This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Were sharing details about Glean , Metas open source system for collecting, deriving and working with facts about source code. In August 2021 we open-sourced our code indexing system Glean. Glean collects information about source code and provides it to developer tools through an efficient and flexible query language.
On 22 February 2023, Google announced its coding competitions are coming to an end: The visual that accompanied the announcement of the end of Google’s coding competitions. Code Jam: competitive programming. Hash Code: team programming. Google Code Jam I/O for Women: algorithmic programming.
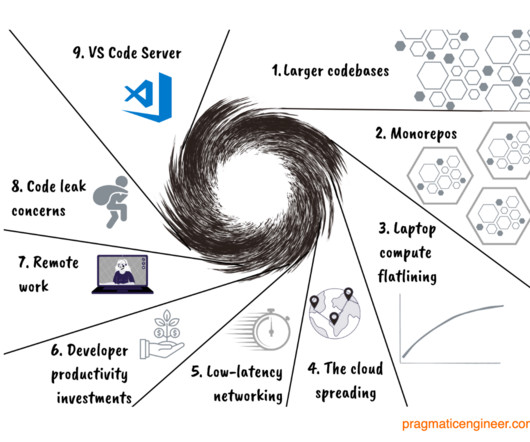
Every day, there’s more code at a tech company, not less. This means more repositories are needed, which are fast enough to build and work with, but which increase fragmentation. However, monorepos result in codebases growing large, so that even checking out the code or updating to the head can be time consuming.
Personalization Stack Building a Gift-Optimized Recommendation System The success of Holiday Finds hinges on our ability to surface the right gift ideas at the right time. Unified Logging System: We implemented comprehensive engagement tracking that helps us understand how users interact with gift content differently from standardPins.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Dagster offers a new approach to building and running data platforms and data pipelines. As a listener to the Data Engineering Podcast you can get a special discount of 20% off your ticket by using the promo code dataengpod20.
This presented challenges for users in building more complex multi-step pipelines that are typical of DE workflows. In the process several key themes emerged: Low/No-code. Writing code is error prone and requires trial and error. By far the biggest barrier for new users is creating custom Airflow DAGs. Long-tail of operators.
Buck2 is a from-scratch rewrite of Buck , a polyglot, monorepo build system that was developed and used at Meta (Facebook), and shares a few similarities with Bazel. As you may know, the Scalable Builds Group at Tweag has a strong interest in such scalable build systems. fix the code # fix code 7.
He’s solved interesting engineering challenges along the way, too – like building observability for Amazon’s EC2 offering, and being one of the first engineers on Uber’s observability platform. From learning to code in Australia, to working in Silicon Valley How did I learn to code?
The DevOps lifecycle phases are in order from left to right, with each phase building upon the last. It is about automating the process of building, testing, deploying, and maintaining applications to reduce time-to-market for new features and functionality. Code - During this point, the code is being developed.
How to Build a Data Dashboard Prototype with Generative AI A book reading data visualization withVizro-AI This article is a tutorial that shows how to build a data dashboard to visualize book reading data taken from goodreads.com. Its still not complete and can definitely be extended and improved upon.
Building more efficient AI TLDR : Data-centric AI can create more efficient and accurate models. Full code and results available here onGitHub. Moving experiment configs to a YAML, automatically saving results to a file, and having o1 write my visualization code made life mucheasier. Image byauthor. Image byauthor.
This tutorial aims to solve this by providing the definitive guide to dimensional modeling with dbt. Don’t repeat yourself** : Dimensions can be easily re-used with other fact tables to avoid duplication of effort and code logic. Performing joins between fact and dimension tables are made simple through the use of surrogate keys.
Today, we’ll talk about how Machine Learning (ML) can be used to build a movie recommendation system - from researching data sets & understanding user preferences all the way through training models & deploying them in applications. How to Build a Movie Recommendation System in Python?
In this episode Nick King discusses how you can be intentional about data creation in your applications and services to reduce the friction and errors involved in building data products and ML applications. Can you share your definition of "behavioral data" and how it is differentiated from other sources/types of data?
