This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Snowflakes Snowpark is a game-changing feature that enables data engineers and analysts to write scalable data transformation workflows directly within Snowflake using Python, Java, or Scala. They need to: Consolidate rawdata from orders, customers, and products. Enrich and clean data for downstream analytics.
Welcome to Snowflakes Startup Spotlight, where we learn about awesome companies building businesses on Snowflake. In this edition, discover how Houssam Fahs, CEO and Co-founder of KAWA Analytics , is on a mission to revolutionize the creation of data-driven applications with a cutting-edge, AI-native platform built for scalability.
A €150K ($165K) grant, three people, and 10 months to build it. Databases: SQLite files used to publish data Duck DB to query these files in the public APIs Cockroach DB : used to collect and store historical data. We envision building something comparable to AWS Fargate , or Google Cloud Run. Tech stack.
It sounds great, but how do you prove the data is correct at each layer? How do you ensure data quality in every layer ? Bronze, Silver, and Gold – The Data Architecture Olympics? The Bronze layer is the initial landing zone for all incoming rawdata, capturing it in its unprocessed, original form.
Which turned into data lakes and data lakehouses Poor data quality turned Hadoop into a data swamp, and what sounds better than a data swamp? A data lake! Data management best practices havent changed. AI is not going to fix or dismiss the need for proper data governance.
However, copying and storing data from the warehouse in these other systems presented material computational and storage costs that were not offset by the overall effectiveness of the cache, making this infeasible as well. We do this by passing the rawdata through various renderers, discussed in more detail in the next section.
The goal of dimensional modeling is to take rawdata and transform it into Fact and Dimension tables that represent the business. We can then build the OBT by running dbt run. Your dbt DAG should now look like this: Final dbt DAG Congratulations, you have reached the end of this tutorial.
In the ELT, the load is done before the transform part without any alteration of the data leaving the rawdata ready to be transformed in the data warehouse. In a simple words dbt sits on top of your rawdata to organise all your SQL queries that are defining your data assets.
A data engineering architecture is the structural framework that determines how data flows through an organization – from collection and storage to processing and analysis. It’s the big blueprint we data engineers follow in order to transform rawdata into valuable insights. Why Flink instead of Spark?
At Snowflake BUILD , we are introducing powerful new features designed to accelerate building and deploying generative AI applications on enterprise data, while helping you ensure trust and safety. These scalable models can handle millions of records, enabling you to efficiently build high-performing NLP data pipelines.
Executives, data teams, and even end-users understand that AI means more than building models; it means unlocking strategic value. By trimming acronyms and complex naming, were removing barriers so you can quickly find what you need and get to work building intelligence into every decision. Ready to learn more?
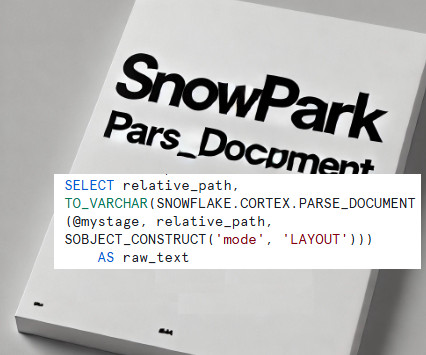
However, Ive taken this a step further, leveraging Snowpark to extend its capabilities and build a complete data extraction process. This blog explores how you can leverage the power of PARSE_DOCUMENT with Snowpark, showcasing a use case to extract, clean, and process data from PDF documents. policy holder name, policy number).
With the customer at its heart, modern augmented BI platforms no longer require scripting/coding skills or the knowledge to build the back-end data models, empowering even laymen to harness the power of rawdata. As a user, here are the top AI capabilities that you need to look for in BI software.
How to build a modern, scalable data platform to power your analytics and data science projects (updated) Table of Contents: What’s changed? The Platform Integration Data Store Transformation Orchestration Presentation Transportation Observability Closing What’s changed?
The same relates to those who buy annotated sound collections from data providers. But if you have only rawdata meaning recordings saved in one of the audio file formats you need to get them ready for machine learning. Audio data labeling. Building an app for snore and teeth grinding detection.
