This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It sounds great, but how do you prove the data is correct at each layer? How do you ensure data quality in every layer ? Bronze, Silver, and Gold – The Data Architecture Olympics? The Bronze layer is the initial landing zone for all incoming rawdata, capturing it in its unprocessed, original form.
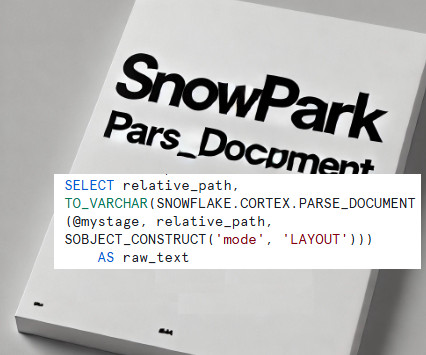
However, Ive taken this a step further, leveraging Snowpark to extend its capabilities and build a complete data extraction process. This blog explores how you can leverage the power of PARSE_DOCUMENT with Snowpark, showcasing a use case to extract, clean, and process data from PDF documents. Why Use PARSE_DOC?
Snowflakes Snowpark is a game-changing feature that enables data engineers and analysts to write scalable data transformation workflows directly within Snowflake using Python, Java, or Scala. They need to: Consolidate rawdata from orders, customers, and products. Enrich and clean data for downstream analytics.
We covered how Data Quality Testing, Observability, and Scorecards turn data quality into a dynamic process, helping you build accuracy, consistency, and trust at each layerBronze, Silver, and Gold. Practical Tools to Sprint Ahead: Dive into hands-on tips with open-source tools that supercharge data validation and observability.
Best of all, they are all designed to work together seamlessly, providing you with the capabilities for a smooth path from rawdata to AI-driven results. Were building on our foundation of proven data and analytics expertise to deliver a platform thats ready to help you realize real business value from your AI initiatives.
What is Data Transformation? Data transformation is the process of converting rawdata into a usable format to generate insights. It involves cleaning, normalizing, validating, and enriching data, ensuring that it is consistent and ready for analysis.
Training a high-quality machine learning model requires careful data and feature preparation. To fully utilize rawdata stored as tables in Databricks, running.
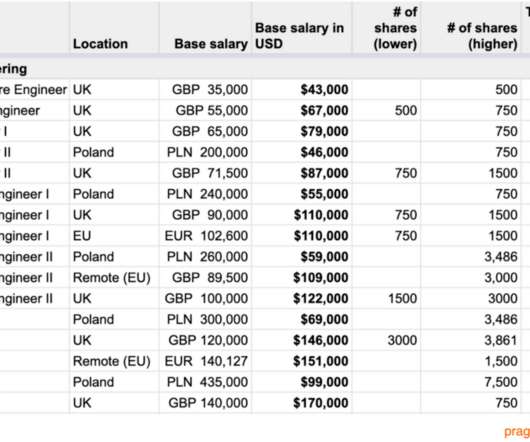
In this week’s The Scoop, I analyzed this information and dissected it, going well beyond the rawdata. Here are a few details from the data points, focusing on software engineering compensation. Source: The Pragmatic Engineer blog. Tier 1: hyperlocal compensation. Companies benchmark against local competitors.
Developers do not have to move the rawdata from its original storage location. Together, these updates empower enterprises to securely derive accurate, timely insights from their data, reducing the overall cost of data-driven decision-making. The parsing function takes care of extracting text and layout from documents.
At Uber’s scale, thousands of microservices serve millions of rides and deliveries a day, generating more than a hundred petabytes of rawdata. Internally, engineering and data teams across the company leverage this data to improve the Uber experience.
The application you're implementing needs to analyze this data, combining it with other datasets, to return live metrics and recommended actions. But how can you interrogate the data and frame your questions correctly if you don't understand the shape of your data? This enables Rockset to generate a Smart Schema on the data.
In the previous blog post in this series, we walked through the steps for leveraging Deep Learning in your Cloudera Machine Learning (CML) projects. Data Ingestion. The rawdata is in a series of CSV files. We will firstly convert this to parquet format as most data lakes exist as object stores full of parquet files.
