lessons learned from this process. Future blogs will provide deeper dives into each service, sharing insights and lessons learned from this process.
Workflow Optimization : Decomposing complex tasks into smaller, manageable steps and prioritizing deterministic workflows can enhance the reliability and performance of LLM-based systems. The resulting solution was SnowPatrol, an OSS app that alerts on anomalous Snowflake usage, powered by ML Airflow pipelines.
on Cisco UCS S3260 M5 Rack Server with Apache Ozone as the distributed file system for CDP. Look at details of volumes/buckets/keys/containers/pipelines/datanodes. Given a file, find out what nodes/pipeline is it part of. Cloudera will publish separate blog posts with results of performance benchmarks.
in the OpenAI system card explained that the model was able during a cybersecurity challenge (a CTF) to understand a failing Docker environment (due to infra) and still be able to find the flag. /s Lots of stories about exceptional things the model can do have been published today—e.g. How the UK football rely heavily on data?
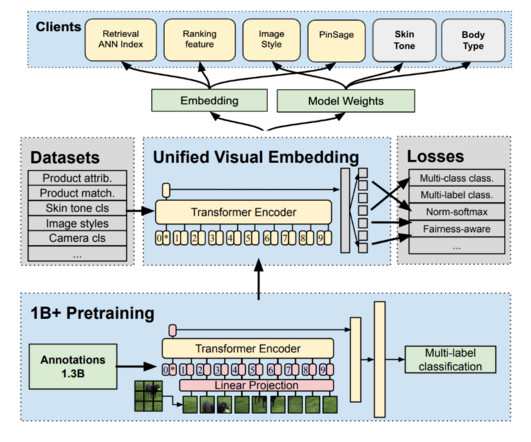
These external partnerships along with our internal fashion specialists and labellers were fundamental in helping us design the experience from both a technical and human-centric perspective. To learn more about engineering at Pinterest, check out the rest of our Engineering Blog and visit our Pinterest Labs site.
Next, it needed to enhance the company’s customer-centric approach for a needs-based alignment of products and services. We are positive that our continuing partnership with Cloudera and Blutech Consulting will be foundational to our customer-centric approach, considerably improving our customer responsiveness,” he said.
It involves many moving parts, from data preparation to building indexing and query pipelines. It also requires both systems to always be available, so no maintenance windows are possible. Distributed transactions are very hard to implement successfully, which is why we’ll introduce a log-inspired system such as Apache Kafka ®.
Take Astro (the fully managed Airflow solution) for a test drive today and unlock a suite of features designed to simplify, optimize, and scale your data pipelines. The blog is a good overview of various components in a typical data stack. Get Guide → Marc Olson: Continuous reinvention: A brief history of block storage at AWS.
Webster’s dictionary defines Entropy in thermodynamics as a measure of the unavailable energy in a closed thermodynamic system that is also usually considered to be a measure of the system’s disorder. Data engineers spend countless hours troubleshooting broken pipelines. More can be found in this blog.
Here is the agenda, 1) Data Application Lifecycle Management - Harish Kumar( Paypal) Hear from the team in PayPal on how they build the data product lifecycle management (DPLM) systems. 3) DataOPS at AstraZeneca The AstraZeneca team talks about data ops best practices internally established and what worked and what didn’t work!!!
This discipline also integrates specialization around the operation of so called “big data” distributed systems, along with concepts around the extended Hadoop ecosystem, stream processing, and in computation at scale. Those systems have been taught to normalize the data for storage on their own.
The Otezla team built a system with tens of thousands of automated tests checking data and analytics quality. The data pipelines must contend with a high level of complexity – over seventy data sources and a variety of cadences, including daily/weekly updates and builds. That’s the power of DataOps automation. It’s that simple. .
This blog discusses quantifications, types, and implications of data. The activity in the field of learning with limited data is reflected in a variety of courses , workshops , reports , blogs and a large number of academic papers (a curated list of which can be found here ). Quantifications of data. Addressing the challenges of data.
Data Engineering is typically a software engineering role that focuses deeply on data – namely, data workflows, data pipelines, and the ETL (Extract, Transform, Load) process. Data Engineers are engineers responsible for uncovering trends in data sets and building algorithms and data pipelines to make raw data beneficial for the organization.
It is amusing for a human being to write an article about artificial intelligence in a time when AI systems, powered by machine learning (ML), are generating their own blog posts. I frequently check Pipeline Runs and Sensor Ticks, but, often verify with Dagit.”
In this blog post, we will see the top Automation testing tools used in the software industry. Supports major operating systems:- Windows, Linux, and Mac. TestComplete is essentially a Windows-based application and thus cannot run on Linux/Unix systems. A webDriver-based tool called Appium can be used for mobile applications.
This blog is for anyone who was interested but unable to attend the conference, or anyone interested in a quick summary of what happened there. Use cases such as fraud monitoring, real-time supply chain insight, IoT-enabled fleet operations, real-time customer intent, and modernizing analytics pipelines are driving development activity.
Treating data as a product is more than a concept; it’s a paradigm shift that can significantly elevate the value that business intelligence and data-centric decision-making have on the business. Data pipelines Data integrity Data lineage Data stewardship Data catalog Data product costing Let’s review each one in detail.
A curated list of the top 9 must read blogs on data. At the end of 2022 we decided to collect the blogs we enjoyed the most over the year. The data world is in turmoil and lots of exciting things happen every day, week and year. Happy reading! Happy reading!
We have heard news of machine learning systems outperforming seasoned physicians on diagnosis accuracy, chatbots that present recommendations depending on your symptoms , or algorithms that can identify body parts from transversal image slices , just to name a few. What makes a good Data Pipeline?
