This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In today’s data-driven world, developer productivity is essential for organizations to build effective and reliable products, accelerate time to value, and fuel ongoing innovation. For a deeper dive into Snowflake’s Python API and other native Snowflake DevOps features, register for the Snowflake Data Cloud Summit 2024.
Summary How much time do you spend maintaining your datapipeline? This was a fascinating conversation with someone who has spent his entire career working on simplifying complex data problems. How does the data-centric approach of DataCoral differ from the way that other platforms think about processing information?
The data generated was as varied as the departments relying on these applications. Some departments used IBM Db2, while others relied on VSAM files or IMS databases creating complex data governance processes and costly datapipeline maintenance.
To tackle these challenges, we’re thrilled to announce CDP Data Engineering (DE) , the only cloud-native service purpose-built for enterprise data engineering teams. Native Apache Airflow and robust APIs for orchestrating and automating job scheduling and delivering complex datapipelines anywhere.
He highlights the role of data teams in modern organizations and how Synq is empowering them to achieve this. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Data lakes are notoriously complex.
When data reaches the Gold layer, it is highly curated and structured, offering a single version of the truth for decision-makers across the organization. We have also seen a fourth layer, the Platinum layer , in companies’ proposals that extend the Datapipeline to OneLake and Microsoft Fabric.
With Astro, you can build, run, and observe your datapipelines in one place, ensuring your mission critical data is delivered on time. Generative AI demands the processing of vast amounts of diverse, unstructured data (e.g., Generative AI demands the processing of vast amounts of diverse, unstructured data (e.g.,
impactdatasummit.com Thumbtack: What we learned building an ML infrastructure team at Thumbtack Thumbtack shares valuable insights from building its ML infrastructure team. The blog emphasizes the importance of starting with a clear client focus to avoid over-engineering and ensure user-centric development.
In 2020, Snowflake announced a new global competition to recognize the work of early-stage startups building their apps — and their businesses — on Snowflake, offering up to $250,000 in investment as the top prize. Just as varied was the list of Snowflake tech that early-stage startups are using to drive their innovative entries.
Snowflake is completely managed, but its main focus is on the data warehouse layer, and users need to integrate with other tools for BI, ML, or ETL. Ideal for: Business-centric workflows involving fabric Snowflake = environments with a lot of developers and data engineers 2.
Segment created the Unify product to reduce the burden of building a comprehensive view of customers and synchronizing it to all of the systems that need it. In this episode Kevin Niparko and Hanhan Wang share the details of how it is implemented and how you can use it to build and maintain rich customer profiles.
TL;DR After setting up and organizing the teams, we are describing 4 topics to make data mesh a reality. How do we builddata products ? The next problem will be the diversity of these mini data platforms (because of the configuration) and you even go deeper in problems with managing different technologies or version.
One paper suggests that there is a need for a re-orientation of the healthcare industry to be more "patient-centric". Furthermore, clean and accessible data, along with data driven automations, can assist medical professionals in taking this patient-centric approach by freeing them from some time-consuming processes.
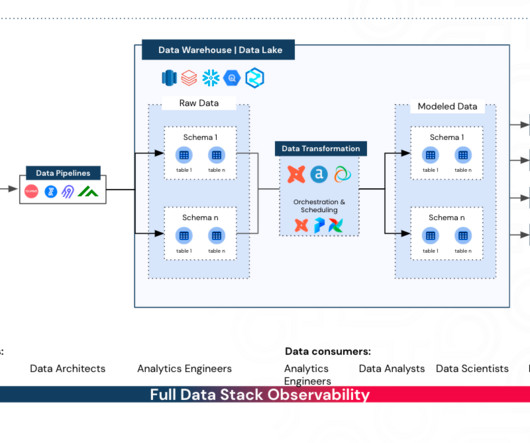
In the modern world of data engineering, two concepts often find themselves in a semantic tug-of-war: datapipeline and ETL. Fast forward to the present day, and we now have datapipelines. Data Ingestion Data ingestion is the first step of both ETL and datapipelines.
Going into the DataPipeline Automation Summit 2023, we were thrilled to connect with our customers and partners and share the innovations we’ve been working on at Ascend. The summit explored the future of datapipeline automation and the endless possibilities it presents.