Collecting, cleaning, and organizing data into a coherent form for business users to consume are all standard data modeling and data engineering tasks for loading a data warehouse. Based on Tecton blog So is this similar to data engineering pipelines into a data lake/warehouse?
The data industry has a wide variety of approaches and philosophies for managing data: Inman data factory, Kimball methodology, s tar schema , or the data vault pattern, which can be a great way to store and organize rawdata, and more. Data mesh does not replace or require any of these.
The missing chapter is not about point solutions or the maturity journey of use cases, the missing chapter is about the data, it’s always been about the data, and most importantly the journey data weaves from edge to artificial intelligence insight. . Data Collection Using Cloudera Data Platform.
DataOps involves collaboration between data engineers, data scientists, and IT operations teams to create a more efficient and effective data pipeline, from the collection of rawdata to the delivery of insights and results. Query> An AI, Chat GPT wrote this blog post, why should I read it? .
If the data of interest isn’t already available in the structured part of the data warehouse, chances are that the analyst will proceed with a short term solution querying rawdata, while the data engineer may help in properly logging and eventually carrying that data into the warehouse.
The state-of-the-art neural networks that power generative AI are the subject of this blog, which delves into their effects on innovation and intelligent design’s potential. Multiple levels: Rawdata is accepted by the input layer. Receives rawdata, with each neuron representing a feature of the input.
They contribute to the understanding of data’s hidden structures by incorporating variables that are not directly observed but inferred from observable data. Feature Extraction: They help find relevant features that aren’t directly obvious in rawdata.
The data and the techniques presented in this prototype are still applicable as creating a PCA feature store is often part of the machine learning process. . The process followed in this prototype covers several steps that you should follow: Data Ingest – move the rawdata to a more suitable storage location.
There’s no need for ETLs, pre-aggregations that sacrifice flexibility, or additional infrastructure that requires data engineering resources. Metrics API: It provides a Metrics API that not only gives meaning to your rawdata but also empowers your dev teams across the company to build with a self-service analytics API.
From Information to Insight The difficulty is not gathering data but making sense of it. Predictive analytics and business intelligence (BI) solutions transform rawdata into actionable insights, including real-time dashboards, forecasting capabilities, and scenario modelling.
Pair this with Snowflake , the cloud data warehouse that acts as a vault for your insights, and you have a recipe for data-driven success. Get ready to explore the realm where data dreams become reality! In this blog, we will cover: What is Airbyte? With Airbyte and Snowflake, data integration is now a breeze.
Columns of numbers, equations, and rawdata tend to overwhelm rather than enlighten. Enter Power BI, revolutionizing this domain with its prowess in data visualization. The Power of Visualization in Cash Flow Reporting Traditional methods of cash flow reporting often suffer from a lack of immediacy and clarity.
The modeling process begins with data collection. Here, Cloudera Data Flow is leveraged to build a streaming pipeline which enables the collection, movement, curation, and augmentation of rawdata feeds. These feeds are then enriched using external data sources (e.g., Learn more: Fraud Prevention Resource Kit.
If you ingest this log data into SSB, for example, by automatically detecting the data’s schema by sampling messages on the Kafka stream, this field will be ignored before it gets into SSB, though they are in the rawdata. The post SQL Streambuilder Data Transformations appeared first on Cloudera Blog.
The Cloudera Data Platform enables insurers to effectively manage the data lifecycle more efficiently than ever before. In order to personalize the customer experience, insurers need an intelligent platform that can ingest the rawdata and perform real-time and predictive analytics.
Right now we’re focused on rawdata quality and accuracy because it’s an issue at every organization and so important for any kind of analytics or day-to-day business operation that relies on data — and it’s especially critical to the accuracy of AI solutions, even though it’s often overlooked.
The ADSB rawdata queried using SSB looks similar to the following: For the purposes of this example we will omit the explanation of how to set up a data provider and how to create a table we can query. The post Implementing and Using UDFs in Cloudera SQL Stream Builder appeared first on Cloudera Blog.
