This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary Building streaming applications has gotten substantially easier over the past several years. Despite this, it is still operationally challenging to deploy and maintain your own stream processing infrastructure. What was the process for adding full Java support in addition to SQL? Rudderstack :  reported a medium level of automation adoption, meaning they currently have a mix of automated and manual SAP processes.
Why do some embedded analytics projects succeed while others fail? We surveyed 500+ application teams embedding analytics to find out which analytics features actually move the needle. Read the 6th annual State of Embedded Analytics Report to discover new best practices. Brought to you by Logi Analytics.
Multimodal AI models capable of processing multiple different types of inputs like speech, text, and images have been transforming user experiences in the wearables space. Shane sits down with Pascal Hartig to share how his team is building foundational models for the Ray-Ban Meta glasses.
By the end of 2024, we’re aiming to continue to grow our infrastructure build-out that will include 350,000 NVIDIA H100 GPUs as part of a portfolio that will feature compute power equivalent to nearly 600,000 H100s. RSC has accelerated our open and responsible AI research by helping us build our first generation of advanced AI models.
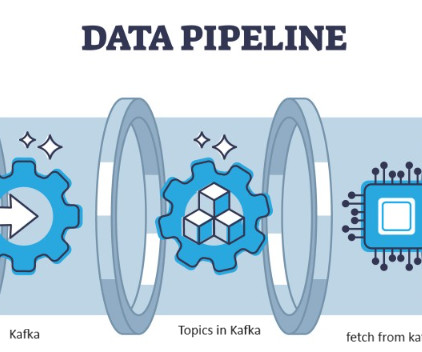
What is Real-Time Stream Processing? To access real-time data, organizations are turning to stream processing. To access real-time data, organizations are turning to stream processing. There are two main data processing paradigms: batch processing and stream processing.
Think your customers will pay more for data visualizations in your application? Five years ago they may have. But today, dashboards and visualizations have become table stakes. Discover which features will differentiate your application and maximize the ROI of your embedded analytics. Brought to you by Logi Analytics.
Personalization Stack Building a Gift-Optimized Recommendation System The success of Holiday Finds hinges on our ability to surface the right gift ideas at the right time. Unified Logging System: We implemented comprehensive engagement tracking that helps us understand how users interact with gift content differently from standardPins.
The introduction of these faster, more powerful networks has triggered an explosion of data, which needs to be processed in real time to meet customer demands. As more data is processed, carriers increasingly need to adopt hybrid cloud architectures to balance different workload demands.
In this episode he explains the data collection and preparation process, the collection of model types and sizes that work together to power the experience, and how to incorporate it into your workflow to act as a second brain. Go to dataengineeringpodcast.com/dagster today to get started. Your first 30 days are free!
Introduction Imagine yourself as a data professional tasked with creating an efficient data pipeline to streamline processes and generate real-time information. Sounds challenging, right? That’s where Mage AI comes in to ensure that the lenders operating online gain a competitive edge.
Summary Data processing technologies have dramatically improved in their sophistication and raw throughput. When performing research and building prototypes of the projects, what is your process for incorporating user experience into the implementation of the product?
A refresher on OpenAI, and on Evan Evan: how did you join OpenAI, and end up heading the Applied engineering group – which also builds ChatGPT? I do not have a PhD in Machine Learning, and was excited by the idea of building APIs and engineering teams. We do it through a process called pretraining.
A €150K ($165K) grant, three people, and 10 months to build it. Code and raw data repository: Version control: GitHub Heavily using GitHub Actions for things like getting warehouse data from vendor APIs, starting cloud servers, running benchmarks, processing results, and cleaning up after tuns. Tech stack.
At Snowflake BUILD , we are introducing powerful new features designed to accelerate building and deploying generative AI applications on enterprise data, while helping you ensure trust and safety. These scalable models can handle millions of records, enabling you to efficiently build high-performing NLP data pipelines.
