This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Here’s how to build your own parser. In this article, we’re going to build something that can handle this mess. It will be used to extract the text from PDF files LangChain: A framework to build context-aware applications with language models (we’ll use it to process and chain document tasks).
The below article was originally published in The Pragmatic Engineer , on 29 February 2024. I am re-publishing it 6 months later as a free-to-read article. This is because the below case is a good example on hype versus reality with GenAI. To get timely analysis like this in your inbox, subscribe to The Pragmatic Engineer. I signed up to try it out.
As the core building blocks of any effective data strategy, these transformations are crucial for constructing robust and scalable data pipelines. Today, we're excited to announce the latest product advancements in Snowflake to build and orchestrate data pipelines.
Snowflake Features that Make Data Science Easier Building Data Applications with Snowflake Data Warehouse Snowflake Data Warehouse Architecture How Does Snowflake Store Data Internally? It also offers a unique architecture that allows users to quickly build tables and begin querying data without administrative or DBA involvement.
One of the primary motivations for individuals searching for "crew ai projects" is to find practical examples and templates that can serve as starting points for building their own AI applications. These components form the foundation for building robust and powerful AI agents.
To further meet the needs of early-stage startups, Snowflake is expanding the Startup Accelerator to now include up to a $200 million investment in startups building industry-specific solutions and growing their businesses on the Snowflake AI Data Cloud.
Getting Started with NLTK NLP with NLTK in Python NLTK Tutorial-1: Text Classification using NLTK NLTK Tutorial-2: Text Similarity and Clustering using NLTK NLTK Tutorial-3: Working with Word Embeddings in NLTK Top 3 NLTK NLP Project Ideas for Practice Build Custom NLP Models using NLTK with ProjectPro! Let's look at an example below.
Using Airflow for Building and Monitoring the Data Pipeline of Amazon Redshift 4. Top10 AWS Redshift Project Ideas and Examples for Practice This article will list the top 10 AWS project ideas for beginners, intermediates, and experts who want to master the art of building data pipelines using AWS Redshift. Image credit: dev.to/aws-builders/build-a-data-warehouse-quickly-with-amazon-redshift-2op8
Follow this free guide for tips on making the build to buy transition. If you built your analytics in house, chances are your basic features are no longer enough for your end users. Is it time to move on to a more robust analytics solution with more advanced capabilities?
Efficient Scheduling and Runtime Increased Adaptability and Scope Faster Analysis and Real-Time Prediction Introduction to the Machine Learning Pipeline Architecture How to Build an End-to-End a Machine Learning Pipeline? This makes it easier for machine learning pipelines to fit into any model-building application.
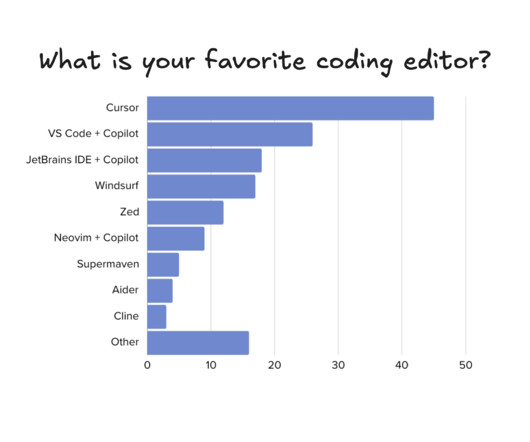
It’s been nearly 6 months since our research into which AI tools software engineers use, in the mini-series, AI tooling for software engineers: reality check. At the time, the most popular tools were ChatGPT for LLMs, and GitHub copilot for IDE-integrated tooling. model was released, which has superior code generation compared to ChatGPT.
Then, we’ll begin a hands-on journey to build a Knowledge Graph. All thanks to Graph-theory-based-Knowledge-Graphs, AI systems can gauge beyond isolated facts, weaving together a web of meaning that imitates human understanding. If you are ready to explore the wonder of Knowledge Graphs in AI, continue reading.
Project Idea: To build a customer support chatbot in Python , you can leverage LangChain and LangGraph. Source Code: How to Build an LLM-Powered Data Analysis Agent? Source Code: How to Build a Custom AI Agent? Start by setting up the necessary libraries (openai, LangChain, and LangGraph).
