This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This acquisition delivers access to trusted data so organizations can build reliable AI models and applications by combining data from anywhere in their environment. It leverages knowledge graphs to keep track of all the data sources and data flows, using AI to fill the gaps so you have the most comprehensive metadata management solution.
The data warehouse solved for performance and scale but, much like the databases that preceded it, relied on proprietary formats to build vertically integrated systems. Iceberg tables become interoperable while maintaining ACID compliance by adding a layer of metadata to the data files in a users object storage.
You can also add metadata on models (in YAML). In a nutshell the dbt journey starts with sources definition on which you will define models that will transform these sources to something else you'll need in your downstream usage of the data. You can read dbt's official definitions.
While data products may have different definitions in different organizations, in general it is seen as data entity that contains data and metadata that has been curated for a specific business purpose. A data fabric weaves together different data management tools, metadata, and automation to create a seamless architecture.
Jean-Georges Perrin was tasked with designing a new data platform implementation at PayPal and wound up building a data mesh. It's supposed to make building smarter, faster, and more flexible data infrastructures a breeze. We feel your pain. It ends up being anything but that. We do this for one simple reason: because time matters.
Part 2: Navigating Ambiguity By: VarunKhaitan With special thanks to my stunning colleagues: Mallika Rao , Esmir Mesic , HugoMarques Building on the foundation laid in Part 1 , where we explored the what behind the challenges of title launch observability at Netflix, this post shifts focus to the how.
It's supposed to make building smarter, faster, and more flexible data infrastructures a breeze. By bringing all the layers of the data stack together, TimeXtender helps you build data solutions up to 10 times faster and saves you 70-80% on costs. Can you describe what your working definition of "Data Culture" is?
In this episode Nick King discusses how you can be intentional about data creation in your applications and services to reduce the friction and errors involved in building data products and ML applications. Atlan is the metadata hub for your data ecosystem. And don’t forget to thank them for their continued support of this show!
In this episode Balaji Ganesan shares how his experiences building and maintaining Ranger in previous roles helped him understand the needs of organizations and engineers as they define and evolve their data governance policies and practices. Acryl]([link] The modern data stack needs a reimagined metadata management platform.
Today, we’ll talk about how Machine Learning (ML) can be used to build a movie recommendation system - from researching data sets & understanding user preferences all the way through training models & deploying them in applications. How to Build a Movie Recommendation System in Python?
It assesses your data, deploys production testing, monitors progress, and helps you build a constituency within your company for lasting change. Enhanced Testing & Profiling Copy & Move Tests with Ease The Test Definitions page now supports seamless test migration between test suites. DataOps just got more intelligent.
This is one way to build trust with our internal user base. Obviously not all tools are made with the same use case in mind, so we are planning to add more code samples for other (than classical batch ETL) data processing purposes, e.g. Machine Learning model building and scoring. backfill.sch.yaml ??? daily.sch.yaml ???
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode.
To help customers overcome these challenges, RudderStack and Snowflake recently launched Profiles , a new product that allows every data team to build a customer 360 directly in their Snowflake Data Cloud environment. Now teams can leverage their existing data engineering tools and workflows to build their customer 360.
It's supposed to make building smarter, faster, and more flexible data infrastructures a breeze. By bringing all the layers of the data stack together, TimeXtender helps you build data solutions up to 10 times faster and saves you 70-80% on costs. Acryl]([link] The modern data stack needs a reimagined metadata management platform.
In an effort to create a better abstraction for building data applications Nick Schrock created Dagster. In this episode he explains his motivation for creating a product for data management, how the programming model simplifies the work of building testable and maintainable pipelines, and his vision for the future of data programming.
Now after 7 years, Google has announced it will retire Firebase Dynamic Links, but with no definite successor lined up. ” Because of how useful this product is, especially for app developers building on top of it, this announcement came as a surprise. We will announce more information in Q3 2023.”
Summary A data catalog is a critical piece of infrastructure for any organization who wants to build analytics products, whether internal or external. While there are a number of platforms available for building that catalog, many of them are either difficult to deploy and integrate, or expensive to use at scale.
What if you could streamline your efforts while still building an architecture that best fits your business and technology needs? At BUILD 2024, we announced several enhancements and innovations designed to help you build and manage your data architecture on your terms. Here’s a closer look.
When scaling data science and ML workloads, organizations frequently encounter challenges in building large, robust production ML pipelines. Define an Entity: Define a Feature View: feature_df is a Snowpark DataFrame object containing your feature definition.
Building and Scaling Data Lineage at Netflix to Improve Data Infrastructure Reliability, and Efficiency By: Di Lin , Girish Lingappa , Jitender Aswani Imagine yourself in the role of a data-inspired decision maker staring at a metric on a dashboard about to make a critical business decision but pausing to ask a question?—?“Can push or pull.
The original SKU catalog is a logic-heavy client library packaged with complex metadata configuration files and consumed by various services. Operational Efficiency: The majority of the changes require metadata configuration files and library code changes, usually taking days of testing and service release to adopt the updates.
How do we build data products ? This is really for us the definition of a self serve platform. ” Code : all the code necessary to build a data product (data pipelines, API, policies). As you can see, this is in the code part where you are building your data pipelines, a misnomer because this is an over simplification.
Current design Finally, we considered whether it would be possible to build a system that relies on amortizing the cost of expensive full table scans by batching individual users requests into a single scan. For each data logs table, we initiate a new worker task that fetches the relevant metadata describing how to correctly query the data.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. What do you see as the closest alternatives?
