This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It is a critical and powerful tool for scalable discovery of relevant data and data flows, which supports privacy controls across Metas systems. In this blog, we will delve into an early stage in PAI implementation: data lineage. Data lineage enables us to efficiently navigate these assets and protect user data.
Juraj included system monitoring parts which monitor the server’s capacity he runs the app on: The monitoring page on the Rides app And it doesn’t end here. Juraj created a systems design explainer on how he built this project, and the technologies used: The systems design diagram for the Rides application The app uses: Node.js
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. Open Table Format (OTF) architecture now provides a solution for efficient data storage, management, and processing while ensuring compatibility across different platforms.
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
Data engineering is a vital field within the realm of data science that focuses on the practical aspects of collecting, storing, and processing large amounts of data. Here it is. appeared first on Confessions of a Data Guy.
Unlocking Data Team Success: Are You Process-Centric or Data-Centric? We’ve identified two distinct types of data teams: process-centric and data-centric. Process-centric data teams focus their energies predominantly on orchestrating and automating workflows. They work in and on these pipelines.
When you hear the term System Hacking, it might bring to mind shadowy figures behind computer screens and high-stakes cyber heists. In this blog, we’ll explore the definition, purpose, process, and methods of prevention related to system hacking, offering a detailed overview to help demystify the concept.
Authors: Bingfeng Xia and Xinyu Liu Background At LinkedIn, Apache Beam plays a pivotal role in stream processing infrastructures that process over 4 trillion events daily through more than 3,000 pipelines across multiple production data centers.
Balancing correctness, latency, and cost in unbounded data processing Image created by the author. Intro Google Dataflow is a fully managed data processing service that provides serverless unified stream and batch data processing. It is the first choice Google would recommend when dealing with a stream processing workload.
This blog post is the second in a three-part series on migrations. A consolidated data system to accommodate a big(ger) WHOOP When a company experiences exponential growth over a short period, it’s easy for its data foundation to feel a bit like it was built on the fly.
What is Real-Time Stream Processing? To access real-time data, organizations are turning to stream processing. To access real-time data, organizations are turning to stream processing. There are two main data processing paradigms: batch processing and stream processing.
Over the past four weeks, I took a break from blogging and LinkedIn to focus on building nao. AI companies are aiming for the moon—AGI—promising it will arrive once OpenAI develops a system capable of generating at least $100 billion in profits. Meanwhile, the AI landscape remains unpredictable.
When integrated effectively, AI and machine learning (ML) models can process data streams at near-zero latency, empowering teams to make split-second decisions. Systems must be capable of handling high-velocity data without bottlenecks. Thats where real-time artificial intelligence (AI) can help.
Additionally, multiple copies of the same data locked in proprietary systems contribute to version control issues, redundancies, staleness, and management headaches. This guarantees data quality and automates the laborious, manual processes required to maintain data reliability.
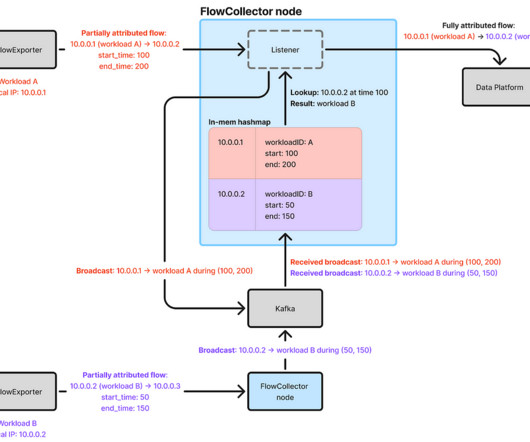
By Cheng Xie , Bryan Shultz , and Christine Xu In a previous blog post , we described how Netflix uses eBPF to capture TCP flow logs at scale for enhanced network insights. Delays and failures are inevitable in distributed systems, which may delay IP address change events from reaching FlowCollector. With 30 c7i.2xlarge
In particular, our machine learning powered ads ranking systems are trying to understand users’ engagement and conversion intent and promote the right ads to the right user at the right time. Specifically, such discrepancies unfold into the following scenarios: Bug-free scenario : Our ads ranking system is working bug-free.
