This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary The process of exposing your data through a SQL interface has many possible pathways, each with their own complications and tradeoffs. One of the recent options is Rockset, a serverless platform for fast SQL analytics on semi-structured and structureddata.
Deliver multimodal analytics with familiar SQL syntax Database queries are the underlying force that runs the insights across organizations and powers data-driven experiences for users. Traditionally, SQL has been limited to structureddata neatly organized in tables.
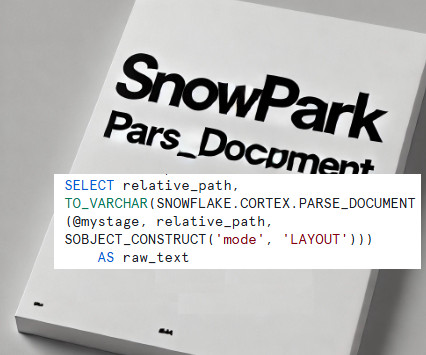
Traditionally, this function is used within SQL to extract structured content from documents. However, Ive taken this a step further, leveraging Snowpark to extend its capabilities and build a complete data extraction process. Apply advanced data cleansing and transformation logic using Python. Why Use PARSE_DOC?
The alternative, however, provides more multi-cloud flexibility and strong performance on structureddata. Its multi-cluster shared data architecture is one of its primary features. Ideal for: Fabric makes the administration of data lakes much simpler; Snowflake provides flexible options for using external lakes.
High quality data and analytics helps PropTech companies gain deeper context on properties and locations, build richer models with accurate information, and more. Let’s further explore the impact of data in this industry as we count down the top 5 PropTech blog posts of 2022. #5
[link] QuantumBlack: Solving data quality for gen AI applications Unstructured data processing is a top priority for enterprises that want to harness the power of GenAI. It brings challenges in data processing and quality, but what data quality means in unstructured data is a top question for every organization.
As training data becomes more scarce, companies like OpenAI believe that synthetic data will be an important part of how they train their models in the future. But is synthetic data a long-term solution? Probably not.
In this blog post, we show how Rockset’s Smart Schema feature lets developers use real-time SQL queries to extract meaningful insights from raw semi-structureddata ingested without a predefined schema. In NoSQL systems, data is strongly typed but dynamically so.
We are excited to announce a new data type called variant for semi-structureddata. Variant provides an order of magnitude performance improvements compared.
This blog post expands on that insightful conversation, offering a critical look at Iceberg's potential and the hurdles organizations face when adopting it. Start the Data Governance Process: Don't wait until the last minute to build the data governance framework.
[link] Discord: How Discord Uses Open-Source Tools for Scalable Data Orchestration & Transformation Discord writes about its migration journey from a homegrown orchestration engine to Dagster. Techniques for turning text data and documents into vector embeddings and structureddata.
Data Vault as a practice does not stipulate how you transform your data, only that you follow the same standards to populate business vault link and satellite tables as you would to populate raw vault link and satellite tables. Based on Tecton blog So is this similar to data engineering pipelines into a data lake/warehouse?
This blog captures the current state of Agent adoption, emerging software engineering roles, and the use case category. Generative AI demands the processing of vast amounts of diverse, unstructured data (e.g., meeting recordings and videos), which contrasts with traditional SQL-centric systems for structureddata.
The word “data” is ubiquitous in narratives of the modern world. And data, the thing itself, is vital to the functioning of that world. This blog discusses quantifications, types, and implications of data. Quantifications of data. Addressing the challenges of data.
Rather than defining schema upfront, a user can decide which data and schema they need for their use case. Snowflake has long supported semi-structureddata types and file formats like JSON, XML, Parquet, and more recently storage and processing of unstructured data such as PDF documents, images, videos, and audio files.
As training data becomes more scarce, companies like OpenAI believe that synthetic data will be an important part of how they train their models in the future. But is synthetic data a long-term solution? Probablynot.
What are some of the primary challenges associated with data modeling that contribute to the long lead times for data requests or outright project Datafailure? What are some of the foundational skills and knowledge that are necessary for effective modeling of data warehouses?
‘True’ hybrid incorporates data stores that are capable of maintaining and harnessing data, no matter the format. With that, we’re seeing the importance of ‘true’ hybrid cloud as organizations begin to shift, favoring data architecture that’s highly flexible, scalable, and adaptable. appeared first on Cloudera Blog.
In this blog, I will demonstrate the value of Cloudera DataFlow (CDF) , the edge-to-cloud streaming data platform available on the Cloudera Data Platform (CDP) , as a Data integration and Democratization fabric. The post How Cloudera Data Flow Enables Successful Data Mesh Architectures appeared first on Cloudera Blog.
Data scientists are likely to use a variety of different tools to move through their processes. It could be a homespun version of PostgreSQL on their local machine for exploring structureddata sets; to visualize, they could be writing code or using a BI tool like Tableau or PowerBI.
Structured and Unstructured Data: A Treasure Trove of Insights Enterprise data encompasses a wide array of types, falling mainly into two categories: structured and unstructured. Structureddata is highly organized and formatted in a way that makes it easily searchable in databases and data warehouses.
