This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Efficient Scheduling and Runtime Increased Adaptability and Scope Faster Analysis and Real-Time Prediction Introduction to the Machine Learning Pipeline Architecture How to Build an End-to-End a Machine Learning Pipeline? This makes it easier for machine learning pipelines to fit into any model-building application.
They still take on the responsibilities of a traditional data engineer, like building and managing pipelines and maintaining data quality, but they are tasked with delivering AI data products, rather than traditional data products. The ability and skills to build scalable, automated data pipelines.
Over the past four weeks, I took a break from blogging and LinkedIn to focus on building nao. DeepSeek is a model trained by the Chinese company with the same name, they directly compete with OpenAI and all to build foundational models. Models news and tour DeepSeek-v3 — It entered the space with a bang. Not really digest.
In order to build high-quality data lineage, we developed different techniques to collect data flow signals across different technology stacks: static code analysis for different languages, runtime instrumentation, and input and output data matching, etc. Hack, C++, Python, etc.)
We know you are enthusiastic about building data pipelines from scratch using Airflow. For example, if we want to build a small traffic dashboard that tells us what sections of the highway suffer traffic congestion. Apache Airflow is a batch-oriented tool for building data pipelines. Table of Contents What is Apache Airflow?
Using Airflow for Building and Monitoring the Data Pipeline of Amazon Redshift 4. Top10 AWS Redshift Project Ideas and Examples for Practice This article will list the top 10 AWS project ideas for beginners, intermediates, and experts who want to master the art of building data pipelines using AWS Redshift. Image credit: dev.to/aws-builders/build-a-data-warehouse-quickly-with-amazon-redshift-2op8
Consequently, over the years, our test collateral grew unchecked, the development environment became increasingly intricate and build and test times slowed down significantly, negatively impacting developer productivity. Transparency helps build customer trust and keeps feedback flowing.
At Snowflake, we’re removing the barriers that prevent productive cooperation while building the connections to make working together easier than ever. Effective collaboration on data and AI has never been more closely tied to success.
Build and deploy ETL/ELT data pipelines that can begin with data ingestion and complete various data-related tasks. Access various data resources with the help of tools like SQL and Big Data technologies for building efficient ETL data pipelines. A data engineer relies on Python and other programminglanguages for this task.
This guide is your roadmap to building a data lake from scratch. Data Lake Architecture- Core Foundations How To Build a Data Lake From Scratch-A Step-by-Step Guide Tips on Building a Data Lake by Top Industry Experts Building a Data Lake on Specific Platforms How to Build a Data Lake on AWS?
Register now Home Insights Artificial Intelligence Article Build a Data Mesh Architecture Using Teradata VantageCloud on AWS Explore how to build a data mesh architecture using Teradata VantageCloud Lake as the core data platform on AWS. The data mesh architecture Key components of the data mesh architecture 1.
It involves building pipelines that can fetch data from the source, transform it into a usable form, and analyze variables present in the data. Build an Awesome Job Winning Data Engineering Projects Portfoli o Data Engineer: Job Growth in Future The demand for data engineers has been on a sharp rise since 2016.
Worried about building a great data engineer resume ? We also have a few tips and guidelines for beginner-level and senior data engineers on how they can build an impressive resume. We have seven expert tips for building the ideal data engineer resume. 180 zettabytes- the amount of data we will likely generate by 2025!
Join us as we navigate the MLops landscape, uncovering the secrets to build a simple MLOps pipeline on your local machine that not only streamlines your workflow but elevates the impact of your machine learning projects. Best Practices for MLOps End to End Implementation Learn To Build Efficient MLOps Pipelines with ProjectPro!
Getting Started with NLTK NLP with NLTK in Python NLTK Tutorial-1: Text Classification using NLTK NLTK Tutorial-2: Text Similarity and Clustering using NLTK NLTK Tutorial-3: Working with Word Embeddings in NLTK Top 3 NLTK NLP Project Ideas for Practice Build Custom NLP Models using NLTK with ProjectPro!
If you are new to machine learning , it means that you have been wheedled by this incredible field of study and its limitless possibilities of building applications that have never been implemented without human intervention, congratulations and welcome to the world of deep learning!
Streamlit Project Example to Build a Customer Segmentation Model Customer segmentation divides customers into categories based on shared criteria so that organizations may effectively and appropriately promote each group. What makes Python one of the best programminglanguages for ML Projects? Check them out now!
The CDK generates the necessary AWS CloudFormation templates and resources in the background, while allowing data engineers to leverage the full power of programminglanguages, including code reusability, version control, and testing. AWS CDK Concepts The AWS CDK has three core concepts: App, Constructs, and Stacks.
Language-specific Initialization Initialization times vary throughout programminglanguages. Some languages may have faster cold starts compared to others. Language-specific Optimization The next step involves assessing the choice of programminglanguage.
AWS Machine Learning is a suite of services that helps you build, train, and deploy machine learning models. Here are a few reasons why a data scientist or data engineer must consider using AWS Machine Learning (ML) for building their projects- Scalability and Flexibility- AWS can scale your ML solutions based on demand.
Building a real-world ETL project requires more than just moving data from one place to another—it demands a meticulous approach to ensuring data quality. Trust and Credibility: Organizations prioritizing data quality build trust with stakeholders, customers, and partners, enhancing their credibility in the market.
Applications exchanging messages on the two ends can be written in a different programminglanguage and don't have to conform to a specific message format. Message - These are the building blocks of partitions. They act as the message brokers between applications/services endpoints. Binary exchange.
We discovered that a flexible and incremental approach was necessary to onboard the wide variety of systems and languages used in building Metas products. Were upholding that by investing our vast engineering capabilities into building cutting-edge privacy technology. We believe that privacy drives product innovation.
