This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
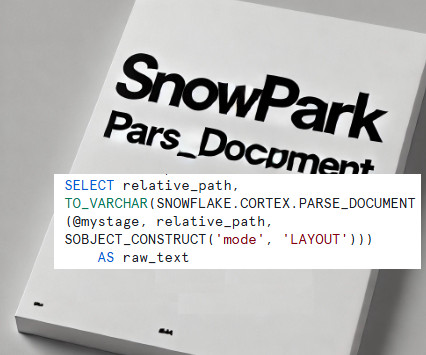
Traditionally, this function is used within SQL to extract structured content from documents. However, Ive taken this a step further, leveraging Snowpark to extend its capabilities and build a complete data extraction process. Apply advanced data cleansing and transformation logic using Python. Why Use PARSE_DOC?
Deliver multimodal analytics with familiar SQL syntax Database queries are the underlying force that runs the insights across organizations and powers data-driven experiences for users. Traditionally, SQL has been limited to structureddata neatly organized in tables.
Collecting, cleaning, and organizing data into a coherent form for business users to consume are all standard data modeling and data engineering tasks for loading a data warehouse. Based on Tecton blog So is this similar to data engineering pipelines into a data lake/warehouse?
You have complex, semi-structureddata—nested JSON or XML, for instance, containing mixed types, sparse fields, and null values. It's messy, you don't understand how it's structured, and new fields appear every so often. Without a known schema, it would be difficult to adequately frame the questions you want to ask of the data.
The state-of-the-art neural networks that power generative AI are the subject of this blog, which delves into their effects on innovation and intelligent design’s potential. Multiple levels: Rawdata is accepted by the input layer. Receives rawdata, with each neuron representing a feature of the input.
In this blog post, we show how Rockset’s Smart Schema feature lets developers use real-time SQL queries to extract meaningful insights from raw semi-structureddata ingested without a predefined schema. In NoSQL systems, data is strongly typed but dynamically so.
Right now we’re focused on rawdata quality and accuracy because it’s an issue at every organization and so important for any kind of analytics or day-to-day business operation that relies on data — and it’s especially critical to the accuracy of AI solutions, even though it’s often overlooked.
Third-Party Data: External data sources that your company does not collect directly but integrates to enhance insights or support decision-making. These data sources serve as the starting point for the pipeline, providing the rawdata that will be ingested, processed, and analyzed.
Businesses benefit at large with these data collection and analysis as they allow organizations to make predictions and give insights about products so that they can make informed decisions, backed by inferences from existing data, which, in turn, helps in huge profit returns to such businesses. What is the role of a Data Engineer?
Structuringdata refers to converting unstructured data into tables and defining data types and relationships based on a schema. Autonomous data warehouse from Oracle. . What is Data Lake? . Essentially, a data lake is a repository of rawdata from disparate sources. Conclusion . .
Reading Time: 8 minutes In the world of data engineering, a mighty tool called DBT (Data Build Tool) comes to the rescue of modern data workflows. Imagine a team of skilled data engineers on an exciting quest to transform rawdata into a treasure trove of insights. Happy DBT-ing!
Business Intelligence and Artificial Intelligence are popular technologies that help organizations turn rawdata into actionable insights. While both BI and AI provide data-driven insights, they differ in how they help businesses gain a competitive edge in the data-driven marketplace.
Rawdata, however, is frequently disorganised, unstructured, and challenging to work with directly. Data processing analysts can be useful in this situation. Let’s take a deep dive into the subject and look at what we’re about to study in this blog: Table of Contents What Is Data Processing Analysis?
You have probably heard the saying, "data is the new oil". It is extremely important for businesses to process data correctly since the volume and complexity of rawdata are rapidly growing. Data Integration - ETL processes can be leveraged to integrate data from multiple sources for a single 360-degree unified view.
DE Zoomcamp 2.2.1 – Introduction to Workflow Orchestration Following last weeks blog , we move to data ingestion. We already had a script that downloaded a csv file, processed the data and pushed the data to postgres database. This week, we got to think about our data ingestion design.
Despite these limitations, data warehouses, introduced in the late 1980s based on ideas developed even earlier, remain in widespread use today for certain business intelligence and data analysis applications. While data warehouses are still in use, they are limited in use-cases as they only support structureddata.
Data pipelines are a significant part of the big data domain, and every professional working or willing to work in this field must have extensive knowledge of them. In broader terms, two types of data -- structured and unstructured data -- flow through a data pipeline.