In the fast-paced world of software development, the efficiency of build processes plays a crucial role in maintaining productivity and code quality. At ThoughtSpot , while Gradle has been effective, the growing complexity of our projects demanded a more sophisticated approach to understanding and optimizing our builds.
Summary Data engineers have typically left the process of data labeling to data scientists or other roles because of its nature as a manual and process heavy undertaking, focusing instead on building automation and repeatable systems. Data stacks are becoming more and more complex.
NVidia released Eagle a vision-centric multimodal LLM — Look at the example in the Github repo, given an image and a user input the LLM is able to answer things like "Describe the image in detail" or "Which car in the picture is more aerodynamic" based on a drawing. What's your question?
Data Engineering is typically a software engineering role that focuses deeply on data – namely, data workflows, datapipelines, and the ETL (Extract, Transform, Load) process. What is the role of a Data Engineer? Data scientists and data Analysts depend on data engineers to build these datapipelines.
To enable LGIM to better utilize its wealth of data, LGIM required a centralized platform that made internal data discovery easy for all teams and could securely integrate external partners and third-party outsourced datapipelines.
Of course, this is not to imply that companies will become only software (there are still plenty of people in even the most software-centric companies), just that the full scope of the business is captured in an integrated software defined process. Our approach to building this platform is from the bottom up. Confluent’s mission.
DataOps is fundamentally about eliminating errors, reducing cycle time, building trust and increasing agility. The datapipelines must contend with a high level of complexity – over seventy data sources and a variety of cadences, including daily/weekly updates and builds.
This means moving beyond product-centric thinking to a data-driven customer experience model that’s consistent across all channels. Next, the wealth management industry is also shifting away from a product focus to a client-centric model. DataOS is the world’s first operating system.
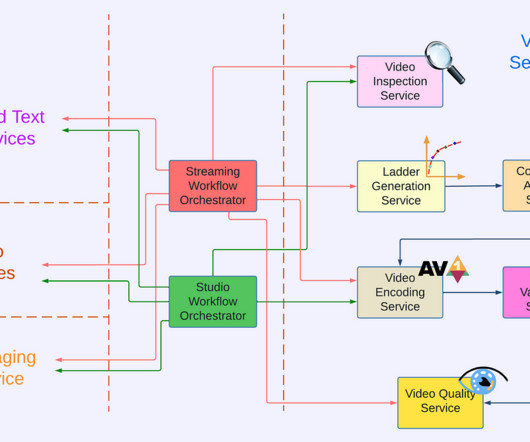
The Netflix video processing pipeline went live with the launch of our streaming service in 2007. By integrating with studio content systems, we enabled the pipeline to leverage rich metadata from the creative side and create more engaging member experiences like interactive storytelling.
Here is the agenda, 1) Data Application Lifecycle Management - Harish Kumar( Paypal) Hear from the team in PayPal on how they build the data product lifecycle management (DPLM) systems. 4) BuildingData Products and why should you? Part 1: Why did we need to build our own SIEM?
Take Astro (the fully managed Airflow solution) for a test drive today and unlock a suite of features designed to simplify, optimize, and scale your datapipelines. Try For Free → Conference Alert: Data Engineering for AI/ML This is a virtual conference at the intersection of Data and AI.
Your IT organization may have a permanent data lake, but data analytics teams need the ability to rapidly create insight from data. The DataKitchen Platform serves as a process hub that builds temporary analytic databases for daily and weekly ad hoc analytics work. Figure 3: Example process hub for biologic launch.
A data scientist is only as good as the data they have access to. Most companies store their data in variety of formats across databases and text files. This is where data engineers come in — they buildpipelines that transform that data into formats that data scientists can use.
Business users are unable to find and access data assets critical to their workflows. Data engineers spend countless hours troubleshooting broken pipelines. The data team is constantly burning out and has a high employee turnover. Stakeholders fail to see the ROI behind expensive data initiatives.
Treating data as a product is more than a concept; it’s a paradigm shift that can significantly elevate the value that business intelligence and data-centric decision-making have on the business. DatapipelinesData integrity Data lineage Data stewardship Data catalog Data product costing Let’s review each one in detail.
