This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Modern large-scale recommendation systems usually include multiple stages where retrieval aims at retrieving candidates from billions of candidate pools, and ranking predicts which item a user tends to engage from the trimmed candidate set retrieved from early stages [2]. General multi-stage recommendation system design in Pinterest.
Juraj included system monitoring parts which monitor the server’s capacity he runs the app on: The monitoring page on the Rides app And it doesn’t end here. Juraj created a systems design explainer on how he built this project, and the technologies used: The systems design diagram for the Rides application The app uses: Node.js
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. In this blog, we will discuss: What is the Open Table format (OTF)? These systems are built on open standards and offer immense analytical and transactional processing flexibility.
It is a critical and powerful tool for scalable discovery of relevant data and data flows, which supports privacy controls across Metas systems. In this blog, we will delve into an early stage in PAI implementation: data lineage. Data lineage enables us to efficiently navigate these assets and protect user data.
Many of our customers are shifting from monolithic prompts with general-purpose models to specialized compound AI systems to achieve the quality needed for.
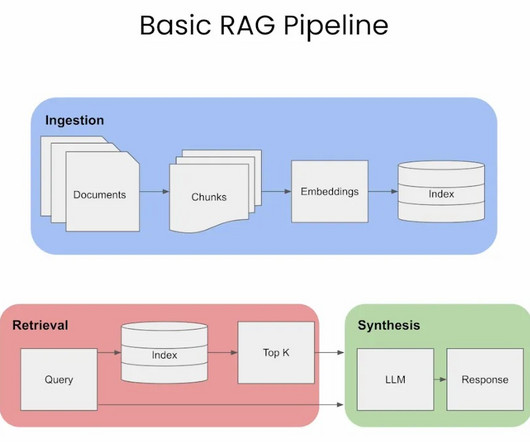
The ability to extract information from vast amounts of text has made question-answering (QA) systems essential in the modern era of AI-driven apps. RAG-based question-answering systems use large language models to generate human-like responses to user queries.
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
When you hear the term System Hacking, it might bring to mind shadowy figures behind computer screens and high-stakes cyber heists. In this blog, we’ll explore the definition, purpose, process, and methods of prevention related to system hacking, offering a detailed overview to help demystify the concept.
Over the past four weeks, I took a break from blogging and LinkedIn to focus on building nao. AI companies are aiming for the moon—AGI—promising it will arrive once OpenAI develops a system capable of generating at least $100 billion in profits. Meanwhile, the AI landscape remains unpredictable.
Systems must be capable of handling high-velocity data without bottlenecks. However, leveraging AI agents like Striims Sherlock and Sentinel, which enable encryption and masking for PII, can help ensure that data is safe even in the event a breach occurs. As you can see, theres a lot to consider in adopting real-time AI.
For a realtime alerting system! I have since talked with engineers on the OpsGenie team who said that it felt that Atlassian rushed the OpsGenie integration - after buying the company - onto their unified internal stack, ignoring warnings that an outage in their identity system would take OpsGenie down. Yes: 2 for weeks!
This blog post is the second in a three-part series on migrations. A consolidated data system to accommodate a big(ger) WHOOP When a company experiences exponential growth over a short period, it’s easy for its data foundation to feel a bit like it was built on the fly.
The blog highlights how emerging AI tools automate otherwise cognitively intensive manual tasks to bring reliability in software engineering. link] Whatnot: Evolving Feed Ranking at Whatnot Whatnot describes their transition from a batch prediction system to an online inference framework for ranking, which is shown in their "For You Feed."
The blog is an excellent summary of the existing unstructured data landscape. It is exciting to read probably the first blog on building a vector search infrastructure at scale. The blog from Meta discusses how it designed a privacy-preserving storage.
Additionally, multiple copies of the same data locked in proprietary systems contribute to version control issues, redundancies, staleness, and management headaches. The post Octopai Acquisition Enhances Metadata Management to Trust Data Across Entire Data Estate appeared first on Cloudera Blog.
