This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Unlocking Data Team Success: Are You Process-Centric or Data-Centric? We’ve identified two distinct types of data teams: process-centric and data-centric. We’ve identified two distinct types of data teams: process-centric and data-centric. They work in and on these pipelines.
In today’s data-driven world, developer productivity is essential for organizations to build effective and reliable products, accelerate time to value, and fuel ongoing innovation. The post Snowflake’s New Python API Empowers Data Engineers to Build Modern Data Pipelines with Ease appeared first on Snowflake.
Some departments used IBM Db2, while others relied on VSAM files or IMS databases creating complex data governance processes and costly data pipeline maintenance. By implementing data replication from the IBM Z, the team was able to build data pipelines to distributed targets, ensuring that each application use case could be supported.
In 2020, Snowflake announced a new global competition to recognize the work of early-stage startups building their apps — and their businesses — on Snowflake, offering up to $250,000 in investment as the top prize. Just as varied was the list of Snowflake tech that early-stage startups are using to drive their innovative entries.
For data engineers who battle to build and scale high quality data workflows on the data lake, Starburst is an end-to-end data lakehouse platform built on Trino, the query engine Apache Iceberg was designed for, with complete support for all table formats including Apache Iceberg, Hive, and Delta Lake.
Software projects of all sizes and complexities have a common challenge: building a scalable solution for search. Building a resilient and scalable solution is not always easy. It involves many moving parts, from data preparation to building indexing and query pipelines. You might be wondering, is this a good solution?
But for many organizations, building this understanding is more akin to solving an ever-growing jigsaw puzzle (with no easy edge pieces!) If you don’t have to duplicate data, then you don’t have to pay egress costs or send your data across the internet, which means you can build your connections and get down to business faster.
impactdatasummit.com Thumbtack: What we learned building an ML infrastructure team at Thumbtack Thumbtack shares valuable insights from building its ML infrastructure team. The blog emphasizes the importance of starting with a clear client focus to avoid over-engineering and ensure user-centric development.
With Astro, you can build, run, and observe your data pipelines in one place, ensuring your mission critical data is delivered on time. meeting recordings and videos), which contrasts with traditional SQL-centric systems for structured data. Generative AI demands the processing of vast amounts of diverse, unstructured data (e.g.,
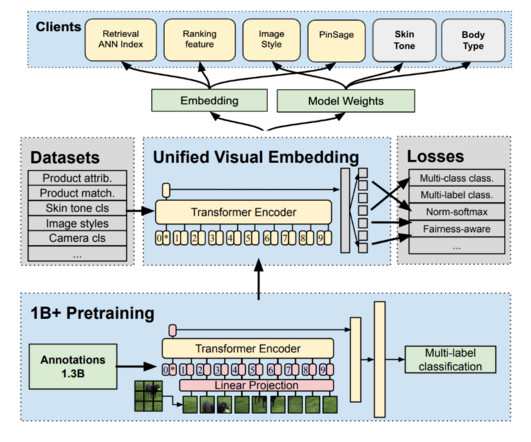
Our commitment is evidenced by our history of building products that champion inclusivity. We know from experience that building for marginalized communities helps make the product work better for everyone. To ensure an unbiased approach, we also leveraged our skin tone and hair pattern signals when building this dataset.
We have also seen a fourth layer, the Platinum layer , in companies’ proposals that extend the Data pipeline to OneLake and Microsoft Fabric. The need to copy data across layers, manage different schemas, and address data latency issues can complicate data pipelines. However, this architecture is not without its challenges.
One thing that stands out to me is As AI-driven data workflows increase in scale and become more complex, modern data stack tools such as drag-and-drop ETL solutions are too brittle, expensive, and inefficient for dealing with the higher volume and scale of pipeline and orchestration approaches.
Segment created the Unify product to reduce the burden of building a comprehensive view of customers and synchronizing it to all of the systems that need it. In this episode Kevin Niparko and Hanhan Wang share the details of how it is implemented and how you can use it to build and maintain rich customer profiles.
link] Chip Huyan: Building A Generative AI Platform We can’t deny that Gen-AI is becoming an integral part of product strategy, pushing the need for platform engineering. Adopting LLM in SQL-centric workflow is particularly interesting since companies increasingly try text-2-SQL to boost data usage. Pipeline breakpoint feature.