Astasia Myers: The three components of the unstructured data stack LLMs and vector databases significantly improved the ability to process and understand unstructured data. The blog is an excellent summary of the existing unstructured data landscape. The blog from Meta discusses how it designed a privacy-preserving storage.
Semih is a researcher and entrepreneur with a background in distributed systems and databases. He then pursued his doctoral studies at Stanford University, delving into the complexities of database systems. Dont forget to subscribe to my YouTube channel to get the latest on Unapologetically Technical!
This blog will explore the significant advancements, challenges, and opportunities impacting data engineering in 2025, highlighting the increasing importance for companies to stay updated. In 2025, this blog will discuss the most important data engineering trends, problems, and opportunities that companies should be aware of.
Meta’s vast and diverse systems make it particularly challenging to comprehend its structure, meaning, and context at scale. Specifically, we have adopted a “shift-left” approach, integrating data schematization and annotations early in the product development process.
It requires a state-of-the-art system that can track and process these impressions while maintaining a detailed history of each profiles exposure. In this multi-part blog series, we take you behind the scenes of our system that processes billions of impressions daily.
This blog dives into the remarkable journey of a data team that achieved unparalleled efficiency using DataOps principles and software that transformed their analytics and data teams into a hyper-efficient powerhouse. Starting simply and iterating quickly gave the team time to build foundational processes before adding complexity and scaling.
The blog took out the last edition’s recommendation on AI and summarized the current state of AI adoption in enterprises. One of the core challenges of data engineering, as the author put it elegantly, The core difficulty lies in the fact that each step in the process requires specialized domain knowledge.
Liang Mou; Staff Software Engineer, Logging Platform | Elizabeth (Vi) Nguyen; Software Engineer I, Logging Platform | In today’s data-driven world, businesses need to process and analyze data in real-time to make informed decisions. Real-Time Data Processing : CDC enables real-time data processing by capturing changes as they happen.
The period from April to mid-May was challenging: I found myself in hiring freezes and canceled processes. Simplify helped me a lot to automatically fill applications in the most popular applicant tracking systems (ATS.) ’ How did you find the interview processes?
Here’s how Snowflake Cortex AI and Snowflake ML are accelerating the delivery of trusted AI solutions for the most critical generative AI applications: Natural language processing (NLP) for data pipelines: Large language models (LLMs) have a transformative potential, but they often batch inference integration into pipelines, which can be cumbersome.
I found the blog to be a fresh take on the skill in demand by layoff datasets. DeepSeek continues to impact the Data and AI landscape with its recent open-source tools, such as Fire-Flyer File System (3FS) and smallpond. The blog provides an excellent analysis of smallpond compared to Spark and Daft.
Behind the scenes, a myriad of systems and services are involved in orchestrating the product experience. These backend systems are consistently being evolved and optimized to meet and exceed customer and product expectations. This blog series will examine the tools, techniques, and strategies we have utilized to achieve this goal.
The availability of deep learning frameworks like PyTorch or JAX has revolutionized array processing, regardless of whether one is working on machine learning tasks or other numerical algorithms. Nix is needed to simplify the installation and patching of system dependencies (not all our patches have been merged upstream yet).
A little over a year ago, we shared a blog post about our journey to enhance customers meal planning experience with personalized recipe recommendations. We explained how a system that learns from your tastes and habits could solve this issue, ultimately making the daily task of choosing meals both effortless and inspiring.
In this blog, well explore Building an ETL Pipeline with Snowpark by simulating a scenario where commerce data flows through distinct data layersRAW, SILVER, and GOLDEN.These tables form the foundation for insightful analytics and robust business intelligence. SILVER Layer : Cleansed and enriched data prepared for analytical processing.