Jark is a key figure in the Apache Flink community, known for his work in building Flink SQL from the ground up and creating Flink CDC and Fluss. Fluss is an analytical Kafka that builds on top of Lakehouse and integrates seamlessly with Flink to reduce costs, achieve better performance, and unlock new use cases for real-time analytics.
For example, we build Nickel with Nix, and we need to make sure the version of wasm-bindgen we pull from Nixpkgs is the same as the one set in Cargo.toml. The actual Nix code to build Nickel calls to a mysterious override function, which is a bespoke mechanism of Nixpkgs to simulate this kind of overriding.
ThoughtSpot continually invests in this area, giving users the confidence to build the correct Answers needed for their analysis—and ensuring they can trust the data they are shown. How ThoughtSpot builds trust with data catalog connectors For many, the data catalog is still the primary home for metadata enrichment and governance.
We will explore the challenges we encounter and unveil how we are building a resilient solution that transforms these client-side impressions into a personalized content discovery experience for every Netflixviewer. In this multi-part blog series, we take you behind the scenes of our system that processes billions of impressions daily.
Metadata Caching. This is used to provide very low latency access to table metadata and file locations in order to avoid making expensive remote RPCs to services like the Hive Metastore (HMS) or the HDFS Name Node, which can be busy with JVM garbage collection or handling requests for other high latency batch workloads.
In this blog, we’ll highlight the key CDP aspects that provide data governance and lineage and show how they can be extended to incorporate metadata for non-CDP systems from across the enterprise. Atlas provides open metadata management and governance capabilities to build a catalog of all assets, and also classify and govern these assets.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode.
Unlike data scientists — and inspired by our more mature parent, software engineering — data engineers build tools, infrastructure, frameworks, and services. It also becomes the role of the data engineering team to be a “center of excellence” through the definitions of standards, best practices and certification processes for data objects.
Every company out there has his own definition for the data engineer role. The idea behind is to solve data problem by building software. What is data engineering As I said it before data engineering is still a young discipline with many different definitions. Who are the data engineers? Is it really modern?
It houses metadata and both the desired and current state for each resource. So, if any other component needs to access information about the metadata or state of resources stored in the etcd, they have to go through the kube-apiserver. This ensures that all of the configurations are set correctly before being stored in the etcd.
If it seems like literally everyone and their CEO wants to build GenAI products, youre absolutely right. Building AI applications on top of this kind of data is like trying to have a conversation with your neighbors parrotit can spit out a few words, but they probably wont be appropriate. AI isnt going anywhere.
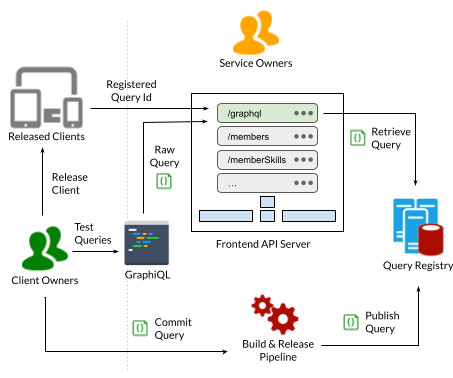
In this blog post, we will cover how the GraphQL layer is architected for use by our internal engineers to build member and customer facing applications. We had two choices in hand - invest more in Deco to address the pressing issues, or adopt GraphQL and build the necessary infrastructure around it for our needs. Given that our Rest.li
Apache Nifi is a powerful tool to build data movement pipelines using a visual flow designer. Ultimately these challenges force NiFi teams to spend a lot of time on managing the cluster infrastructure instead of building new data flows which slows down use case adoption. This will create a JSON file containing the flow metadata.
In order to eliminate the wasted effort of building custom integrations every time you want to combine lineage information across systems Julien Le Dem introduced the OpenLineage specification. What is the current state of the ecosystem for generating and sharing metadata between systems? What are your goals for the OpenLineage effort?
In this article, Juan Sequada gives maybe one of the best definition of Data Mesh ” It is paradigm shift towards a distributed architecture that attempts to find an ideal balance between centralization and decentralization of metadata and data management.”
This is a highly detailed and technical exploration of how a well-engineered metadata layer can improve the speed, accuracy, and utility of large scale, multi-tenant, cloud-native data platforms. How do you handle files on disk that don’t contain all of the fields specified in a table definition?
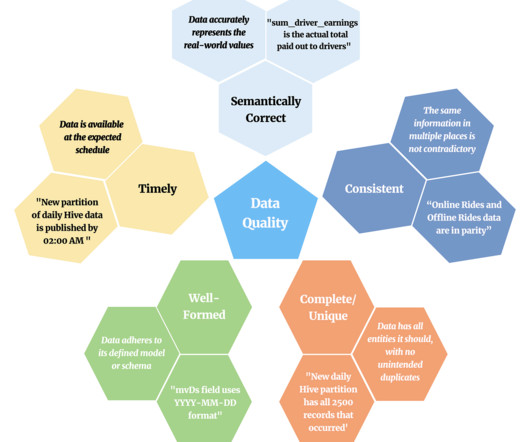
Data quality is an amorphous term, with various definitions depending on the context. In Verity, we defined data quality as follows: Verity’s Definition of Data Quality The measure of how well data can be used as intended. Five aspects of data quality with the definition in italics and an example in quotes.
Fine-grained personal access token that allows Read access to metadata and Read and Write access to code and commit statuses. Applying analytics-as-code principles, we initially developed a scriptable approach with TML to automate the lifecycle management of analytic content across environments. vcs/git/config/create REST API v2.0
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content