In the fast-paced world of software development, the efficiency of build processes plays a crucial role in maintaining productivity and code quality. At ThoughtSpot , while Gradle has been effective, the growing complexity of our projects demanded a more sophisticated approach to understanding and optimizing our builds.
How do we build data products ? You are starting to be an operation or technology centric data team. ” Code : all the code necessary to build a data product (data pipelines, API, policies). TL;DR After setting up and organizing the teams, we are describing 4 topics to make data mesh a reality.
Summary How much time do you spend maintaining your data pipeline? How does the data-centric approach of DataCoral differ from the way that other platforms think about processing information? What has been your experience, both positive and negative, in building on top of serverless components?
Learn More → AI Verify Foundation: Model AI Governance Framework for Generative AI Several countries are working on building governance rules for Gen AI. The author highlights the structured approach to building data infrastructure, data management, and metrics. TIL that the queryable state is deprecated, which surprises me too.
The first response has been frustration because of the chaos a breach like this causes: At a scaleup I talked with, infrastructure teams shut down all pipelines in order to replace secrets. Our customers are some of the most innovative, engineering-centric businesses on the planet, and helping them do great work will continue to be our focus.”
Key Themes Data-Driven Decision-Making : Learn how to build a data-centric culture that drives better outcomes. Build Valuable Connections : Network with peers, analysts, and data visionaries who can offer fresh perspectives and collaborations. Build trust across domains : Set and uphold data SLAs.
Summary Data engineers have typically left the process of data labeling to data scientists or other roles because of its nature as a manual and process heavy undertaking, focusing instead on building automation and repeatable systems. And don’t forget to thank them for their continued support of this show!
NVidia released Eagle a vision-centric multimodal LLM — Look at the example in the Github repo, given an image and a user input the LLM is able to answer things like "Describe the image in detail" or "Which car in the picture is more aerodynamic" based on a drawing. What's your question?
This means moving beyond product-centric thinking to a data-driven customer experience model that’s consistent across all channels. Next, the wealth management industry is also shifting away from a product focus to a client-centric model. Data will enable this industry to shift to scalable solutions and ensure greater customer loyalty.
For modern data engineers using Apache Spark, DE offers an all-inclusive toolset that enables data pipeline orchestration, automation, advanced monitoring, visual troubleshooting, and a comprehensive management toolset for streamlining ETL processes and making complex data actionable across your analytic teams. Job Deployment Made Simple.
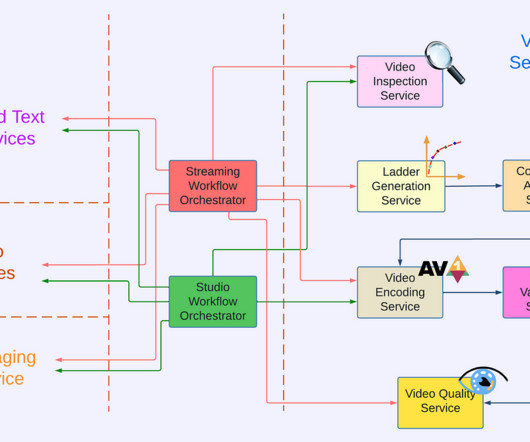
The Netflix video processing pipeline went live with the launch of our streaming service in 2007. By integrating with studio content systems, we enabled the pipeline to leverage rich metadata from the creative side and create more engaging member experiences like interactive storytelling.
DataOps is fundamentally about eliminating errors, reducing cycle time, building trust and increasing agility. The data pipelines must contend with a high level of complexity – over seventy data sources and a variety of cadences, including daily/weekly updates and builds.
Of course, this is not to imply that companies will become only software (there are still plenty of people in even the most software-centric companies), just that the full scope of the business is captured in an integrated software defined process. Our approach to building this platform is from the bottom up. Confluent’s mission.