Assumptions mapping is the process of identifying and testing your riskiest ideas. Watch this webinar with Laura Klein, product manager and author of Build Better Products, to learn how to spot the unconscious assumptions which you’re basing decisions on and guidelines for validating (or invalidating) your ideas.
How to Build a Data Dashboard Prototype with Generative AI A book reading data visualization withVizro-AI This article is a tutorial that shows how to build a data dashboard to visualize book reading data taken from goodreads.com. Now you can use Vizro-AI to build some charts by iterating text to form effective prompts.
In order to build high-quality data lineage, we developed different techniques to collect data flow signals across different technology stacks: static code analysis for different languages, runtime instrumentation, and input and output data matching, etc. In this blog, we will delve into an early stage in PAI implementation: data lineage.
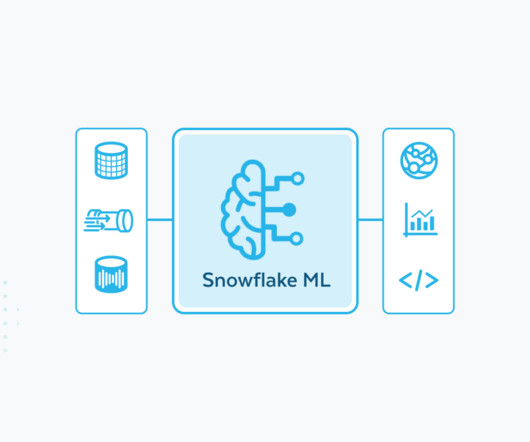
For image data, running distributed PyTorch on Snowflake ML also with standard settings resulted in over 10x faster processing for a 50,000-image dataset when compared to the same managed Spark solution. Many enterprises are already using Container Runtime to cost-effectively build advanced ML use cases with easy access to GPUs.
A data engineering architecture is the structural framework that determines how data flows through an organization – from collection and storage to processing and analysis. Before building your own data architecture from scratch though, why not steal – er, learn from – what industry leaders have already figured out?
As an innovative concept, Developer Experience (DX) has gained significant attention in the tech industry, and emphasizes engineers’ efficiency and satisfaction during the product development process.
He then worked at the casual games company Zynga, building their in-game advertising platform. We didn’t build our applications in neat containers, but in bulky monoliths which commingled business, database, backend, and frontend logic. Our deployments were initially manual. Apache started to log like a maniac.
Over the past four weeks, I took a break from blogging and LinkedIn to focus on building nao. DeepSeek is a model trained by the Chinese company with the same name, they directly compete with OpenAI and all to build foundational models. Models news and tour DeepSeek-v3 — It entered the space with a bang.
We expect that over the coming years, structured data is going to become heavily integrated into AI workflows and that dbt will play a key role in building and provisioning this data. We are committed to building the data control plane that enables AI to reliably access structured data from across your entire data lineage.
Welcome to Snowflakes Startup Spotlight, where we learn about awesome companies building businesses on Snowflake. By integrating AI agents, ROE AIs platform simplifies data processing, enabling organizations across industries to automate manual workflows and derive actionable intelligence from data.
for the simulation engine Go on the backend PostgreSQL for the data layer React and TypeScript on the frontend Prometheus and Grafana for monitoring and observability And if you were wondering how all of this was built, Juraj documented his process in an incredible, 34-part blog series. You can read this here. ” stage Improve deploys.
Now, it’s time to BUILD. Join us for BUILD 2024, a three-day global virtual conference taking place Nov. 12-15, to hear major Snowflake product announcements firsthand and to learn how to build with our latest innovations through dozens of technical sessions and hands-on labs.
Discover the insights he gained from academia and industry, his perspective on the future of data processing and the story behind building a next-generation graph database. Semih explains how Kuzu addresses the challenges of large graph analytics, the benefits of embeddability, and its potential for applications in AI and beyond.
Large language models are revolutionizing how we interact with technology by leveraging advanced natural language processing to perform complex tasks. In recent years.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content