Kubernetes (sometimes shortened to K8s with the 8 standing for the number of letters between the “K” and the “s”) is an open-source system to deploy, scale, and manage containerized applications anywhere. Kubernetes is a container-centric management software that allows the creation and deployment of containerized applications with ease.
Editors Note: 🔥 DEW is thrilled to announce a developer-centric Data Eng & AI conference in the tech hub of Bengaluru, India, on October 12th! LinkedIn write about Hoptimator for auto generated Flink pipeline with multiple stages of systems. See how it works today.
Data Engineers create a system that gathers, handles, and transforms unprocessed data into useful information that data researchers and Data Analysts may use to evaluate it in several contexts. . Pipeline-centric: Pipeline-centric Data Engineers collaborate with data researchers to maximize the use of the info they gather.
Data lineage tools provide a visual representation of your data’s journey across multiple systems and transformations. This feature is particularly useful in complex data architectures, where data may pass through multiple systems and transformations.
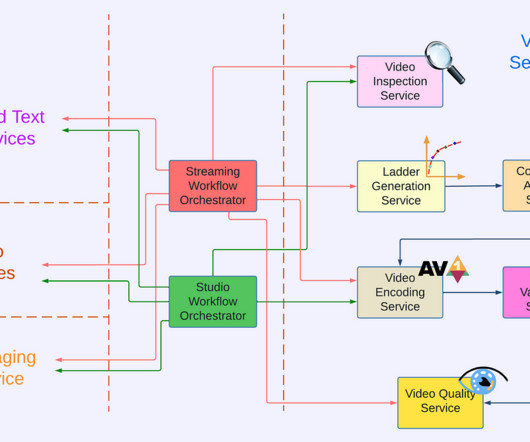
Moorthy and Zhi Li Introduction Measuring video quality at scale is an essential component of the Netflix streaming pipeline. The coupling problem Until recently, video quality measurements were generated as part of our Reloaded production system. We call this system Cosmos. by Christos G. Bampis , Chao Chen , Anush K.
Meta: Presto - A Decade of SQL Analytics at Meta Presto and Kafka are the two systems that greatly impacted data infrastructure in the last decade. As with any good system, Presto went through many optimizations. There are some interesting threads on Twitter, but the highlight for me is the design of the Tweet search system.
Data Engineering Weekly Is Brought to You by RudderStack RudderStack provides data pipelines that make collecting data from every application, website, and SaaS platform easy, then activating it in your warehouse and business tools. Watch On-demand Niels Claeys: Use dbt and Duckdb instead of Spark in data pipelines AWS u-24tb1.metal
As a result, a less senior team member was made responsible for modifying a production pipeline. Make Trusted Data Products with Reusable Modules : “Many organizations are operating monolithic data systems and processes that massively slow their data delivery time.” Build analytic data systems that have modular, reusable components.
It provides familiar APIs for various data centric tasks, including data preparation, cleansing, preprocessing, model training, and deployments tasks. In the warehouse model, users can seamlessly run and operationalize data pipelines, ML models, and data applications with user-defined functions (UDFs) and stored procedures (sprocs).
These are particularly frustrating, because while they are breaking data pipelines constantly, it’s not their fault. Tight coupling Upstream data quality challenges are oftentimes a result of tight coupling between systems. In fact, most of the time they are unaware of these data quality challenges. Image courtesy of Andrew Jones.
Chapin shared that even though GE had embraced agile practices since 2013, the company still struggled with massive amounts of legacy systems. It provides the ability] to incrementally and constantly improve the system. . Be business-centric. Success Requires Focus on Business Outcomes, Benchmarking.
In this blog post, we’ll review the core data mesh principles, highlight how both organizations and modern data platforms are putting those principles into action, and demonstrate just how achievable a secure and efficient data mesh architecture can be.
In this blog, we’d like to give you a glimpse into some of the major developments in Picnic Tech in 2023. This approach not only helps in maintaining system stability but also in predicting potential issues, enabling proactive measures. July: Introduction of a new Transport Planning System ? Join us and have a read!
In this blog, we’ll discuss DevOps release management, its process, best practices, and the advantages of release manager in Devops. It encompasses the planning, scheduling, and controlling of software builds and delivery pipelines. This includes unit tests, integration tests, system tests, and acceptance tests.
He is also an open-source developer at The Apache Software Foundation and the author of Hysterical , a popular blog on tech careers and topics like data, coding, and engineering. Brian shares advice regularly on his Medium blog and GitHub , as well as on LinkedIn, focusing on topics like data science, data engineering, data strategy, and SQL.
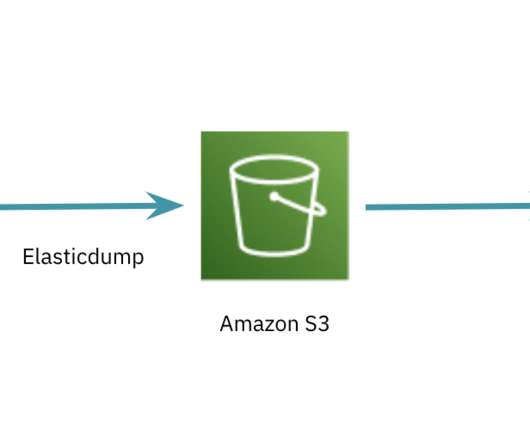
This blog outlines best practices from customers I have helped migrate from Elasticsearch to Rockset , reducing risk and avoiding common pitfalls. Elasticsearch has become ubiquitous as an index centric datastore for search and rose in tandem with the popularity of the internet and Web2.0.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content