Key Features: With Dataproc, you can easily use the open-source tools, algorithms, and programminglanguages you are already familiar with on cloud-scale datasets. If you want to gain hands-on experience with Google Cloud Data Studio, you must explore Build a Scalable Event-Based GCP Data Pipeline.
As understanding how to deal with data is becoming more important, today I want to show you how to build a Python workflow with DuckDB and explore its key features. This works similarly to if-else statements in programminglanguages, allowing you to apply conditional logic in your queries. Let’s dive in! What Is DuckDB?
The Data Platform Fundamentals Guide Learn the fundamental concepts to build a data platform in your organization. As languages become more niche and specific, the performance of these models drops off a cliff and becomes abysmal.
Apache Airflow Project Ideas Build an ETL Pipeline with DBT, Snowflake and Airflow End-to-End ML Model Monitoring using Airflow and Docker AWS Snowflake Data Pipeline Example using Kinesis and Airflow 2. Apache Airflow Cons The learning curve can be steep for beginners. Requires substantial resources, especially for large-scale deployments.
A data architect, in turn, understands the business requirements, examines the current data structures, and develops a design for building an integrated framework of easily accessible, safe data aligned with business strategy. Machine Learning Architects build scalable systems for use with AI/ML models.
Companies are actively seeking talent in these areas, and there is a huge market for individuals who can manipulate data, work with large databases and build machine learning algorithms. How can ProjectPro Help You Build a Career in AI? These people would then work in different teams to build and deploy a scalable AI application.
An ETL developer designs, builds and manages data storage systems while ensuring they have important data for the business. Still, he will not be able to proceed with making a connector for XML format, assuming he does not know programminglanguages and the ETL tool doesn't allow plugins.
Step 1: Learn a ProgrammingLanguage Step 2: Understanding the Basics of Big Data Step 3: Set up the System Step 4: Master Spark Core Concepts Step 5: Explore the Spark Ecosystem Step 6: Work on Real-World Projects Resources to Learn Spark Learn Spark through ProjectPro Projects! Table of Contents Why Learn Apache Spark?
It even allows you to build a program that defines the data pipeline using open-source Beam SDKs (Software Development Kits) in any three programminglanguages: Java, Python, and Go. Cython Source: Wikipedia Cython is a static optimizer for the Python programminglanguage.
As demand for data engineers increases, the default programminglanguage for completing various data engineering tasks is accredited to Python. One of the main reasons for this popular accreditation is that it is one of the most popular languages for data science. Python also tops TIOBE Index for May 2022.
Scala has been one of the most trusted and reliable programminglanguages for several tech giants and startups to develop and deploy their big data applications. Scala is a general-purpose programminglanguage released in 2004 as an improvement over Java. Table of Contents What is Scala for Data Engineering?
Hence, data engineering is building, designing, and maintaining systems that handle data of different types. The data engineering role requires professionals who can build various data pipelines to enable data-driven models. Build, test, and maintain database pipeline architectures. We call this system Data Engineering.
Databricks is a cloud-based data warehousing platform for processing, analyzing, storing, and transforming large amounts of data to build machine learning models. Databricks vs. Azure Synapse: ProgrammingLanguage Support Azure Synapse supports programminglanguages such as Python, SQL, and Scala.
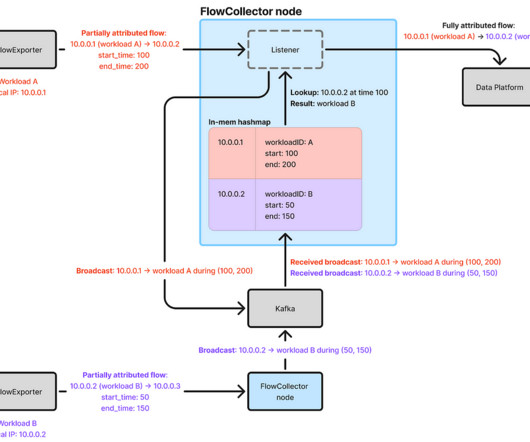
The eBPF flow logs provide a comprehensive view of service topology and network health across Netflixs extensive microservices fleet, regardless of the programminglanguage, RPC mechanism, or application-layer protocol used by individual workloads.
Microsoft Azure is one of the most popular unified cloud-based platform for data engineers and data scientists to perform ETL processes and build ML models. Is it possible to utilize multiple languages in one notebook, or are there substantial restrictions? Write your program in Scala or Python if possible.
Due to this, analysts without a strong background in other programminglanguages can efficiently perform data transformation using dbt. With the help of Airflow, users can build highly detailed workflows and monitor their execution. The creation of boilerplate code is not necessary.
Apache Spark Developer is a software developer or a big data developer who specializes in building large data-processing applications or solutions using Apache Spark big data framework. A spark developer must know one of these programminglanguages to write efficient and optimized Spark Applications.
Build, Design, and maintain data architectures using a systematic approach that satisfies business needs. 1) Data Warehousing With many companies showing great interest in data as a resource, most have started investing in building data warehouses that collect and store data from various sources regularly.
Let's delve deeper into the essential responsibilities and skills of a Big Data Developer: Develop and Maintain Data Pipelines using ETL Processes Big Data Developers are responsible for designing and building data pipelines that extract, transform, and load (ETL) data from various sources into the Big Data ecosystem.
Python is one of the most extensively used programminglanguages for Data Analysis, Machine Learning , and data science tasks. Exploratory data analysis (EDA) is crucial in determining data collection structure in a data science workflow, and PySpark can be used for exploratory data analysis and building machine learning pipelines.
Imagine you're a big data developer tasked with building a new serverless application for your organization. These platforms are based on the Functions as a Service (FaaS) model and support a variety of programminglanguages, as well as similar pricing models. However, choosing between these two options can be a challenge.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content