This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Buck2 is a from-scratch rewrite of Buck , a polyglot, monorepo buildsystem that was developed and used at Meta (Facebook), and shares a few similarities with Bazel. As you may know, the Scalable Builds Group at Tweag has a strong interest in such scalable buildsystems. Bazel recording steps: 1.
Were explaining the end-to-end systems the Facebook app leverages to deliver relevant content to people. At Facebooks scale, the systems built to support and overcome these challenges require extensive trade-off analyses, focused optimizations, and architecture built to allow our engineers to push for the same user and business outcomes.
Not only could this recommendation system save time browsing through lists of movies, it can also give more personalized results so users don’t feel overwhelmed by too many options. What are Movie Recommendation Systems? Recommender systems have two main categories: content-based & collaborative filtering.
Unified Logging System: We implemented comprehensive engagement tracking that helps us understand how users interact with gift content differently from standardPins. Personalization Stack Building a Gift-Optimized Recommendation System The success of Holiday Finds hinges on our ability to surface the right gift ideas at the right time.
Jean-Georges Perrin was tasked with designing a new data platform implementation at PayPal and wound up building a data mesh. It's supposed to make building smarter, faster, and more flexible data infrastructures a breeze. What are the technical systems that you are relying on to power the different data domains?
Senior Engineers are not only expected to lead significant projects in their teams, but they have a say in whether that feature is worth building or not. They strive to build things fast, but also know when we have to slow down to go faster.” Address systemic issues. Reduce support costs by addressing systemic issues.
Were sharing details about Glean , Metas open source system for collecting, deriving and working with facts about source code. In this blog post well talk about why a system like Glean is important, explain the rationale for Gleans design, and run through some of the ways were using Glean to supercharge our developer tooling at Meta.
The simple idea was, hey how can we get more value from the transactional data in our operational systems spanning finance, sales, customer relationship management, and other siloed functions. But those end users werent always clear on which data they should use for which reports, as the data definitions were often unclear or conflicting.
Summary Data engineering systems are complex and interconnected with myriad and often opaque chains of dependencies. Prefect is the modern Dataflow Automation platform for the modern data stack, empowering data practitioners to build, run and monitor robust pipelines at scale. Can you describe what Schemata is and the story behind it?
The DevOps lifecycle phases are in order from left to right, with each phase building upon the last. It is about automating the process of building, testing, deploying, and maintaining applications to reduce time-to-market for new features and functionality. Operate - This version is now convenient for users to utilize.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Dagster offers a new approach to building and running data platforms and data pipelines. To start, can you share your definition of what constitutes a "Data Lakehouse"? Your first 30 days are free!
Part 2: Navigating Ambiguity By: VarunKhaitan With special thanks to my stunning colleagues: Mallika Rao , Esmir Mesic , HugoMarques Building on the foundation laid in Part 1 , where we explored the what behind the challenges of title launch observability at Netflix, this post shifts focus to the how.
In this episode Nick King discusses how you can be intentional about data creation in your applications and services to reduce the friction and errors involved in building data products and ML applications. Can you share your definition of "behavioral data" and how it is differentiated from other sources/types of data?
The data warehouse solved for performance and scale but, much like the databases that preceded it, relied on proprietary formats to build vertically integrated systems. Tune into our webinar Data Engineering Connect: Building Pipelines for Open Lakehouse on April 29, featuring two virtual demos and a hands-on lab.
When it comes to managing data, a database management system (DBMS) is a vital tool. Database management systems (DBMS) use entities to represent and manage data. In a database management system (DBMS), an entity is a piece of data tracked and stored by the system. But what is an entity? What is Entity Set in DBMS?
He’s solved interesting engineering challenges along the way, too – like building observability for Amazon’s EC2 offering, and being one of the first engineers on Uber’s observability platform. I wrote code for drivers on Windows, and started to put a basic observability system in place.
In this episode Balaji Ganesan shares how his experiences building and maintaining Ranger in previous roles helped him understand the needs of organizations and engineers as they define and evolve their data governance policies and practices. How have the design and goals of the system changed or evolved since you started working on it?