Every time an application team gets caught up in the “build vs buy” debate, it stalls projects and delays time to revenue. Partnering with an analytics development platform gives you the freedom to customize a solution without the risks and long-term costs of building your own. There is a third option.
This blog is your complete guide to building Generative AI applications in Python. The real question is: how do you build your own GenAI applications and tap into this power? Look no further—this guide will walk you through everything you need to build your own GenAI model. Let’s get started!
An eye-catching detail widely reported by media and on social media about the bankrupt business Builder.ai last week, was that the company faked AI with 700 engineers in India: “Microsoft-backed AI startup chatbots revealed to be human employees” – Mashable “Builder.ai Also, it’s the year 2024 in this experiment.
We will bridge that gap through this comprehensive guide to building an LLM from scratch—covering everything from data preparation to model tuning. So, come along on this journey to explore the building blocks of LLMs, gain practical insights, and start training an LLM from scratch that suits your goals.
We know you are enthusiastic about building data pipelines from scratch using Airflow. For example, if we want to build a small traffic dashboard that tells us what sections of the highway suffer traffic congestion. Apache Airflow is a batch-oriented tool for building data pipelines. Is Airflow an ETL Tool?
Organizational data literacy is regularly addressed, but it’s uncommon for product managers to consider users’ data literacy levels when building products. Product managers need to research and recognize their end users' data literacy when building an application with analytic features.
Last year, the promise of data intelligence – building AI that can reason over your data – arrived with Mosaic AI, a comprehensive platform for building, evaluating, monitoring, and securing AI systems. Building nuanced evaluations often required expensive manual labeling.
Register now Home Insights Artificial Intelligence Article Build a Data Mesh Architecture Using Teradata VantageCloud on AWS Explore how to build a data mesh architecture using Teradata VantageCloud Lake as the core data platform on AWS. The data mesh architecture Key components of the data mesh architecture 1.
(In reference to Big Data) Developers of Google had taken this quote seriously, when they first published their research paper on GFS (Google File System) in 2003. Little did anyone know, that this research paper would change, how we perceive and process data. Same is the story, of the elephant in the big data room- “Hadoop” Surprised?
In building machine learning projects , the basics involve preparing datasets. Data preparation for machine learning algorithms is usually the first step in any data science project. It involves various steps like data collection, data quality check, data exploration, data merging, etc. Refer to the video below to know what it looks like.
Download this eBook to discover insights from 16 top product experts, and learn what it takes to build a successful application with analytics at its core. What should product managers keep in mind when adding an analytics project to their roadmap?
Check Out ProjectPro's Deep Learning Course to Gain Practical Skills in Building and Training Neural Networks! One of the most powerful and widely-used RNN architectures is the Long Short-Term Memory (LSTM) neural network model. Table of Contents What is LSTM(Long Short-Term Memory) Model? Operations inside the light red circle are pointwise.
How to Build an ARIMA Model in Python for Forecasting? Table of Contents ARIMA Model- Complete Guide to Time Series Forecasting in Python ARIMA Model Equation/Formula Why does ARIMA need Stationary Time-Series Data? When to Use the ARIMA Model? How to Justify the Use of the ARIMA Model? How to Fit ARIMA in Python?
Hallucination is a common issue that most data scientists face with their large language models, especially those with high complexity. It can occur due to various other factors, such as overfitting and training data bias/inaccuracy, which results in the Large Language Models (LLMs) repeating random facts and outputs.
Over the past four weeks, I took a break from blogging and LinkedIn to focus on building nao. DeepSeek is a model trained by the Chinese company with the same name, they directly compete with OpenAI and all to build foundational models. We announced the AI Product Day , a 1-day conference that will take place in Paris on March 31.
The Definitive Guide to Predictive Analytics has everything you need to get started, including real-world examples, steps to build your models, and solutions to common data challenges. What You'll Learn: 7 steps to embed predictive analytics in your application—from identifying a problem to solve to building your prototype.
A refresher on OpenAI, and on Evan Evan: how did you join OpenAI, and end up heading the Applied engineering group – which also builds ChatGPT? I do not have a PhD in Machine Learning, and was excited by the idea of building APIs and engineering teams. "How does ChatGPT work, under the hood?" Tokenization. We
A €150K ($165K) grant, three people, and 10 months to build it. The name comes from the concept of “spare cores:” machines currently unused, which can be reclaimed at any time, that cloud providers tend to offer at a steep discount to keep server utilization high. Source: Spare Cores. Tech stack. Benchmarking tools.
