This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This acquisition delivers access to trusted data so organizations can build reliable AI models and applications by combining data from anywhere in their environment. It leverages knowledge graphs to keep track of all the data sources and data flows, using AI to fill the gaps so you have the most comprehensive metadata management solution.
Summary Metadata is the lifeblood of your data platform, providing information about what is happening in your systems. In order to level up their value a new trend of active metadata is being implemented, allowing use cases like keeping BI reports up to date, auto-scaling your warehouses, and automated data governance.
A €150K ($165K) grant, three people, and 10 months to build it. Results are stored in git and their database, together with benchmarking metadata. Benchmarking results for each instance type are stored in sc-inspector-data repo, together with the benchmarking task hash and other metadata. There Tech stack.
The data warehouse solved for performance and scale but, much like the databases that preceded it, relied on proprietary formats to build vertically integrated systems. Iceberg tables become interoperable while maintaining ACID compliance by adding a layer of metadata to the data files in a users object storage.
Summary A significant amount of time in data engineering is dedicated to building connections and semantic meaning around pieces of information. Linked data technologies provide a means of tightly coupling metadata with raw information. Go to dataengineeringpodcast.com/materialize today to get 2 weeks free!
Enterprises are encouraged to experiment with AI, build numerous small-scale agents, learn from each, and expand their agent infrastructure over time. Moreover, we anticipate a growing emphasis on intelligent data platforms that unify data and metadata, further supported by efforts to enhance data cataloging and lineage tracking.
Over the multiple decades I’ve spent in the data industry, one observation has remained nearly constant: the majority of the work in building a data analytics platform revolves around data transformations (what we used to call “the T in ETL or ELT”). For the future, our automation tools must collect and manage metadata at the column level.
Key Takeaways: Prioritize metadata maturity as the foundation for scalable, impactful data governance. Integrate data governance and data quality practices to create a seamless user experience and build trust in your data. The panel agreed that metadata maturity is essential for scalability and driving business outcomes.
Jean-Georges Perrin was tasked with designing a new data platform implementation at PayPal and wound up building a data mesh. It's supposed to make building smarter, faster, and more flexible data infrastructures a breeze. We feel your pain. It ends up being anything but that. We do this for one simple reason: because time matters.
Summary Building data products is an undertaking that has historically required substantial investments of time and talent. In this episode he explains the design of the platform and how it builds on agile development principles to help you focus on delivering value. Atlan is the metadata hub for your data ecosystem.
These insights have shaped the design of our foundation model, enabling a transition from maintaining numerous small, specialized models to building a scalable, efficient system. Therefore, its also important to let foundation models use metadata information of entities and inputs, not just member interaction data.
We discovered that a flexible and incremental approach was necessary to onboard the wide variety of systems and languages used in building Metas products. Were upholding that by investing our vast engineering capabilities into building cutting-edge privacy technology. We believe that privacy drives product innovation.
While data products may have different definitions in different organizations, in general it is seen as data entity that contains data and metadata that has been curated for a specific business purpose. A data fabric weaves together different data management tools, metadata, and automation to create a seamless architecture.
Building Meta’s GenAI infrastructure — 2x 24k GPU clusters and it's growing. Attributing Snowflake cost to whom it belongs — Fernando gives ideas about metadata management to attribute better Snowflake cost. I'm speechless. This is Croissant.
In this episode Nick King discusses how you can be intentional about data creation in your applications and services to reduce the friction and errors involved in building data products and ML applications. Atlan is the metadata hub for your data ecosystem. And don’t forget to thank them for their continued support of this show!
It's supposed to make building smarter, faster, and more flexible data infrastructures a breeze. By bringing all the layers of the data stack together, TimeXtender helps you build data solutions up to 10 times faster and saves you 70-80% on costs. We feel your pain. It ends up being anything but that. We feel your pain.
Part 2: Navigating Ambiguity By: VarunKhaitan With special thanks to my stunning colleagues: Mallika Rao , Esmir Mesic , HugoMarques Building on the foundation laid in Part 1 , where we explored the what behind the challenges of title launch observability at Netflix, this post shifts focus to the how.
Snowflake’s support for Iceberg Tables is now in public preview, helping customers build and integrate Snowflake into their lake architecture. A benefit of the GLUE catalog integration in comparison to OBJECT_STORE is easier table refresh since GLUE doesn’t require a specific metadata file path, while OBJECT_STORE does.
In this episode Balaji Ganesan shares how his experiences building and maintaining Ranger in previous roles helped him understand the needs of organizations and engineers as they define and evolve their data governance policies and practices. Acryl]([link] The modern data stack needs a reimagined metadata management platform.
The idea is to transpose these 7 principles to data pipeline knowing that Data pipelines are 100% flexible : if you have the skills, you build the pipeline you want. We have 2 teams : one is building the pipelines and the other to maintain them. This is where you have all the main tools to improve manufacturing processes.
We expect that over the coming years, structured data is going to become heavily integrated into AI workflows and that dbt will play a key role in building and provisioning this data. We are committed to building the data control plane that enables AI to reliably access structured data from across your entire data lineage.
In the realm of modern analytics platforms, where rapid and efficient processing of large datasets is essential, swift metadata access and management are critical for optimal system performance. Any delays in metadata retrieval can negatively impact user experience, resulting in decreased productivity and satisfaction. What is Atlas?