That said, this tutorial aims to introduce airflow-parse-bench , an open-source tool I developed to help data engineers monitor and optimize their Airflow environments, providing insights to reduce code complexity and parsetime. Parsing occurs every time Airflow processes your Python files to build the DAGs dynamically.
a macro — a macro is a Jinja function that either do something or return SQL or partial SQL code. In a nutshell the dbt journey starts with sources definition on which you will define models that will transform these sources to something else you'll need in your downstream usage of the data.
For this feature, Python encloses certain code editors and python IDEs used for software development say, Python itself. This article looks at the top python IDEs and code editors along with their features, pros, and cons and discusses the best suited for writing Python codes. What is a Code Editor?
Chris Lee is the founder of US-based Launch School , which is one of the “anti bootcamp coding schools,” and an organization which impresses me. As a coding school operator, Chris has a unique perspective that gives him insight into lots of different companies and engineering departments.
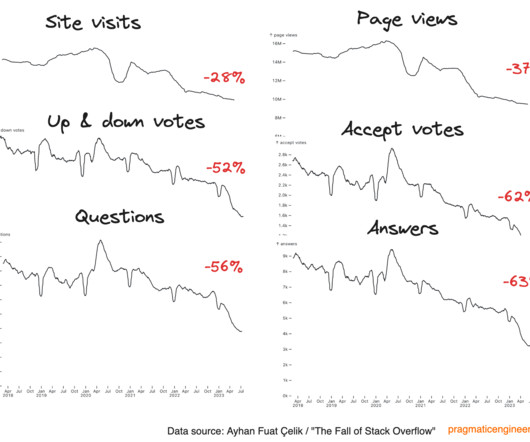
Ayhan visualized this data and observed a definite fall in all metrics: page views, visits, questions asked, votes. Q&A activity is definitely down: the company is aware of this metric taking a dive, and said they’re actively working to address it. When it comes to GenAI, Stack Overflow for Teams is getting a lot more love.
Part 2: Navigating Ambiguity By: VarunKhaitan With special thanks to my stunning colleagues: Mallika Rao , Esmir Mesic , HugoMarques Building on the foundation laid in Part 1 , where we explored the what behind the challenges of title launch observability at Netflix, this post shifts focus to the how.
Pioneering Data Observability: Data, Code, Infrastructure, & AI The four dimensions of data observability: data, code, infrastructure, and ai? Unreliable data doesn’t live in a silo… it’s impacted by all three ingredients of the data ecosystem: data + code + infrastructure. You look at the code.
If you want to build a warehouse that gives you both control and flexibility then you might consider building on top of the venerable PostgreSQL project. In this episode Thomas Richter and Joshua Drake share their advice on how to build a production ready data warehouse with Postgres.
If you need to deal with massive data, at high velocities, in milliseconds, then Aerospike is definitely worth learning about. If you’re a data engineering podcast listener, you get credits worth $3000 on an annual subscription Modern data teams are dealing with a lot of complexity in their data pipelines and analytical code.
How to improve the code quality of your dbt models with unit tests and TDD All you need to know to start unit testing your dbt SQL models Photo by Christin Hume on Unsplash If you are a data or analytics engineer, you are probably comfortable writing SQL models and testing for data quality with dbt tests. Kent Beck ?
To help customers overcome these challenges, RudderStack and Snowflake recently launched Profiles , a new product that allows every data team to build a customer 360 directly in their Snowflake Data Cloud environment. Gone are the months of complex data wrangling and the constraints of no-code SaaS tools.
In this episode Lior Gavish, Lior Solomon, and Atul Gupte share their view of what it means to have a data platform, discuss their experiences building them at various companies, and provide advice on how to treat them like a software product. Who are the stakeholders in a data platform? When is a data platform the wrong choice?
It assesses your data, deploys production testing, monitors progress, and helps you build a constituency within your company for lasting change. Enhanced Testing & Profiling Copy & Move Tests with Ease The Test Definitions page now supports seamless test migration between test suites.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Dagster offers a new approach to building and running data platforms and data pipelines. Visit dataengineeringpodcast.com/data-council and use code dataengpod20 to register today! Your first 30 days are free!
Get started with Airbyte and Cloud Storage Coding the connectors yourself? Not only do you have to make it scalable and useful, but every architectural decision builds up over time. And building them yourself from scratch gives you full control of how you want them to behave. Building the data source.