As mentioned in my previous blog on the topic , the recent shift to remote working has seen an increase in conversations around how data is managed. It established a data governance framework within its enterprise data lake. The post 2020 Data Impact Award Winner Spotlight: Merck KGaA appeared first on Cloudera Blog.
[link] Jason Liu & Eugene Yan: 10 Ways to Be Data Illiterate (and How to Avoid Them) If you ask any executives in an organization, they will say they are data-driven. Thus, the data team has more responsibility than just ingesting and building the data pipeline. It is often an expression of desire rather than reality.
A database is a structureddata collection that is stored and accessed electronically. According to a database model, the organization of data is known as database design. Blogs KDnuggets: It is one of the compelling and regularly updated sites for blogs on analytics, Data Science, Big Data and machine learning.
In today’s data-driven landscape, organizations need robust solutions for managing, analyzing, and visualizing information. Microsoft offers two standout platforms that fulfill these needs, each addressing different stages of the data lifecycle. This Blog post explores the differences and synergy between the two.
In the last few years, Commercial Insurers have been making great strides in expanding the use of their data. The approach is very evolutionary; the initial focus tends to be aimed at cost savings and starts with structureddata. Then there is a recognition that there is so much more that can be done with the data.
Today’s platform owners, business owners, data developers, analysts, and engineers create new apps on the Cloudera Data Platform and they must decide where and how to store that data. Structureddata (such as name, date, ID, and so on) will be stored in regular SQL databases like Hive or Impala databases.
In modern enterprises, the exponential growth of data means organizational knowledge is distributed across multiple formats, ranging from structureddata stores such as data warehouses to multi-format data stores like data lakes.
However, the performance of RAG applications is far from perfect, prompting innovations like integrating knowledge graphs, which structuredata into interconnected entities and relationships. The post Streamlining Generative AI Deployment with New Accelerators appeared first on Cloudera Blog. To learn more, click here.
Thrift Integration for Enhanced Parsing Leveraging the structureddata serialization capabilities of Apache Thrift presents a promising avenue for optimizing the parsing of incoming data. To learn more about engineering at Pinterest, check out the rest of our Engineering Blog and visit our Pinterest Labs site.
We live in a hybrid data world. In the past decade, the amount of structureddata created, captured, copied, and consumed globally has grown from less than 1 ZB in 2011 to nearly 14 ZB in 2020. Impressive, but dwarfed by the amount of unstructured data, cloud data, and machine data – another 50 ZB.
Learn more about TDAA and the preview program for Pancake, its scan and discovery Snowflake Native App, at datapancake.com or read the company’s post on the Snowflake Builder Blog on Medium for technical details.
Using easy-to-define policies, Replication Manager solves one of the biggest barriers for the customers in their cloud adoption journey by allowing them to move both tables/structureddata and files/unstructured data to the CDP cloud of their choice easily. Sentry permissions exported from CDH to Ranger policies on Data Lake. .
In this guest blog post, HomeToGo’s director of data, Stephan Claus, explains why the company migrated to Snowflake to meet its data needs. This article is based on Stephan’s presentation during the Snowflake Data World Tour 2022. Something that is especially handy is Snowflake’s support for semi-structureddata.
Modernizing your data warehousing experience with the cloud means moving from dedicated, on-premises hardware focused on traditional relational analytics on structureddata to a modern platform. The post Key considerations when making a decision on a Cloud Data Warehouse appeared first on Cloudera Blog.
A common pitfall in the development of data platforms is that they are built around the boundaries of point solutions and are constrained by the technological limitations (e.g., a technology choice such as Spark Streaming is overly focused on throughput at the expense of latency) or data formats (e.g.,
In an ETL-based architecture, data is first extracted from source systems, then transformed into a structured format, and finally loaded into data stores, typically data warehouses. This method is advantageous when dealing with structureddata that requires pre-processing before storage.
txt’,’r’) as f: pass Conclusion: Hope this blog has help you understand some common features of Python, as well as the important updates and core concepts of python3. So, variable can be declared as below. varName = value Example x = 1 that means we have assigned number 1 which is an integer to variable x y = 3.14
Challenges & Opportunities in the Infra Data Space Security Events Platform for Anomaly Detection How can we develop a complex event processing system to ingest semi-structureddata predicated on schema contracts from hundreds of sources and transform it into event streams of structureddata for downstream analysis?
Given the characteristic, are we having a “Big Data” problem? Can we spin off a machine with all the data stack and run through the analysis? The author writes an exciting blog, Modern data stack in a Box!! link] Data Engineering Central: Why is everyone trying to kill Airflow?
The following are key attributes of our platform that set Cloudera apart: Unlock the Value of Data While Accelerating Analytics and AI The data lakehouse revolutionizes the ability to unlock the power of data. The post Cloudera Named a Visionary in the Gartner MQ for Cloud DBMS appeared first on Cloudera Blog.
Through processing vast amounts of structured and semi-structureddata, AI and machine learning enabled effective fraud prevention in real-time on a national scale. . Governments need to ensure that a sound data strategy is at the core of their digital transformation journeys to reap its full benefits. .
All of the code and setup discussed in this blog post can be found in this GitHub repository , so you can try it yourself! Instead of storing tables and columns, Neo4j represents all data as a graph, meaning that the data is a set of nodes with labels and relationships. The approach we’ll use works with any Kafka run though.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content