The limited reusability of data assets further exacerbates this agility challenge. Already operating at capacity, data teams often find themselves repeating efforts, rebuilding similar datapipelines and models for each new project. As businesses grow and evolve, their data needs expand exponentially.
In a nutshell, DataOps engineers are responsible not only for designing and buildingdatapipelines, but iterating on them via automation and collaboration as well. So, does this mean you should choose DataOps engineering vs. data engineering when considering your next career move? What does a DataOps engineer do?
Data Cascades are said to be pervasive, to lack immediate visibility, but to eventually impact the world in a negative manner. Related to the neglect of data quality, it has been observed that much of the efforts in AI have been model-centric, that is, mostly devoted to developing and improving models , given fixed data sets.
” Key Partnership Benefits: Cost Optimization and Efficiency : The collaboration is poised to reduce IT and data management costs significantly, including an up to 68% reduction in data stack spend and the ability to builddatapipelines 7.5x ABOUT ASCEND.IO Learn more at Ascend.io or follow us @ascend_io.
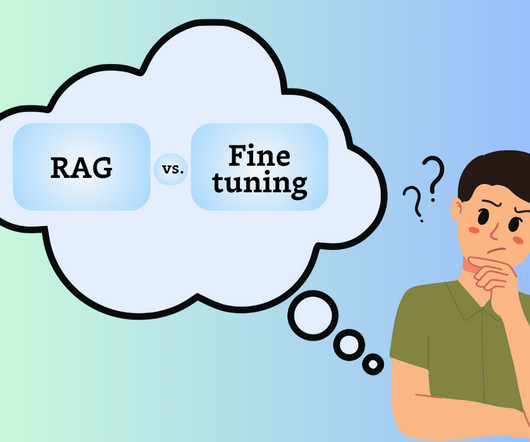
It can involve prompt engineering, vector databases like Pinecone , embedding vectors and semantic layers, data modeling, data orchestration, and datapipelines – all tailored for RAG. But when it’s done right, RAG can add an incredible amount of value to AI-powered data products. What is Fine Tuning?
ADF connects to various data sources, including on-premises systems, cloud services, and SaaS applications. It then gathers and relocates information to a centralized hub in the cloud using the Copy Activity within datapipelines. Transform and Enhance the Data: Once centralized, data undergoes transformation and enrichment.
At Snowflake, we’re helping data scientists, data engineers, and application developers build faster and more efficiently in the Data Cloud. Streamlit gives data scientists and Python developers the ability to quickly turn data and models into interactive, enterprise-ready applications.
Creating business value from the onslaught of data can feel like captaining a high-tech vessel through uncharted waters. Data teams across business areas are cranking out data sets in response to impatient business requests, while simultaneously trying to build disparate DataOps processes from scratch.
The Nuances of Snowflake Costing Snowflake’s pricing strategy is an exemplification of its user-centric approach: pay for what you use. The Predictability of Pipelines In stark contrast to ad-hoc queries, pipelines are where cost optimization efforts can yield significant dividends.
Data Engineering Weekly Is Brought to You by RudderStack RudderStack Profiles takes the SaaS guesswork, and SQL grunt work out of building complete customer profiles, so you can quickly ship actionable, enriched data to every downstream team. Now every team can build a customer360 in Snowflake with RudderStack Profiles.
This provided a nice overview of the breadth of topics that are relevant to data engineering including data warehouses/lakes, pipelines, metadata, security, compliance, quality, and working with other teams. Open question: how to seed data in a staging environment? Test system with A/A test. Be adaptable.
Factors Data Engineer Machine Learning Definition Data engineers create, maintain, and optimize data infrastructure for data. In addition, they are responsible for developing pipelines that turn raw data into formats that data consumers can use easily. Assess the needs and goals of the business.
For those aspiring to build a career within the Azure ecosystem, navigating the choices between Azure Data Engineers and Azure DevOps Engineers can be quite challenging. Azure Data Engineers and Azure DevOps Engineers are two critical components of the Azure ecosystem for different but interconnected reasons.
As datapipelines become increasingly complex, investing in a data quality solution is becoming an increasingly important priority for modern data teams. But should you build it—or buy it? And for those just getting started? For your Ubers, Airbnbs, and Netflixes of the world, this is no problem.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content