In recent years, while managing Pinterests EC2 infrastructure, particularly for our essential online storage systems, we identified a significant challenge: the lack of clear insights into EC2s network performance and its direct impact on our applications reliability and performance. 4xl with up to 12.5
It covers nine categories: storage systems, data lake platforms, processing, integration, orchestration, infrastructure, ML/AI, metadata management, and analytics. I found the blog to be a comprehensive roadmap for data engineering in 2025. Let me know in the comments. link] All rights reserved ProtoGrowth Inc, India.
However, due to the absence of a control group in these countries, we adopt a synthetic control framework ( blog post ) to estimate the counterfactual scenario. Each format has a different production process and different patterns of cash spend, called our Content Forecast. As plans change, the cash forecast will change.
The Medallion architecture is a design pattern that helps data teams organize data processing and storage into three distinct layers, often called Bronze, Silver, and Gold. This foundational layer is a repository for various data types, from transaction logs and sensor data to social media feeds and system logs.
[link] QuantumBlack: Solving data quality for gen AI applications Unstructured data processing is a top priority for enterprises that want to harness the power of GenAI. It brings challenges in data processing and quality, but what data quality means in unstructured data is a top question for every organization.
The article summarizes the recent macro trends in AI and data engineering, focusing on Vibe coding, human-in-the-loop system design, and rapid simplification of developer tooling. Unlike coding, we never (or rarely) apply a code review process for documentation. The Grab blog delights me since I have tried to do this many times.
Read Time: 2 Minute, 34 Second Introduction In modern data pipelines, especially in cloud data platforms like Snowflake, data ingestion from external systems such as AWS S3 is common. In this blog, we introduce a Snowpark-powered Data Validation Framework that: Dynamically reads data files (CSV) from an S3 stage.
This is where large-scale system migrations come into play. Our previous blog post presented replay traffic testing — a crucial instrument in our toolkit that allows us to implement these transformations with precision and reliability. Sticky Canary is an improvement to the traditional canary process that addresses this limitation.
By building on top of tools that truly understand SQL, it is possible to create systems that are much more capable, resilient and flexible than weve seen to date. At Level 2, the system produces a complete Logical Plan. Thats hard to demonstrate in a blog post, but fortunately theres another easier option: look at some failing queries.
Foundation Capital: A System of Agents brings Service-as-Software to life software is no longer simply a tool for organizing work; software becomes the worker itself, capable of understanding, executing, and improving upon traditionally human-delivered services. It's good to know about Dapr and restate.dev.
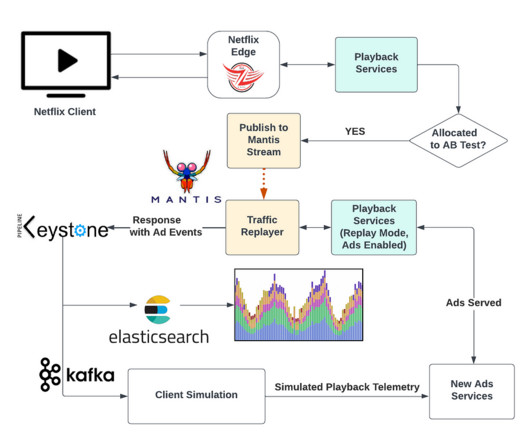
In this blog post, we’ll discuss the methods we used to ensure a successful launch, including: How we tested the system Netflix technologies involved Best practices we developed Realistic Test Traffic Netflix traffic ebbs and flows throughout the day in a sinusoidal pattern. Basic with ads was launched worldwide on November 3rd.
This blog post will highlight the experience I had as a relatively junior developer on a Scott Logic project. The aim was to build a system that would allow them to compare their forecasted Air Quality Index (AQI) values with actual measured AQI data. We use powerful Python libraries such as Pandas and Xarray for this task.
Robinhood and Bitstamp customers can expect the same level of service, security and reliability and as we move forward, we are committed to maintaining transparency throughout this process. Robinhood expects the final deal consideration to be approximately $200 million in cash, subject to customary purchase price adjustments.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content