This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
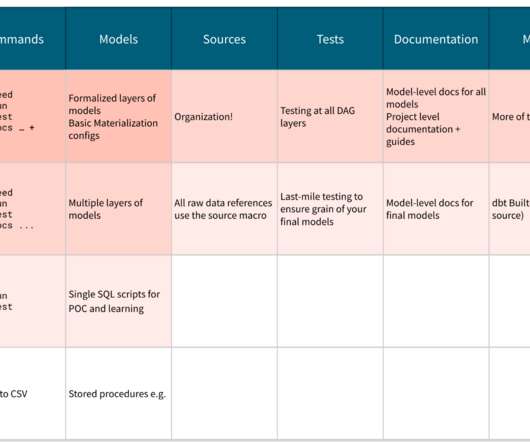
In the ELT, the load is done before the transform part without any alteration of the data leaving the rawdata ready to be transformed in the data warehouse. In a simple words dbt sits on top of your rawdata to organise all your SQL queries that are defining your data assets.
And then a wide variety of business intelligence (BI) tools popped up to provide last mile visibility with much easier end user access to insights housed in these DWs and data marts. But those end users werent always clear on which data they should use for which reports, as the datadefinitions were often unclear or conflicting.
However, copying and storing data from the warehouse in these other systems presented material computational and storage costs that were not offset by the overall effectiveness of the cache, making this infeasible as well. We do this by passing the rawdata through various renderers, discussed in more detail in the next section.
Data modeling techniques on a normalization vs denormalization scale While the relevancy of dimensional modeling has been debated by data practitioners , it is still one of the most widely adopted data modeling technique for analytics. We can then build the OBT by running dbt run.
Commercial audio sets for machine learning are definitely more reliable in terms of data integrity than free ones. The same relates to those who buy annotated sound collections from data providers. Audio data labeling. Building an app for snore and teeth grinding detection. Commercial datasets.
Code implementations for ML pipelines: from rawdata to predictions Photo by Rodion Kutsaiev on Unsplash Real-life machine learning involves a series of tasks to prepare the data before the magic predictions take place.
If a model do not respect a contract it will not build. In dbt vocabulary build means run + other things. Building a ChatGPT Plugin for Medium. Fast News ⚡️ Building a Flink self-serve platform on Kubernetes at scale — Instacart engineering team migrated from Flink on EMR to Flink on Kubernetes.
You’re maintaining two systems, so your data team needs to be agile enough to work with different technologies while keeping their datadefinitions consistent. Want to run SQL queries on your structured data while also keeping raw files for your data scientists to play with? The downside?
This was the first year that startups had the chance to build with our Native Applications Framework (currently in private preview), and we were thrilled to see the number of entries that included a native app. It transforms multiple financial and operational systems’ rawdata into a common, friendly data model that people can understand.
Table of Contents What is a Data Pipeline? The Importance of a Data Pipeline What is an ETL Data Pipeline? What is a Big Data Pipeline? Features of a Data Pipeline Data Pipeline Architecture How to Build an End-to-End Data Pipeline from Scratch?
Welcome to Snowflake’s Startup Spotlight, where we ask startup founders about the problems they’re solving, the apps they’re building and the lessons they’ve learned during their startup journey. One last question: What advice would you give to other entrepreneurs thinking about building apps on Snowflake?
Traditionally, data lakes have been an ideal choice for teams with data scientists who need to perform advanced ML operations on large amounts of unstructured data — usually, those with in-house data engineers to support their customized platform.
Summary The most complicated part of data engineering is the effort involved in making the rawdata fit into the narrative of the business. Data Engineering Podcast listeners can sign up for a free 2-week sandbox account, go to dataengineeringpodcast.com/tonic today to give it a try!
But let’s be honest, creating effective, robust, and reliable data pipelines, the ones that feed your company’s reporting and analytics, is no walk in the park. From building the connectors to ensuring that data lands smoothly in your reporting warehouse, each step requires a nuanced understanding and strategic approach.
In an evolving data landscape, the explosion of new tooling solutions—from cloud-based transforms to data observability —has made the question of “build versus buy” increasingly important for data leaders. Check out Part 1 of the build vs buy guide to catch up. Missed Nishith’s 5 considerations?