These streams also continually deliver new fields and columns of data that can be incompatible with existing schemas. Which is why rawdata streams cannot be ingested by traditional rigid SQL databases. But some newer SQL databases can ingest streaming data by inspecting the data on the fly.
The Windward Maritime AI platform Lastly, Windward wanted to move their entire platform from batch-based data infrastructure to streaming. In this blog, we’ll describe the new data platform for Windward and how it is API first, enables rapid product iteration and is architected for real-time, streaming data.
A single car connected to the Internet with a telematics device plugged in generates and transmits 25 gigabytes of data hourly at a near-constant velocity. And most of this data has to be handled in real-time or near real-time. Variety is the vector showing the diversity of Big Data.
But while the technologies powering our access and analysis of data have matured, the mechanics behind understanding this data in a distributed environment have lagged behind. Here’s where data catalogs fall short and how data discovery platforms and tools can help ensure your data lake doesn’t turn into a data swamp.
In this blog post, we’ll discuss how we teach transformers to distinguish between products like a potato and a banana, thereby enhancing future demand prediction. By converting rawdata into valuable information, transformer models could significantly contribute to sustainability. Then you are in the right place!
of data engineer job postings on Indeed? If you are still wondering whether or why you need to master SQL for data engineering, read this blog to take a deep dive into the world of SQL for data engineering and how it can take your data engineering skills to the next level.
It also discusses available resources and tools, and the current data science landscape. Introduction of R as an optional language in data science, highlighting its strengths in statistics and visualization. Look into Dplyr in R for more efficient data manipulation tasks. This concludes our blog about data science roadmap.
Translating data into the required format facilitates cleaning and mapping for insight extraction. . A detailed explanation of the data manipulation concept will be presented in this blog, along with an in-depth exploration of the need for businesses to have data manipulation tools. What Is Data Manipulation? .
If you're looking to break into the exciting field of big data or advance your big data career, being well-prepared for big data interview questions is essential. Get ready to expand your knowledge and take your big data career to the next level! But the concern is - how do you become a big data professional?
We’ll take a closer look at variables that can impact your data next. Migration to the cloud Twenty years ago, your data warehouse (a place to transform and store structureddata) probably would have lived in an office basement, not on AWS or Azure. Rise of the Data Lakehouse Data warehouse or data lake?
This is where AWS Data Analytics comes into action, providing businesses with a robust, cloud-based data platform to manage, integrate, and analyze their data. In this blog, we’ll explore the world of Cloud Data Analytics and a real-life application of AWS Data Analytics. What is Data Analytics?
To build such ML projects, you must know different approaches to cleaning rawdata. From the outset of machine learning, it was challenging to work with unstructured data (image dataset) and transform it into structureddata (texts). You have to use libraries like Dora, Scrubadub, Pandas, NumPy, etc.,
Launched in 2014, Snowflake is one of the most popular cloud data solutions on the market. This blog walks you through what does Snowflake do , the various features it offers, the Snowflake architecture, and so much more. Table of Contents Snowflake Overview and Architecture What is Snowflake Data Warehouse?
There are several big data and business analytics companies that offer a novel kind of big data innovation through unprecedented personalization and efficiency at scale. Which big data analytic companies are believed to have the biggest potential?
Nevertheless, that is not the only job in the data world. Data professionals who work with rawdata like data engineers, data analysts, machine learning scientists , and machine learning engineers also play a crucial role in any data science project. How do I create a Data Engineer Portfolio?
This blog is your one-stop solution for the top 100+ Data Engineer Interview Questions and Answers. In this blog, we have collated the frequently asked data engineer interview questions based on tools and technologies that are highly useful for a data engineer in the Big Data industry.
Ace your big data interview by adding some unique and exciting Big Data projects to your portfolio. This blog lists over 20 big data projects you can work on to showcase your big data skills and gain hands-on experience in big data tools and technologies. are examples of semi-structureddata.
feature engineering or feature extraction when useful properties are drawn from rawdata and transformed into a desired form, and. The technology supports tabular, image, text, and video data, and also comes with an easy-to-use drag-and-drop tool to engage people without ML expertise. Source: Google Cloud Blog.
Online FM Music 100 nodes, 8 TB storage Calculation of charts and data testing 16 IMVU Social Games Clusters up to 4 m1.large Online FM Music 100 nodes, 8 TB storage Calculation of charts and data testing 16 IMVU Social Games Clusters up to 4 m1.large Hadoop is used at eBay for Search Optimization and Research.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content