This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Understand input datasets available 3.1.2. Define what the output dataset will look like 3.1.3. Define checks to ensure the output dataset is usable 3.2. Introduction 2. Parts of data engineering 3.1. Requirements 3.1.1. Define SLAs so stakeholders know what to expect 3.1.4. Identify what tool to use to process data 3.3.
Step-by-Step Instructions for Constructing a Dataset of PubMed-Listed Publications on Cardiovascular Disease Research Continue reading on Towards Data Science »
In this blog, well explore Building an ETL Pipeline with Snowpark by simulating a scenario where commerce data flows through distinct data layersRAW, SILVER, and GOLDEN.These tables form the foundation for insightful analytics and robust business intelligence. Built clean, enriched datasets in the SILVER layer.
Building an accurate machine learning and AI model requires a high-quality dataset. Introduction In this era of Generative Al, data generation is at its peak.
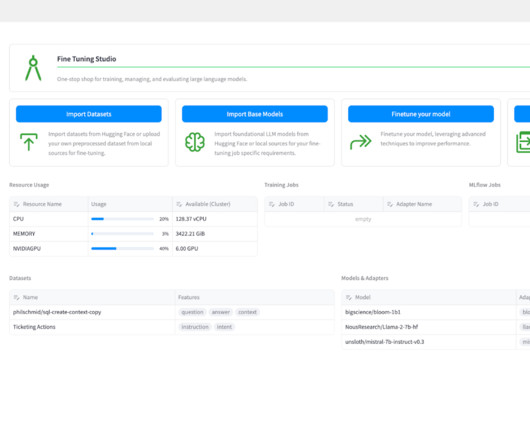
Fine Tuning Studio enables users to track the location of all datasets, models, and model adapters for training and evaluation. Build and test training and inference prompts. This means that data scientists can build and develop their own training scripts while still using Fine Tuning Studio’s compute and organizational capabilities.
This article talks about several best practices for writing ETLs for building training datasets. It delves into several software engineering techniques and patterns applied to ML.
Datasets are the repository of information that is required to solve a particular type of problem. Datasets play a crucial role and are at the heart of all Machine Learning models. Datasets are often related to a particular type of problem and machine learning models can be built to solve those problems by learning from the data.
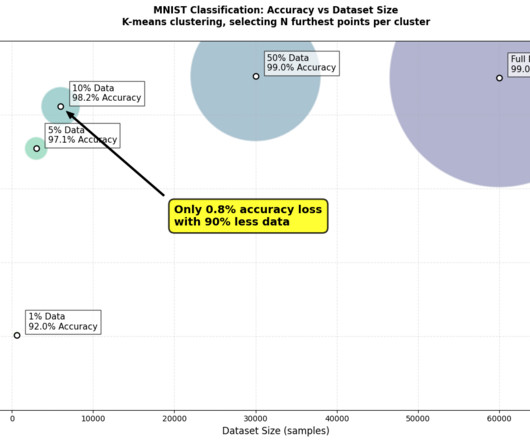
Building more efficient AI TLDR : Data-centric AI can create more efficient and accurate models. Best runs for furthest-from-centroid selection compared to full dataset. In my recent experiments with the MNIST dataset, thats exactly what happened. Images from the MNIST dataset , reproduced by theauthor. Image byauthor.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode.
Whether you are working on a personal project, learning the concepts, or working with datasets for your company, the primary focus is a data acquisition and data understanding. In this article, we will look at 31 different places to find free datasets for data science projects. What is a Data Science Dataset?
From delivering event-driven predictions to powering live recommendations and dynamic chatbot conversations, AI/ML initiatives depend on the continuous movement, transformation, and synchronization of diverse datasets across clouds, applications, and databases. Define the must-have characteristics of a data streaming architecture.
Building a self-serve data platform 3.1. Creating dataset(s) 3.1.1. Introduction Most companies want to build a self-serve data platform. Components of a self-serve platform 3. Gather requirements 3.1.2. Get data foundations right 3.2. Accessing data 3.3. Identify and remove dependencies 4. Conclusion 5. Further reading 6.
How to Build a Data Dashboard Prototype with Generative AI A book reading data visualization withVizro-AI This article is a tutorial that shows how to build a data dashboard to visualize book reading data taken from goodreads.com. Now you can use Vizro-AI to build some charts by iterating text to form effective prompts.
Building Meta’s GenAI infrastructure — 2x 24k GPU clusters and it's growing. The devil is in the details and when it comes to data pipelines there are a lot of details, which often refrain us to buy leading to build (or code). I'm speechless. This is Croissant.
Over the past four weeks, I took a break from blogging and LinkedIn to focus on building nao. A large international scientist collaboration released The Well : 2 massive datasets from physics simulation (15TB) to astronomical scientific data (100TB). They aim produce the same innovation as ImageNet produced for image recognition.