Finally, Shane outlines how observability is crucial for emerging AI/ML workflows like RAG pipelines, discussing the monitoring of vector databases (like Pinecone), unstructured data, and the entire AI system lifecycle, concluding with a look at Monte Carlo’s exciting roadmap, including AI-powered troubleshooting agents.
The blog highlights how moving from 6-character base-64 to 20-digit base-2 file distribution brings more distribution in S3 and reduces request failures. The blog is a good summary of how to use Snowflake QUERY_TAG to measure and monitor query performance. The blog post made me curious to understand DataFusion's internals.
Meta’s vast and diverse systems make it particularly challenging to comprehend its structure, meaning, and context at scale. We discovered that a flexible and incremental approach was necessary to onboard the wide variety of systems and languages used in building Metas products. We believe that privacy drives product innovation.
The blog took out the last edition’s recommendation on AI and summarized the current state of AI adoption in enterprises. The simplistic model expressed in the blog made it easy for me to reason about the transactional system design. Kafka is probably the most reliable data infrastructure in the modern data era.
Behind the scenes, a myriad of systems and services are involved in orchestrating the product experience. These backend systems are consistently being evolved and optimized to meet and exceed customer and product expectations. This blog series will examine the tools, techniques, and strategies we have utilized to achieve this goal.
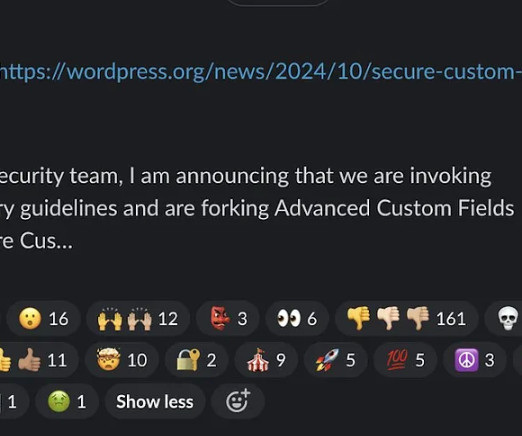
Corporate conflict recap Automattic is the creator of open source WordPress content management system (CMS), and WordPress powers an incredible 43% of webpages and 65% of CMSes. This event is shameful and unprecedented in the history of open source on the web. Automattic raised $980M in venture funding and was valued at $7.5B
System metrics, such as inference latency and throughput, are available as Prometheus metrics. Users can manage all of their models and applications on the Cloudera AI Inference service with common CI/CD systems using Cloudera service accounts, also known as machine users.
As organizations integrate AI agent systems into. Generative AI has become a powerful reality, transforming industries by enhancing customer experiences and automating decisions.
This blog will explore the significant advancements, challenges, and opportunities impacting data engineering in 2025, highlighting the increasing importance for companies to stay updated. In 2025, this blog will discuss the most important data engineering trends, problems, and opportunities that companies should be aware of.
I found the blog to be a fresh take on the skill in demand by layoff datasets. DeepSeek continues to impact the Data and AI landscape with its recent open-source tools, such as Fire-Flyer File System (3FS) and smallpond. The blog provides an excellent analysis of smallpond compared to Spark and Daft.
Semih is a researcher and entrepreneur with a background in distributed systems and databases. He then pursued his doctoral studies at Stanford University, delving into the complexities of database systems.
Special thanks to Phillip Jones, Senior Product Manager, and Harshal Brahmbhatt, Systems Engineer from Cloudflare for their contributions to this blog. Organizations across.
This blog dives into the remarkable journey of a data team that achieved unparalleled efficiency using DataOps principles and software that transformed their analytics and data teams into a hyper-efficient powerhouse. A software system where processes can be developed and shared is required. Here is another example.