This acquisition delivers access to trusted data so organizations can build reliable AI models and applications by combining data from anywhere in their environment. Additionally, multiple copies of the same data locked in proprietary systems contribute to version control issues, redundancies, staleness, and management headaches.
Applying systems thinking views a system as a set of interconnected and interdependent components defined by its limits and more than the sum of their parts (subsystems). When one component of a system is altered, the effects frequently spread across the entire system. are the main objectives of systems thinking.
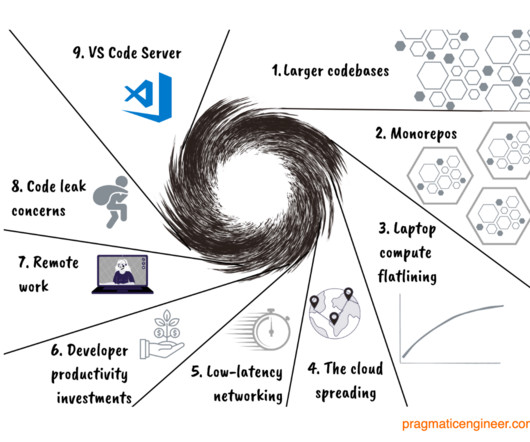
This means more repositories are needed, which are fast enough to build and work with, but which increase fragmentation. Executing a build is much slower while on a call. Plus, a CPU and memory-intensive build can impact the quality of the video call, and make the local environment much less responsive. Larger codebases.
I still remember being in a meeting where a Very Respected Engineer was explaining how they are building a project, and they said something along the lines of "and, of course, idempotency is non-negotiable." I was sceptical that any system would automatically reject resumes, because I never saw this as a hiring manager.
In this episode Lior Gavish, Lior Solomon, and Atul Gupte share their view of what it means to have a data platform, discuss their experiences building them at various companies, and provide advice on how to treat them like a software product. The data you’re looking for is already in your data warehouse and BI tools.
The answer lies in unstructured data processing—a field that powers modern artificial intelligence (AI) systems. To address these challenges, AI Data Engineers have emerged as key players, designing scalable data workflows that fuel the next generation of AI systems. How does a self-driving car understand a chaotic street scene?
He also discusses the technical implementation that allows for such extreme performance and how the data model contributes to the scalability of the system. If you need to deal with massive data, at high velocities, in milliseconds, then Aerospike is definitely worth learning about.
And this renewed focus on data quality is bringing much needed visibility into the health of technical systems. In addition, Snow f lake Cortex enables organizations to quickly analyze data and build AI applications directly within Snowflake. GenAI will definitely make us more productive. The opportunities are just boundless.”
To help customers overcome these challenges, RudderStack and Snowflake recently launched Profiles , a new product that allows every data team to build a customer 360 directly in their Snowflake Data Cloud environment. Now teams can leverage their existing data engineering tools and workflows to build their customer 360.
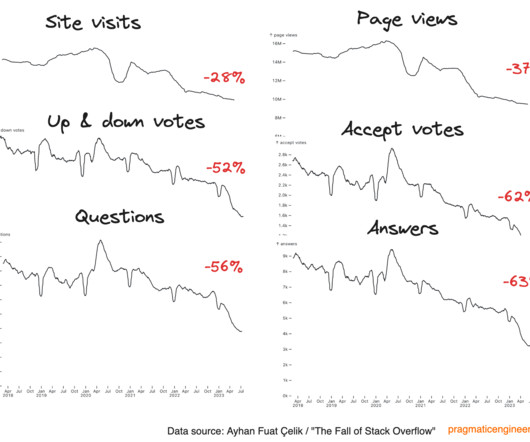
Ayhan visualized this data and observed a definite fall in all metrics: page views, visits, questions asked, votes. Q&A activity is definitely down: the company is aware of this metric taking a dive, and said they’re actively working to address it. Booking.com says a systems migration is the reason for the delay.