Snowflake users are already taking advantage of LLMs to build really cool apps with integrations to web-hosted LLM APIs using external functions , and using Streamlit as an interactive front end for LLM-powered apps such as AI plagiarism detection , AI assistant , and MathGPT. Join us in Vegas at our Summit to learn more.
A €150K ($165K) grant, three people, and 10 months to build it. The historical dataset is over 20M records at the time of writing! ” Like most startups, Spare Cores also made their own “expensive mistake” while building the product: “We accidentally accumulated a $3,000 bill in 1.5 Tech stack.
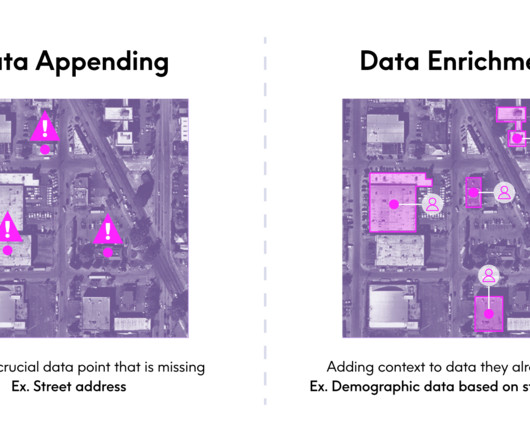
After my (admittedly lengthy) explanation of what I do as the EVP and GM of our Enrich business, she summarized it in a very succinct, but new way: “Oh, you manage the appending datasets.” Matching accuracy: Matching records between datasets is complex. ” That got me thinking.
This recipe shows how you can build a data pipeline to read data from Salesforce and write to BigQuery. Benefits Act in Real Time – Predict, automate, and react to business events as they happen, not minutes or hours later.
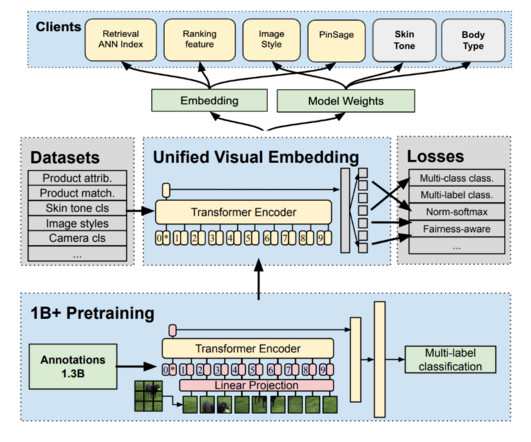
Our commitment is evidenced by our history of building products that champion inclusivity. We know from experience that building for marginalized communities helps make the product work better for everyone. In this case, thousands of fashion Pins¹ publicly available on Pinterest are gathered to serve as the raw dataset.
For further steps, you need to load your dataset to Python or switch to a platform specifically focusing on analysis and/or machine learning. You have three options to obtain data to train machine learning models: use free sound libraries or audio datasets, purchase it from data providers or collect it involving domain experts.
Images and Videos: Computer vision algorithms must analyze visual content and deal with noisy, blurry, or mislabeled datasets. They are responsible for designing, implementing, and maintaining robust, scalable data pipelines that transform raw unstructured data—text, images, videos, and more—into high-quality, AI-ready datasets.
When scaling data science and ML workloads, organizations frequently encounter challenges in building large, robust production ML pipelines. Snowflake Dataset is a new schema-level object specially designed for machine learning workflows.
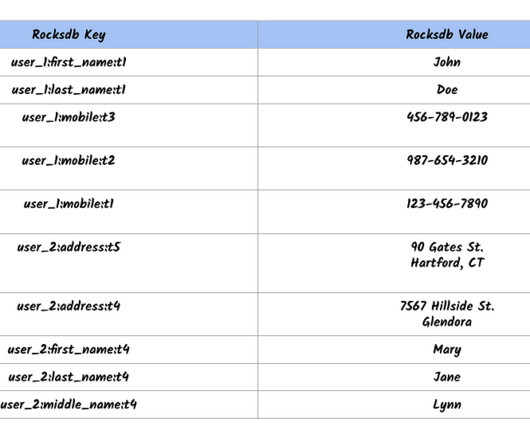
In order to build a distributed and replicated service using RocksDB, we built a real time replicator library: Rocksplicator. Maintaining these disparate systems and building common functionality among them was adding a huge overhead to the teams. Individual rows constitute a dataset. RocksDB is a single node key value store.
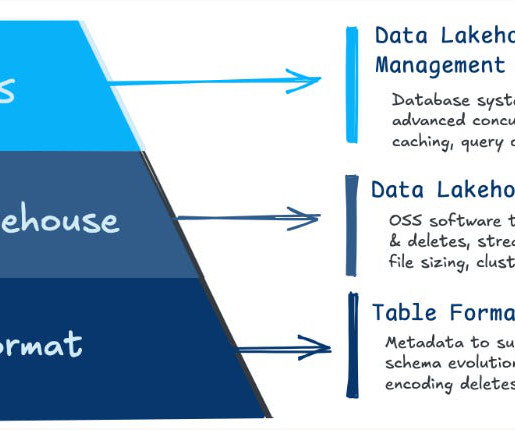
This foundational concept addresses a key challenge for enterprises: building scalable, high-performing data platforms that can support the complexity of modern data ecosystems. This hybrid approach empowers enterprises to efficiently handle massive datasets while maintaining flexibility and reducing operational overhead.