Code implementations for ML pipelines: from raw data to predictions Photo by Rodion Kutsaiev on Unsplash Real-life machine learning involves a series of tasks to prepare the data before the magic predictions take place. And that’s it.
Prediction: AI copilots that can complete a sentence, correct code errors, etc. And if Twitter has taught us anything, Sam Altman definitely has a lot to say.) We’re seeing teams build out vector databases or embedding models at scale. According to Tomasz, the current state of AI can be summed up in three categories.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Dagster offers a new approach to building and running data platforms and data pipelines. Visit dataengineeringpodcast.com/data-council and use code dataengpod20 to register today! Your first 30 days are free!
When scaling data science and ML workloads, organizations frequently encounter challenges in building large, robust production ML pipelines. Define an Entity: Define a Feature View: feature_df is a Snowpark DataFrame object containing your feature definition.
One of the main reasons this feature exists is just like with food samples, to give you “a taste” of the production quality ETL code that you could encounter inside the Netflix data ecosystem. This is one way to build trust with our internal user base. " , country_code STRING COMMENT "Country code of the playback session."
Building a maintainable and modular LLM application stack with Hamilton in 13 minutes LLM Applications are dataflows, use a tool specifically designed to express them LLM stacks. Hamilton is great for describing any type of dataflow , which is exactly what you’re doing when building an LLM powered application. Image from pixabay.
While such apps are being created at a very fast pace, there are two main challenges: Many modern powerful apps utilize containers to package and use code; however, this typically requires data to be moved from protected environments, increasing data privacy and security risk.
What if you could streamline your efforts while still building an architecture that best fits your business and technology needs? At BUILD 2024, we announced several enhancements and innovations designed to help you build and manage your data architecture on your terms. Here’s a closer look.
Summary One of the perennial challenges of data analytics is having a consistent set of definitions, along with a flexible and performant API endpoint for querying them. a framework for building analytics APIs to power your applications and BI dashboards Interview Introduction How did you get involved in the area of data management?
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode.
Users benefit from uniform, comparable code style, across multiple languages, with the convenience of a single formatter tool. In this first release, we have concentrated on formatting OCaml code, capitalising on the OCaml expertise within the Topiary Team and our colleague, Nicolas Jeannerod. Expect idempotency. Prettier ).
Such a log would build confidence that Glassdoor is a neutral platform which is only enforcing its own terms and conditions, and could validate this. However, there’s a definite and ongoing uptick since the mid-2021. month-long code freeze at Stack Overflow. What’s going on, and when will Bedrock be available?
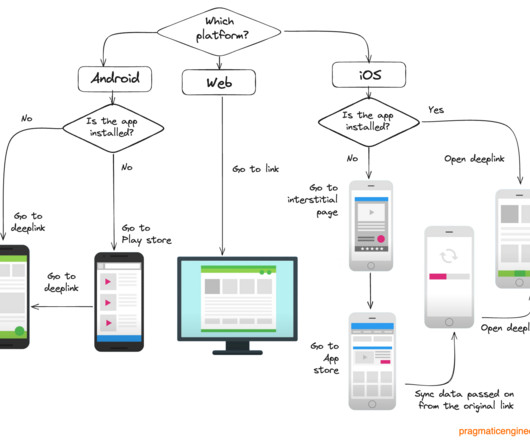
These links were especially helpful for: Promotions and marketing campaigns QR codes Content sharing links that “just work” Converting desktop users to mobile ones The shutdown Dynamic links powered Firebase Invites: an app invite service where users could send app invite links to their friends, to drive installation of the app.
Audacity doesn’t require coding skills. Commercial audio sets for machine learning are definitely more reliable in terms of data integrity than free ones. Building an app for snore and teeth grinding detection. AltexSoft & SleepScore Labs: Building an iOS App for Snoring and Teeth Grinding Detection.
In this episode Ketan Umare and Haytham Abuelfutuh share the story of the Flyte project and how their work at Union is focused on supporting and scaling the code and community that has made Flyte successful. What are the core primitives that Flyte exposes for building up complex workflows? What do you see as the closest alternatives?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content