Data testing is the first step in many data engineers’ journey toward reliable data. dbt (databuild tool) is a SQL-based command-line tool that offers native testing features. Your test passes when there are no rows returned, which indicates your data meets your defined conditions.
We’ve also included some sample rawdata to add to your warehouse so you can run these projects yourself! It's more important to think about how features build upon themselves (and each other) rather than how quickly they do so.* You can use this repository to benchmark the maturity of your own dbt project.
A data-informed product strategy Product teams are tasked with being data-informed at all stages in the product life cycle, from idea generation and product definition, to validating prototypes and building a commercially successful product. But so often data is not a first-class citizen in product launches.
Today, we have a data team of about 20 professionals organized among three teams. The first team is responsible for building the backend data infrastructure. The second team, data services , are more application or front-end oriented. Also, Snowflake scalability and features like data sharing were very attractive.
Businesses benefit at large with these data collection and analysis as they allow organizations to make predictions and give insights about products so that they can make informed decisions, backed by inferences from existing data, which, in turn, helps in huge profit returns to such businesses. What is the role of a Data Engineer?
But this data is not that easy to manage since a lot of the data that we produce today is unstructured. In fact, 95% of organizations acknowledge the need to manage unstructured rawdata since it is challenging and expensive to manage and analyze, which makes it a major concern for most businesses. Why Use AWS Glue?
A DataOps Engineer owns the assembly line that’s used to build a data and analytic product. While car companies lowered costs using mass production, companies in 2021 put data engineers and data scientists on the assembly line. Imagine if a car company asked the engineers who designed cars to also build them.
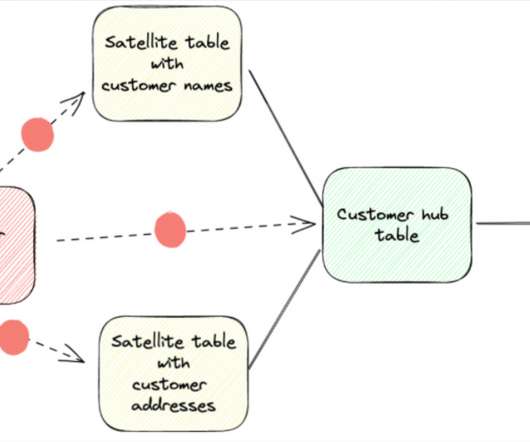
For those unfamiliar, data vault is a data warehouse modeling methodology created by Dan Linstedt (you may be familiar with Kimball or Imon models ) created in 2000 and updated in 2013. Data vault collects and organizes rawdata as underlying structure to act as the source to feed Kimball or Inmon dimensional models.
A data engineer is an engineer who creates solutions from rawdata. A data engineer develops, constructs, tests, and maintains data architectures. Let’s review some of the big picture concepts as well finer details about being a data engineer. You’ll learn how to load, query, and process your data.
As we proceed further into the blog, you will find some statistics on data engineering vs. data science jobs and data engineering vs. data science salary, along with an in-depth comparison between the two roles- data engineer vs. data scientist. vs. What does a Data Engineer do? What is Data Science?
This includes various day-to-day activities, from reducing development time and improving data quality to providing guidance and support to data team members. This involves continually striving to reduce wasted effort, identify gaps and correct them, and improve data development and deployment processes. The best part?
So let’s say that you have a business question, you have the rawdata in your data warehouse , and you’ve got dbt up and running. If your analyst is not trained as an analytics engineer, this is the point that they will need to hand the project over to a data engineer to build the model. Or are you?
Front-end development, or client-side development, involves building the User Interface (UI) of a website or a web application, that determines how every part of a website will look and how it will work. However, you might need to build dynamic web pages that can change the layout on the fly. Build Your Portfolio Congratulations!
Monte Carlo’s Barr Moses sat down with Snowflake Director of Product Management Chris Child to talk about buildingdata platforms at scale, how awesome data teams approach data quality, the role of data observability tools in the modern data stack, and more. Just get the rawdata in there.