In order to build high-quality data lineage, we developed different techniques to collect data flow signals across different technology stacks: static code analysis for different languages, runtime instrumentation, and input and output data matching, etc. Lineage can also be extended to other use cases such as security and integrity.
This created an opportunity to build job sites which collect this data, make it easy to browse, and allow job seekers to apply to jobs paying at or above a certain level. He shared: “I'd preface everything by saying that this is very much a v1 of our jobs product and we plan to iterate and build a lot more as we get feedback.
The Medallion architecture is a framework that allows data engineers to build organized and analysis-ready datasets in a lakehouse environment. For instance, suppose a new dataset from an IoT device is meant to be ingested daily into the Bronze layer. How do you ensure data quality in every layer?
link] Wealthfront: Our Journey to Building a Scalable SQL Testing Library for Athena Wealthfront introduces an in-house SQL testing library tailored for AWS Athena, emphasizing principles of zero-footprint testing via CTEs, usability through Python integration and existing Avro schemas, dynamic test execution, and clear test feedback.
We have built an internal system that allows someone to perform in-video search across the entire Netflix video catalog, and we’d like to share our experience in building this system. Building in-video search To build such a visual search engine, we needed a machine learning system that can understand visual elements.
Building a large scale unsupervised model anomaly detection system — Part 1 Distributed Profiling of Model Inference Logs By Anindya Saha , Han Wang , Rajeev Prabhakar Introduction LyftLearn is Lyft’s ML Platform. The profiles are very compact and efficiently describe the dataset with high fidelity. As always, Lyft is hiring!
For image data, running distributed PyTorch on Snowflake ML also with standard settings resulted in over 10x faster processing for a 50,000-image dataset when compared to the same managed Spark solution. Many enterprises are already using Container Runtime to cost-effectively build advanced ML use cases with easy access to GPUs.
Customers can build scalable solutions while enforcing access and privacy controls. Trust and security: As customers build more data-intensive AI applications, meeting security and governance policies is increasingly challenging. text, audio) and structured (e.g.,
Analytics Engineers deliver these insights by establishing deep business and product partnerships; translating business challenges into solutions that unblock critical decisions; and designing, building, and maintaining end-to-end analytical systems. For more detail on our modeling approach and principles, check out thispost !
How Pinterest Leverages Honeycomb to Enhance CI Observability and Improve CI Build Stability Oliver Koo | Staff Software Engineer Optimizing Mobile Builds and Continuous Integration Observability at Pinterest with Honeycomb At Pinterest, our mobile infrastructure is core to delivering a high-quality experience for our users.
Now With Actionable, Automatic, Data Quality Dashboards Imagine a tool that can point at any dataset, learn from your data, screen for typical data quality issues, and then automatically generate and perform powerful tests, analyzing and scoring your data to pinpoint issues before they snowball. Announcing DataOps Data Quality TestGen 3.0:
We discovered that a flexible and incremental approach was necessary to onboard the wide variety of systems and languages used in building Metas products. Were upholding that by investing our vast engineering capabilities into building cutting-edge privacy technology. Datasets provide a native API for creating data pipelines.
Data enrichment is the process of augmenting your organizations internal data with trusted, curated third-party datasets. The Multiple Data Provider Challenge If you rely on data from multiple vendors, you’ve probably run into a major challenge: the datasets are not standardized across providers. What is data enrichment?
We will explore the challenges we encounter and unveil how we are building a resilient solution that transforms these client-side impressions into a personalized content discovery experience for every Netflixviewer. This foundational dataset is essential, as it supports various downstream workflows and enables a multitude of usecases.
dbt is the standard for creating governed, trustworthy datasets on top of your structured data. We expect that over the coming years, structured data is going to become heavily integrated into AI workflows and that dbt will play a key role in building and provisioning this data.
Building on that vision, weve continued to refine our approach. Overcoming limitations Building a machine learning system starts with translating a real-world problem into a well-defined task. The approach struggled with scalability , making it difficult to handle large datasets efficiently. Ready to see whats new?
But since 2020, Skyscanner’s data leaders have been on a journey to simplify and modernize their data stack — building trust in data and establishing an organization-wide approach to data and AI governance along the way. The data teams were maintaining 30,000 datasets, and often found anomalies or issues that had gone unnoticed for months.
But since 2020, Skyscanner’s data leaders have been on a journey to simplify and modernize their data stack — building trust in data and establishing an organization-wide approach to data and AI governance along the way. The data teams were maintaining 30,000 datasets, and often found anomalies or issues that had gone unnoticed for months.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content