This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Whether tracking user behavior on a website, processing financial transactions, or monitoring smart devices, the need to make sense of this data is growing. But when it comes to handling this data, businesses must decide between two key processes - batch processing vs stream processing. What is Batch Processing?
At the core of such applications lies the science of machine learning, image processing, computer vision , and deep learning. As an example, consider the Facial Image Recognition System, it leverages the OpenCV Python library for implementing image processing techniques. Table of Contents What is OpenCV Python?
Two years ago I wrote a blog post to announce that the GHC wasm backend had been merged upstream. I’ve been too lazy to write another blog post about the project since then, but rest assured, the project hasn’t stagnated. If you take a look at htop , you’ll notice wasm32-wasi-ghc spawns a node child process.
This blog aims to give you an overview of the data analysis process with a real-world business use case. Table of Contents The Motivation Behind Data Analysis Process What is Data Analysis? What is the goal of the analysis phase of the data analysis process? What are the steps in the data analysis process?
for the simulation engine Go on the backend PostgreSQL for the data layer React and TypeScript on the frontend Prometheus and Grafana for monitoring and observability And if you were wondering how all of this was built, Juraj documented his process in an incredible, 34-part blog series. You can read this here. Serving a web page.
In the realm of big data processing, PySpark has emerged as a formidable force, offering a perfect blend of capabilities of Python programming language and Apache Spark. In this blog, we will dive into the fundamental concepts of PySpark DataFrames and demonstrate how to leverage their capabilities efficiently. Let’s get started!
Here’s What You Need to Know About PySpark This blog will take you through the basics of PySpark, the PySpark architecture, and a few popular PySpark libraries , among other things. PySpark is used to process real-time data with Kafka and Streaming, and this exhibits low latency. How long does it take to learn PySpark?
This belief has led us to developing Privacy Aware Infrastructure (PAI) , which offers efficient and reliable first-class privacy constructs embedded in Meta infrastructure to address different privacy requirements, such as purpose limitation , which restricts the purposes for which data can be processed and used. Hack, C++, Python, etc.)
” Thus, don't miss out on the opportunity to revolutionize your business with real-time data processing using Azure Stream Analytics. Read this blog till the end to discover how Azure Stream Analytics can simplify your journey to actionable insights. Table of Contents What is Azure Stream Analytics?
Through this blog, we delve into the fundamental concepts and techniques offered by Pandas, providing you with a comprehensive cheat sheet to navigate the complexities of data preprocessing in Python and Data Science. You will understand how to customize the import process, handle null values, and specify data types during data loading.
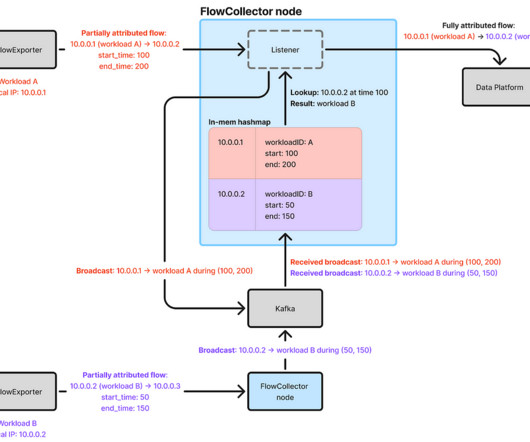
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. This process can also be used to track the provenance of increments.
This blog post is the second in a three-part series on migrations. Processing some 90,000 tables per day, the team oversees the ingestion of more than 100 terabytes of data from upward of 8,500 events daily. That’s why we’ve collected these migration success stories to help you get started on your migration to Snowflake.
Over the last three geospatial-centric blog posts, weve covered the basics of what geospatial data is, how it works in the broader world of data and how it specifically works in Snowflake based on our native support for GEOGRAPHY , GEOMETRY and H3. But there is so much more you can do with geospatial data in your Snowflake account!
The end-to-end lineage also automates tasks such as predicting the impact of a process change, analyzing the impact of a broken process, discovering parallel processes performing the same tasks, and performing root cause analysis to uncover the source of reporting errors.
Over the past four weeks, I took a break from blogging and LinkedIn to focus on building nao. We published videos about the Forward Data Conference, you can watch Hannes, DuckDB co-creator, keynote about Changing Large Tables. The evolution of OLAP — What is OLAP in the modern data stack?
This is done by combining parameter preserving model rewiring with lightweight fine-tuning to minimize the likelihood of knowledge being lost in the process. You can learn more in our SwiftKV research blog post. SwiftKV achieves higher throughput performance with minimal accuracy loss (see Tables 1 and 2).
This blog introduces the concept of time series forecasting models in the most detailed form. The blog's last two parts cover various use cases of these models and projects related to time series analysis and forecasting problems. This blog will explore these use cases with practical time series forecasting model examples.
Here’s how Snowflake Cortex AI and Snowflake ML are accelerating the delivery of trusted AI solutions for the most critical generative AI applications: Natural language processing (NLP) for data pipelines: Large language models (LLMs) have a transformative potential, but they often batch inference integration into pipelines, which can be cumbersome.
In this blog post, well explain how a composable CDP works and how it can empower financial services marketers to fully leverage their data and AI to improve performance. Composable CDPs support streamlining of governance processes that manage marketer workflows. Use all of your data.
This blog offers an Agentic AI learning path, explaining the core components behind AI Agents. If you’ve ever wondered how these intelligent systems work or wanted to build one, this blog is your starting point. Read more about AI agents in our latest blog: AI Agents: The New Human-Like Heroes of AI.