It requires a state-of-the-art system that can track and process these impressions while maintaining a detailed history of each profiles exposure. In this multi-part blog series, we take you behind the scenes of our system that processes billions of impressions daily. Impressions onhomepage Why do we need impression history?
Here we explore initial system designs we considered, an overview of the current architecture, and some important principles Meta takes into account in making data accessible and easy to understand. We also considered caching data logs in an online system capable of supporting a range of indexed per-user queries. What are data logs?
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Dagster offers a new approach to building and running data platforms and data pipelines. What are the skills and systems that need to be in place to effectively execute on an AI program? "AI" Your first 30 days are free!
What if you could streamline your efforts while still building an architecture that best fits your business and technology needs? At BUILD 2024, we announced several enhancements and innovations designed to help you build and manage your data architecture on your terms. Here’s a closer look.
With data volumes skyrocketing, and complexities increasing in variety and platforms, traditional centralized data management systems often struggle to keep up. As data management grows increasingly complex, you need modern solutions that allow you to integrate and access your data seamlessly.
For example, ticketing, merchandise, fantasy engagement and game viewership data often reside in separate systems (or with separate entities), making it a challenge to bring together a cohesive view of each fan. Spaulding Ridge: Turning fan 360 from vision to reality Building a fan 360 requires a comprehensive approach.
Summary One of the perennial challenges of data analytics is having a consistent set of definitions, along with a flexible and performant API endpoint for querying them. a framework for building analytics APIs to power your applications and BI dashboards Interview Introduction How did you get involved in the area of data management?
The approach finds application in security systems for user authentication. Systems like Audio Analytic ‘listen’ to the events inside and outside your car, enabling the vehicle to make adjustments in order to increase a driver’s safety. Building an app for snore and teeth grinding detection. Music recognition.
Building a maintainable and modular LLM application stack with Hamilton in 13 minutes LLM Applications are dataflows, use a tool specifically designed to express them LLM stacks. Hamilton is great for describing any type of dataflow , which is exactly what you’re doing when building an LLM powered application. Image from pixabay.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Dagster offers a new approach to building and running data platforms and data pipelines. Go to dataengineeringpodcast.com/dagster today to get started. Your first 30 days are free! Data lakes are notoriously complex.
Jark is a key figure in the Apache Flink community, known for his work in building Flink SQL from the ground up and creating Flink CDC and Fluss. Fluss is an analytical Kafka that builds on top of Lakehouse and integrates seamlessly with Flink to reduce costs, achieve better performance, and unlock new use cases for real-time analytics.
In this episode Razi Raziuddin shares how data engineering teams can support the machine learning workflow through the development and support of systems that empower data scientists and ML engineers to build and maintain their own features. What is the overall lifecycle of a feature, from definition to deployment and maintenance?
As a design system evolves alongside with the brand it represents, there are often multiple occasions when a need to introduce variations arises. The previous article on this blog gives a wider overview of the Zalando Design System. The previous article on this blog gives a wider overview of the Zalando Design System.
Apache Nifi is a powerful tool to build data movement pipelines using a visual flow designer. Ultimately these challenges force NiFi teams to spend a lot of time on managing the cluster infrastructure instead of building new data flows which slows down use case adoption. The need for a cloud-native Apache NiFi service. and later).
Thanks to the Netflix internal lineage system (built by Girish Lingappa ) Dataflow migration can then help you identify downstream usage of the table in question. This is one way to build trust with our internal user base. The main workflow definition file holds the logic of a single run, in this case one day-worth of data.
By focusing on these attributes, data engineers can build pipelines that not only meet current demands but are also prepared for future challenges. Each section will provide actionable insights and practical tips to help you build pipelines that are robust, efficient, and ready for whatever the future holds.
We reviewed the architecture of our global search at DoorDash in early 2022 and concluded that our rapid growth meant within three years we wouldn’t be able to scale the system efficiently, particularly as global search shifted from store-only to a hybrid item-and-store search experience. latency reduction and a 75% hardware cost decrease.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content