This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary The software applications that we build for our businesses are a rich source of data, but accessing and extracting that data is often a slow and error-prone process. Rookout has built a platform to separate the datacollection process from the lifecycle of your code.
Summary Event based data is a rich source of information for analytics, unless none of the event structures are consistent. The team at Iteratively are building a platform to manage the end to end flow of collaboration around what events are needed, how to structure the attributes, and how they are captured.
As data continues to become more complex, it is critical to have effective ways to present this information. With the explosion of AI/ML, users want to be able to interact with their data and ML models. However, building such data apps has not been easy.
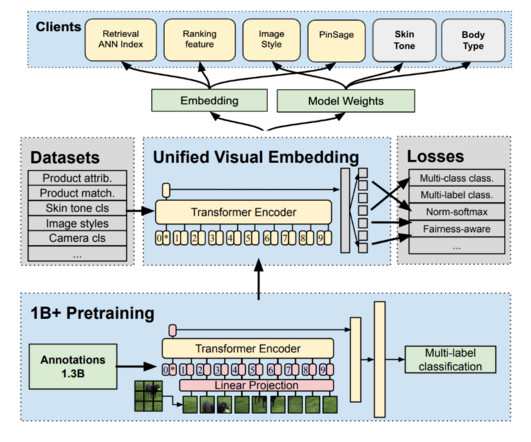
Personalization Stack Building a Gift-Optimized Recommendation System The success of Holiday Finds hinges on our ability to surface the right gift ideas at the right time. Unified Logging System: We implemented comprehensive engagement tracking that helps us understand how users interact with gift content differently from standardPins.
Speaker: Maher Hanafi, VP of Engineering at Betterworks & Tony Karrer, CTO at Aggregage
He'll delve into the complexities of datacollection and management, model selection and optimization, and ensuring security, scalability, and responsible use.
In this episode he explains the datacollection and preparation process, the collection of model types and sizes that work together to power the experience, and how to incorporate it into your workflow to act as a second brain. Data lakes are notoriously complex. Your first 30 days are free! Sponsored By: Starburst : 
















































Let's personalize your content