On the flip side, there was a substantial appetite to build real-time ML systems from developers at Lyft. Shortly after we built it, it was utilized by another pod within our team to build a Real-time Anomaly Detection product. To meet the needs of our customers, we kicked off the Real-time Machine Learning with Streaming initiative.
You can also add metadata on models (in YAML). docs — in dbt you can add metadata on everything, some of the metadata is already expected by the framework and thank to it you can generate a small web page with your light catalog inside: you only need to do dbt docs generate and dbt docs serve.
Summary Five years of hosting the Data Engineering Podcast has provided Tobias Macey with a wealth of insight into the work of building and operating data systems at a variety of scales and for myriad purposes. Atlan is the metadata hub for your data ecosystem. Struggling with broken pipelines? Stale dashboards? Missing data?
In order to build high-quality data lineage, we developed different techniques to collect data flow signals across different technology stacks: static code analysis for different languages, runtime instrumentation, and input and output data matching, etc. Lineage can also be extended to other use cases such as security and integrity.
In August, we wrote about how in a future where distributed data architectures are inevitable, unifying and managing operational and business metadata is critical to successfully maximizing the value of data, analytics, and AI. It is a critical feature for delivering unified access to data in distributed, multi-engine architectures.
Did someone say Metadata? There are even folks who create dashboards from this metadata to help other engineers identify expensive copying, use of inefficient or inappropriate C++ containers, overuse of smart pointers, and much more. Looking at function call stacks with flame graphs is great, nothing against it.
This ecosystem includes: Catalogs: Services that manage metadata about Iceberg tables (e.g., Maintenance Processes: Operations that optimize Iceberg tables, such as compacting small files and managing metadata. Metadata Overhead: Iceberg relies heavily on metadata to track table changes and enable features like time travel.
How to build a modern, scalable data platform to power your analytics and data science projects (updated) Table of Contents: What’s changed? Orchestration I mentioned modularity as a core concept of building a modern data platform in my 2021 article, but I failed to emphasize the importance of data orchestration.
To help customers overcome these challenges, RudderStack and Snowflake recently launched Profiles , a new product that allows every data team to build a customer 360 directly in their Snowflake Data Cloud environment. Now teams can leverage their existing data engineering tools and workflows to build their customer 360.
The Snowpark Model Registry now builds on a native Snowflake model entity with built-in versioning support, role-based access control and a SQL API for more streamlined management catering to both SQL and Python users. What’s Next?
The vast majority of the Rust projects are using Cargo as a build tool. Cargo is great when you are developing and packaging a single Rust library or application, but when it comes to a fast-growing and complex workspace, one could be attracted to the idea of using a more flexible and scalable build system.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode.
When AI is only as trustworthy as the data it’s trained on, you must prioritize data governance, quality, and overall integrity – whether building new AI solutions or refining existing ones. According to Anandarajan, building a culture of data literacy is what will help to bridge this gap. Focus on metadata management.
functional correctness AI-as-a-judge comparative evaluation [link] OpenAI: A practical guide to building agents OpenAI publishes a comprehensive guide on building AI Agents. The author walks through three broad categories of evaluation-driven development. The guide walks through three core components of AI Agents.
Meanwhile, operations teams use entity extraction on documents to automate workflows and enable metadata-driven analytical filtering. Skai deployed a categorization tool in just two days to help its customers get better insights about purchasing patterns by building categories that make sense across multiple ecommerce platforms.
For data engineers who battle to build and scale high quality data workflows on the data lake, Starburst is an end-to-end data lakehouse platform built on Trino, the query engine Apache Iceberg was designed for, with complete support for all table formats including Apache Iceberg, Hive, and Delta Lake.
Below a diagram describing what I think schematises data platforms: Data storage — you need to store data in an efficient manner, interoperable, from the fresh to the old one, with the metadata. It adds metadata, read, write and transactions that allow you to treat a Parquet file as a table. But what is doing Tabular?
In this blog, well address this challenge by building a metadata-driven solution using a JavaScript stored procedure that dynamically maps and loads only the required columns from multiple CSV files into their respective Snowflake tables. Metadata Proc Step 4: Execute the Stored Procedure.
Our team, the Developer Infrastructure team, aims to build the best tools to enable microservice owners (our “customers”) to reliably and quickly test changes in a local and/or end-to-end environment. Routing overrides metadata: embed metadata in API request headers defining which offloaded deployment the request will get routed to.
This work illustrates our effort in successfully building Pinterest an internal embedding-based retrieval system for organic content learned purely from logged user engagement events and serves in production. The metadata is generated together with the index. We have deployed our system for homefeed as well as notification.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















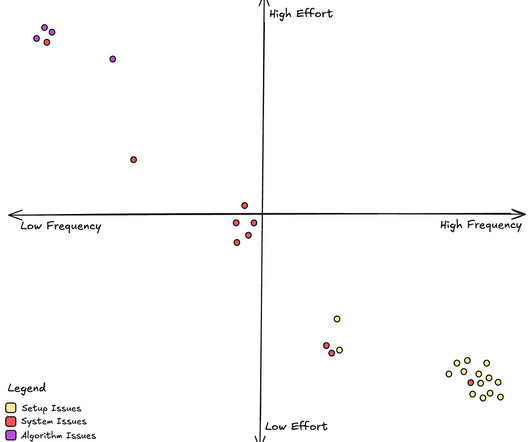

































Let's personalize your content