I won't delve into every announcement here, but for more details, SELECT has written a blog covering the 28 announcements and takeaways from the Summit. This enables easier data management and query operations, making it possible to perform SQL-like operations and transactions directly on data files.
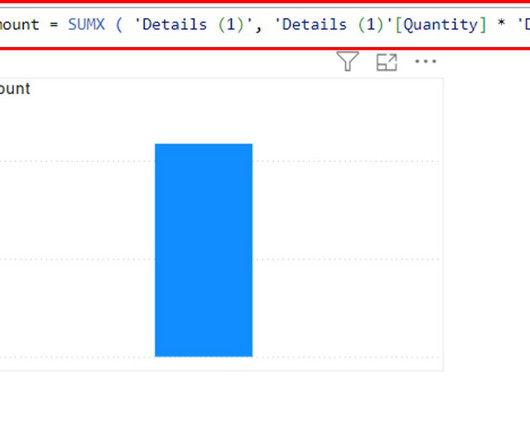
Power BI’s extensive modeling, real-time high-level analytics, and custom development simplify working with data. You will often need to work around several features to get the most out of business data with Microsoft Power BI. To get the most out of rawdata, one must be familiar with key DAX functions like SUMX Power BI.
A discussion of DataOps moves the focus away from organization and domains and considers one of the most important questions facing data organizations – a question that rarely gets asked. How do you build a data factory?” The data factory encompasses all of the domains in a system architecture.
The pressures banks face call for a versatile end-to-end platform designed to drive insights, intelligence, and action from the data. Cloudera Data Platform (CDP) is an enterprise data cloud that manages the end-to-end data lifecycle – collecting rawdata at the source to drive actionable insights and use cases.
In the real world, data is not open source , as it is confidential and may contain very sensitive information related to an item , user or product. But rawdata is available as open source for beginners and learners who wish to learn technologies associated with data.
This blog post describes TScript and how we use it at Pinterest. This becomes even more powerful with templating, which will be discussed in a later blog post. They can do that for alerting but still show the rawdata in the graph. Performing operations on the returned time series.
Placing responsibility for all the data sets on one data engineering team creates bottlenecks. Let’s consider how to break up our architecture into data mesh domains. In figure 4, we see our rawdata shown on the left. First, the data is mastered, usually by a centralized data engineering team or IT.
This is due to the fact that they are not sufficiently refined and that they are trained using publicly available, publicly published rawdata. Given where that training data came from, it’s probable that it might misrepresents or underrepresents particular groups or concepts be given the wrong label.
While business rules evolve constantly, and while corrections and adjustments to the process are more the rule than the exception, it’s important to insulate compute logic changes from data changes and have control over all of the moving parts. Late arriving facts Late arriving facts can be problematic with a strict immutable data policy.
In this blog post, we look at three popular options for scheduled jobs using Databricks own TPC-DI benchmark suite. The goal of this blog post is to help readers understand the pros, cons, and performance tradeoffs of the various Databricks compute options, so they can make the best choice for their workloads.
And when moving to Snowflake , you get the advantage of the Data Cloud’s architectural benefits (flexibility, scalability and high performance) as well as availability across multiple cloud providers and global regions. How many tables and views will be migrated, and how much rawdata?
This blog will explore some of the most exciting software career options and what you need to do to get started. Data Engineer Data engineers develop or strategize software to retrieve, sort, and process rawdata to extract meaningful information to assess an operation.
My key highlight is that Excellent data documentation and “clean data” improve results. The blog further emphasizes its increased investment in Data Mesh and clean data. link] Databricks: PySpark in 2023 - A Year in Review Can we safely say PySpark killed Scala-based data pipelines?
In fact, you reading this blog is also being recorded as an instance of data in some digital storage. In 2018, the world produced 33 Zettabytes (ZB) of data, which is equivalent to 33 trillion Gigabytes (GB). It’s a great place to learn Data Science.
Once data is in Z-order it is possible to efficiently search against more columns. In a previous blog post , we demonstrated the power of Parquet page indexes, which can greatly improve the performance of selective queries. Parquet page index filtering helps us when we have search criteria against data columns.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content