Abid Ali Awan ( @1abidaliawan ) is a certified data scientist professional who loves building machine learning models. His vision is to build an AI product using a graph neural network for students struggling with mental illness. Storage: Ensure you have at least 200GB of free disk space for the model and its dependencies.
Enterprises are encouraged to experiment with AI, build numerous small-scale agents, learn from each, and expand their agent infrastructure over time. These platforms are instrumental in building the robust data infrastructure necessary to support the burgeoning field of AI agents.
We hope this guide will transform how you build value for your products with embedded analytics. The Definitive Guide to Embedded Analytics is designed to answer any and all questions you have about the topic. It will show you what embedded analytics are and how they can help your company.
The company offers a comprehensive ecosystem that automates the entire development process, including building, testing, debugging, deploying, and monitoring applications. Abid Ali Awan ( @1abidaliawan ) is a certified data scientist professional who loves building machine learning models. Visit the Claude GitHub App page: [link].
He’s solved interesting engineering challenges along the way, too – like building observability for Amazon’s EC2 offering, and being one of the first engineers on Uber’s observability platform. We covered more on this topic in the article How Uber built its observability platform.
One notable recent release is Yambda-5B , a 5-billion-event dataset contributed by Yandex, based on data from its music streaming service, now available via Hugging Face. Yambda comes in 3 sizes (50M, 500M, 5B) and includes baselines to underscore accessibility and usability. However, it lacks long-term history and explicit feedback.
The internet has been speculating the past few days on which crypto company spent $65M on Datadog in 2022. I confirmed it was Coinbase, and here are the details of what happened. Originally published on 11 May 2023. 👋 Hi, this is Gergely with a bonus, free issue of the Pragmatic Engineer Newsletter. Can you possibly shed a little more light?“
To better understand the factors behind the decision to build or buy analytics, insightsoftware partnered with Hanover Research to survey IT, software development, and analytics professionals on why they make the embedded analytics choices they do.
In one of their studies, Sacknman, Erikson, and Grant were measuring performances of a group of experienced programmers. ” Brooks agrees with this observation, and suggests a radical solution: have as few senior programmers as possible, and build a team around each one – a bit like how a hospital surgeon leads a whole team.
Phase 2: some business logic, and more infra (December-January) Draw a map using JavaScript to map onto an SVG format Build a graph and traverse it. The project looks like a tough one to build from scratch on the side. See it in action, here : A screenshot of the interactive “Rides” app. Incremental progress.
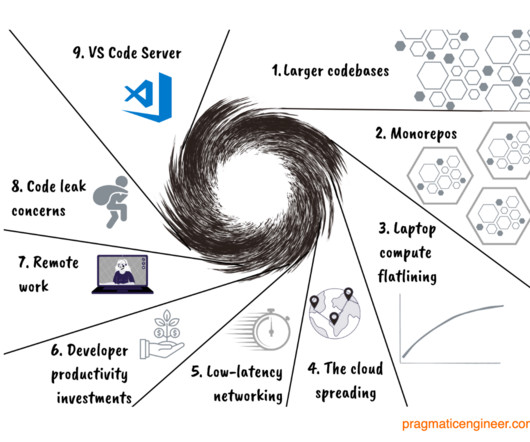
This means more repositories are needed, which are fast enough to build and work with, but which increase fragmentation. No wonder compute time was so valuable! The input/output area of the Atlas computer (right) and the computer itself, occupying a large room with its circuit boards inside closets. Larger codebases. Remote work.
A first, smaller wave of these stories included Magic.dev raising $100M in funding from Nat Friedman (CEO of GitHub from 2018-2021,) and Daniel Gross (cofounder of search engine Cue which Apple acquired in 2013,) to build a “superhuman software engineer.” Clearly, this would generate a handsome return for investors and founders.
The advantages of buying an analytics solution over building your own. Outdated or absent analytics won’t cut it in today's data-driven applications. And they won’t cut it for your end users, your development team, or your business. That's what drove the five companies in this eBook to change their approach to analytics.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content