In this blog, we will go through the technical design and share some offline and online results for our LLM-based search relevance pipeline. Pin Text Representations Pins on Pinterest are rich multimedia entities that feature images, videos, and other contents, often linked to external webpages or blogs.
In this blog post, we’ll explore what CDC is, why it’s important, and our journey of implementing Generic CDC solutions for all online databases at Pinterest. This is crucial for applications that require up-to-date information, such as fraud detection systems or recommendation engines. What is Change Data Capture?
It requires a state-of-the-art system that can track and process these impressions while maintaining a detailed history of each profiles exposure. In this multi-part blog series, we take you behind the scenes of our system that processes billions of impressions daily.
A little over a year ago, we shared a blog post about our journey to enhance customers meal planning experience with personalized recipe recommendations. We explained how a system that learns from your tastes and habits could solve this issue, ultimately making the daily task of choosing meals both effortless and inspiring.
I found the product blog from QuantumBlack gives a view of data quality in unstructured data. link] Pinterest: Advancements in Embedding-Based Retrieval at Pinterest Homefeed Pinterest writes about its embedding-based retrieval system enhancements for Homefeed personalization and engagement.
He sees logs as a treasure trove of insights and believes effective log analysis is critical in today’s complex systems. We discussed his early experiences with distributed systems, including his work on creating graphs and entity resolution. Lastly, we go in-depth into Scanner.dev, covering what it is and how it works.
It covers nine categories: storage systems, data lake platforms, processing, integration, orchestration, infrastructure, ML/AI, metadata management, and analytics. I found the blog to be a comprehensive roadmap for data engineering in 2025. I wonder if these systems expand more capabilities that eventually fall on their own weight.
[link] Alibaba: A Comprehensive Analysis and Practical Implementation of the New Features in the MCP Specification When I delved further into learning about the MCP specification, Alibaba's blog was a handy guide to understanding the protocol spec's evolution over the last four months.
Foundation Capital: A System of Agents brings Service-as-Software to life software is no longer simply a tool for organizing work; software becomes the worker itself, capable of understanding, executing, and improving upon traditionally human-delivered services. It's good to know about Dapr and restate.dev.
This followed a previous blog on the same topic. In this context, having a single configuration system to manage a ML project holistically gives users increased project coherence and decreased projectrisk. Configuration in Metaboost Ease of configuration and templatizing are core values of Metaboost.
In recent years, while managing Pinterests EC2 infrastructure, particularly for our essential online storage systems, we identified a significant challenge: the lack of clear insights into EC2s network performance and its direct impact on our applications reliability and performance. 4xl with up to 12.5
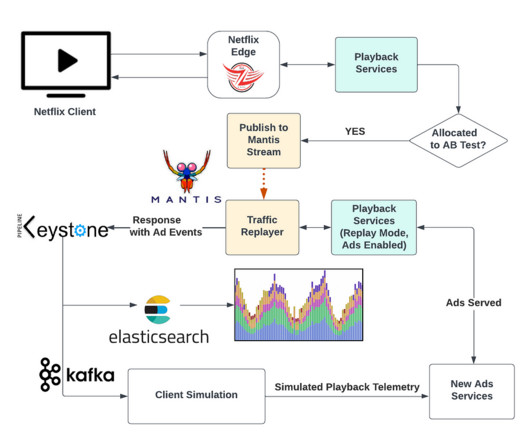
In this blog post, we’ll discuss the methods we used to ensure a successful launch, including: How we tested the system Netflix technologies involved Best practices we developed Realistic Test Traffic Netflix traffic ebbs and flows throughout the day in a sinusoidal pattern. Basic with ads was launched worldwide on November 3rd.
However, due to the absence of a control group in these countries, we adopt a synthetic control framework ( blog post ) to estimate the counterfactual scenario. We further break down performance by various dimensions, e.g. content type, genre, etc to help us pinpoint specific areas where the ASR system may encounter difficulties.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content