For some companies that do have a formal strategy, that strategy may be little more than a technical exercise, the primary purpose of which is to lay out the nuts and bolts of data management, compliance, and similar baseline requirements. Data governance plays a critical role in any effective data strategy.
Odds are that your local hospital, pharmacy or medical institution's definition of being data-driven is keeping files in labelled file cabinets, as opposed to one single drawer. A simple example of a data pipeline, transforming rawdata, and converting it into a dashboard. Correctly scheduling the data pipelines.
The path to cloud efficiency begins with a cost data foundation by Anna Matlin and Tamar Eterman Introduction Business profitability and sustainability are powerful reasons to invest in infrastructure efficiency, but it is easy to feel lost about how to actually reduce costs. Most teams at Airbnb rely on the data warehouse (i.e.,
Your host is Tobias Macey and today I’m interviewing Danielle Robinson and Joe Hand about Dat Project, a distributed data sharing protocol for building applications of the future Interview Introduction How did you get involved in the area of data management? What is the Dat project and how did it get started?
Building a Shadow IT organization with separate, disconnected data repositories that only serve your line of business’ needs and introduce compliance and security risk for your company, lose your organization’s focus and participation in core business, and see your company ending up paying much more in the end? Must you be: .
Why we originally built features with SQL Feature engineering and construction isn’t much different than other modern data pipeline architectures. You start with rawdata from a source, combine it with other data, and then transform it into the desired state for your machine learning model to consume.
Business Intelligence and Artificial Intelligence are popular technologies that help organizations turn rawdata into actionable insights. While both BI and AI provide data-driven insights, they differ in how they help businesses gain a competitive edge in the data-driven marketplace.
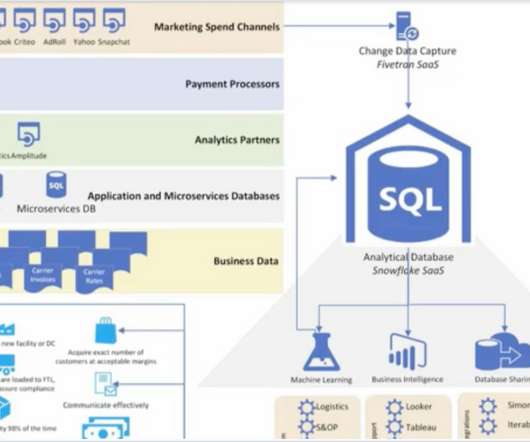
If we take the more traditional approach to data-related jobs used by larger companies, there are different specialists doing narrowly-focused tasks on different sides of the project. Data engineers builddata pipelines and perform ETL — extract data from sources, transform it, and load it into a centralized repository like a data warehouse.
Companies need more than definitions. In a world where technology evolves, and data assets have exploded in volume, it helps to know the best use cases for each of these solutions and when to avoid them. What factors are most important when building a data management ecosystem?
If digital transformation initiatives are to deliver on their promises, they need accurate, consistent, contextualized, and rich data. What Is Data Integrity? Until recently, the business community has lacked a clear and consistent definition of data integrity.
Companies need more than definitions. In a world where technology evolves, and data assets have exploded in volume, it helps to know the best use cases for each of these solutions and when to avoid them. What factors are most important when building a data management ecosystem?
Companies need more than definitions. In a world where technology evolves, and data assets have exploded in volume, it helps to know the best use cases for each of these solutions and when to avoid them. What factors are most important when building a data management ecosystem?
This article suggests the top eight data engineer books ranging from beginner-friendly manuals to in-depth technical references. What is Data Engineering? It refers to a series of operations to convert rawdata into a format suitable for analysis, reporting, and machine learning which you can learn from data engineer books.
Transform RawData into AI-generated Actions and Insights in Seconds In today’s fast-paced business environment, the ability to quickly transform rawdata into actionable insights is crucial. POS transactions training data span 79 days starting from (2024-02-01 to 2024-04-20).
SiliconANGLE theCUBE: Analyst Predictions 2023 - The Future of Data Management By far one of the best analyses of trends in Data Management. However, the medallion architecture brings a clear bucketing of data to align with the organization's delivery strategy from rawdata → filer & clean data, → business metrics.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content