Streamlit has rapidly become the de facto way to build UIs for LLM-powered apps. Get smarter about your data with native LLMs Additionally, Snowflake is building LLMs directly into the platform to help customers boost productivity and unlock new insights from their data. And with LLMs, it’s no different. Read this blog.
To enable LGIM to better utilize its wealth of data, LGIM required a centralized platform that made internal data discovery easy for all teams and could securely integrate external partners and third-party outsourced data pipelines. To realize this cohesive data vision, LGIM adopted Cloudera Data Platform (CDP) Public Cloud.
Cloudera has partnered with Cisco in helping build the Cisco Validated design (CVD) for Apache Ozone. Look at details of volumes/buckets/keys/containers/pipelines/datanodes. Given a file, find out what nodes/pipeline is it part of. Cloudera and Cisco have tested together with dense storage nodes to make this a reality. .
The DataKitchen Platform serves as a process hub that builds temporary analytic databases for daily and weekly ad hoc analytics work. These limited-term databases can be generated as needed from automated recipes (orchestrated pipelines and qualification tests) stored and managed within the process hub. . The DataOps Advantage .
Here is the agenda, 1) Data Application Lifecycle Management - Harish Kumar( Paypal) Hear from the team in PayPal on how they build the data product lifecycle management (DPLM) systems. 4) Building Data Products and why should you? Part 1: Why did we need to build our own SIEM?
Data Engineering is typically a software engineering role that focuses deeply on data – namely, data workflows, data pipelines, and the ETL (Extract, Transform, Load) process. Data Engineers are engineers responsible for uncovering trends in data sets and building algorithms and data pipelines to make raw data beneficial for the organization.
Already operating at capacity, data teams often find themselves repeating efforts, rebuilding similar data pipelines and models for each new project. Yet, data teams find themselves perpetually playing catch-up, struggling to meet immediate demands rather than building scalable, future-proof solutions.
Unlike data scientists — and inspired by our more mature parent, software engineering — data engineers build tools, infrastructure, frameworks, and services. Data is simply too centric to the company’s activity to have limitation around what roles can manage its flow.
Data engineers spend countless hours troubleshooting broken pipelines. Data plays a central role in modern organisations; the centricity here is not just a figure of speech, as data teams often sit between traditional IT and different business functions. Know when to build and when to buy. Data Observability.
This is where data engineers come in — they buildpipelines that transform that data into formats that data scientists can use. If you’re the type of person that likes building and tweaking systems, data engineering might be right for you. A data pipeline — input data is transformed in a series of phases into output data.
Take Astro (the fully managed Airflow solution) for a test drive today and unlock a suite of features designed to simplify, optimize, and scale your data pipelines. I often wonder if we are building a pyramid infrastructure scheme on top of the object storage.
DoorDash has been building an internal Machine Learning Workbench over the past year to enhance data operations and assist our data scientists, analysts, and AI/ML engineers. We also shed light on how we drove value by taking a user-centered approach while building this internal tool.
Related to the neglect of data quality, it has been observed that much of the efforts in AI have been model-centric, that is, mostly devoted to developing and improving models , given fixed data sets. Data Cascades are said to be pervasive, to lack immediate visibility, but to eventually impact the world in a negative manner. Conclusions.
In a nutshell, DataOps engineers are responsible not only for designing and building data pipelines, but iterating on them via automation and collaboration as well. While a DataOps engineer is primarily focused on ensuring pipelines run smoothly, data engineers are more focused on designing and implementing those pipelines themselves.
SQL – A database may be used to build data warehousing, combine it with other technologies, and analyze the data for commercial reasons with the help of strong SQL abilities. Pipeline-centric: Pipeline-centric Data Engineers collaborate with data researchers to maximize the use of the info they gather.
Treating data as a product is more than a concept; it’s a paradigm shift that can significantly elevate the value that business intelligence and data-centric decision-making have on the business. Data pipelines Data integrity Data lineage Data stewardship Data catalog Data product costing Let’s review each one in detail.
Event-first thinking enables us to build a new atomic unit: the event. This model is completely free form, we can build anything provided that we apply mechanical sympathy with the underlying system behavior. Building the KPay payment system. Pillar 1 – Business function: Payment processing pipeline.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content