Cloud computing is the future, given that the data being produced and processed is increasing exponentially. We will cover all such details in this blog. Assume they also have an order processing service that processes active orders submitted by the customers but not fulfilled by the company. zettabytes in 2020.
This blog delves into the six distinct types of data quality dashboards, examining how each fulfills a specific role in ensuring data excellence. Is completeness about filling every field in a record, or is it about having the fields critical to a particular business process? However, not all data quality dashboards are created equal.
The blog is an excellent compilation of types of query engines on top of the lakehouse, its internal architecture, and benchmarking against various categories. Then, a custom Apache Beam consumer processed these events, transforming and writing them to CRDB. link] Gunnar Morling: What If We Could Rebuild Kafka From Scratch?
From understanding the delays to implementing effective solutions, dive into practical strategies for optimizing serverless performance in this blog. With the global cloud computing market size likely to reach over $727 billion in 2024 , AWS Lambda has emerged as a game-changer, simplifying complex processes with its serverless architecture.
Process > Tooling (Barr) 3. Process > Tooling (Barr) A new tool is only as good as the process that supports it. The move toward self-serve AI-enabled pipeline management means that the most painful part of everyone’s job gets automated away—and their ability to create and demonstrate new value expands in the process.
The blog narrates adopting a hybrid approach with AWS Sagemaker integration and Chalk feature store. link] EloElo: Building EloElo’s Data Platform - Our 2-year Journey to Batch + Real-Time Lakehouse on Open Source stack The blog captures the emerging lakehouse architecture, combining CDC pipelines and event sourcing systems.
Snowpark Container Services (now generally available on Azure as well as AWS) gives developers the flexibility to easily and securely deploy complex functionality — from custom frontends and large-scale ML training and inference to open source and homegrown models — all securely within Snowflake (learn more in this blog post ).
Data engineering is the foundation for data science and analytics by integrating in-depth knowledge of data technology, reliable data governance and security, and a solid grasp of data processing. This blog covers the top ten AWS data engineering tools popular among data engineers across the big data industry.
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter 5 Error Handling Patterns in Python (Beyond Try-Except) Stop letting errors crash your app.
Looking for an efficient tool for streamlining and automating your data processing workflows? Read this blog till the end to learn everything you need to know about Airflow DAG. Let's consider an example of a data processing pipeline that involves ingesting data from various sources, cleaning it, and then performing analysis.
It is extremely important for businesses to process data correctly since the volume and complexity of raw data are rapidly growing. Over the past few years, data-driven enterprises have succeeded with the Extract Transform Load (ETL) process to promote seamless enterprise data exchange.
This transformation is where data warehousing tools come into play, acting as the refining process for your data. These tools are crucial in modern business intelligence and data-driven decision-making processes. Amazon Redshift Pros High query performance via columnar storage and parallel processing.
By Cheng Xie , Bryan Shultz , and Christine Xu In a previous blog post , we described how Netflix uses eBPF to capture TCP flow logs at scale for enhanced network insights. 2xlarge instances, we can process 5 million flows per second across the entire Netflixfleet. With 30 c7i.2xlarge
Read this blog if you are interested in exploring business intelligence projects examples that highlight different strategies for increasing business growth. Along with that, deep learning algorithms and image processing methods are also used over medical reports to support a patient’s treatment better. Chilly December is here!
This blog introduces you to AWS DevOps and the various AWS services it offers for cloud computing. If you’re curious to learn why you should leverage these AWS DevOps tools and how different businesses benefit, this blog is for you. Benefits of AWS CodePipeline 1.
This blog will help you understand what data engineering is with an exciting data engineering example, why data engineering is becoming the sexier job of the 21st century is, what is data engineering role, and what data engineering skills you need to excel in the industry, Table of Contents What is Data Engineering?
This blog introduces Cache-Augmented Generation (CAG), a powerful alternative to RAG for enhancing LLM responses. These documents are processed and stored in a Key-Value (KV) Cache, which acts like a fast-access memory bank for the model. You can find in-depth blogs on these topics on the ProjectPro website.
Did you know Apache Kafka was the leading technology in the global big data processing business in 2023, with a 16.88 This blog is the ideal roadmap for big data professionals looking for the top resources to master Apache Kafka. These events are crucial in facilitating real-time streaming and data processing.
In this blog post, well discuss our experiences in identifying the challenges associated with EC2 network throttling. In the remainder of this blog post, well share how we root cause and mitigate the aboveissues. This prompted us to engage with AWS and dive deep into the network performance of our clusters. 4xl with up to 12.5
Read this blog to understand everything about AWS Glue that makes it one of the most popular data integration solutions in the industry. For e.g., Finaccel, a leading tech company in Indonesia, leverages AWS Glue to easily load, process, and transform their enterprise data for further processing. billion by 2026?
Specifically, we have adopted a “shift-left” approach, integrating data schematization and annotations early in the product development process. However, conducting these processes outside of developer workflows presented challenges in terms of accuracy and timeliness.
ETL is considered to be an essential part of data warehousing architecture in business processes worldwide. Although every interview is unique and every role has a different range of responsibilities, this blog can help you with the top ten ETL Interview Questions that will enable you to take the leap and excel in your interview.
With the help of natural language processing (NLP) tools, it has led to the development of exciting artificial intelligence applications like language recognition, autonomous vehicles, and computer vision robots, to name a few. Deep Learning also uses the same analogy of a brain neuron for processing the information and recognizing them.
Check out this blog post that lists the seven best PyTorch books that are an essential read for data science beginners like Steve and experienced developers. But with so much to learn and explore in PyTorch, it is difficult to know where to start.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content