Building a large scale unsupervised model anomaly detection system — Part 1 Distributed Profiling of Model Inference Logs By Anindya Saha , Han Wang , Rajeev Prabhakar Introduction LyftLearn is Lyft’s ML Platform. We instrument all inference requests, sample and store a certain percentage of model inference requests and emitted predictions.
What is Data Transformation? Data transformation is the process of converting rawdata into a usable format to generate insights. It involves cleaning, normalizing, validating, and enriching data, ensuring that it is consistent and ready for analysis.
We covered how Data Quality Testing, Observability, and Scorecards turn data quality into a dynamic process, helping you build accuracy, consistency, and trust at each layerBronze, Silver, and Gold.
Bring your raw Google Analytics data to Snowflake with just a few clicks The Snowflake Connector for Google Analytics makes it a breeze to get your Google Analytics data, either aggregated data or rawdata, into your Snowflake account. Here’s a quick guide to get started: 1. But don’t just take it from us.
Code implementations for ML pipelines: from rawdata to predictions Photo by Rodion Kutsaiev on Unsplash Real-life machine learning involves a series of tasks to prepare the data before the magic predictions take place.
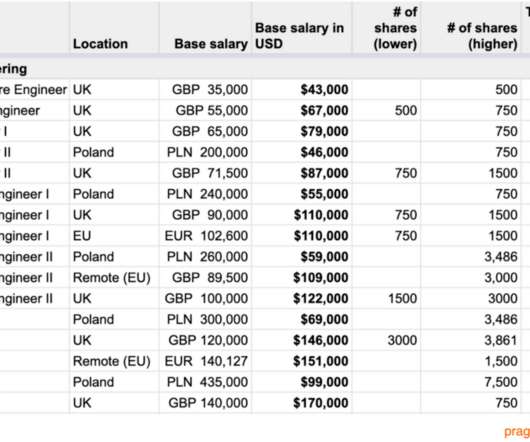
In this week’s The Scoop, I analyzed this information and dissected it, going well beyond the rawdata. Here are a few details from the data points, focusing on software engineering compensation. Every employee could examine a PDF with compensation details for every role at the company.
Unlike Uber, Agoda does not make use of public cloud providers, having decided to build out its own private cloud, instead. This group doesn’t include the software layer for infrastructure, which is a software team that builds the orchestration platform (Fleet) upon Kubernetes. In some cases this makes sense.
Image from Unsplash Building a Semantic Book Search: Scale an Embedding Pipeline with Apache Spark and AWS EMR Serverless Using OpenAI’s Clip model to support natural language search on a collection of 70k book covers In a previous post I did a little PoC to see if I could use OpenAI’s Clip model to build a semantic book search.
As you do not want to start your development with uncertainty, you decide to go for the operational rawdata directly. Accessing Operational Data I used to connect to views in transactional databases or APIs offered by operational systems to request the rawdata. Does it sound familiar?
Building a large scale unsupervised model anomaly detection system — Part 2 Building ML Models with Observability at Scale By Rajeev Prabhakar , Han Wang , Anindya Saha Photo by Octavian Rosca on Unsplash In our previous blog we discussed the different challenges we faced for model monitoring and our strategy for addressing some of these problems.
Understanding the Tools One platform is designed primarily for business intelligence, offering intuitive ways to connect to various data sources, build interactive dashboards, and share insights. Its purpose is to simplify data exploration for users across skill levels. What is Power BI?
This is one of the biggest advantages of building profilers using eBPF: complex and customized actions taken at sample time. Strobelight also delays symbolization until after profiling and stores rawdata to disk to prevent memory thrash on the host. To add to that enchilada (hungry yet?),
We work with organizations around the globe that have diverse needs but can only achieve their objectives with expertly curated data sets containing thousands of different attributes. Practitioners can rely on consistent data to extract meaningful features contributing to model performance. Clean data reduces the need for data prep.
After the hustle and bustle of extracting data from multiple sources, you have finally loaded all your data to a single source of truth like the Snowflake data warehouse. However, data modeling is still challenging and critical for transforming your rawdata into any analysis-ready form to get insights.
Welcome to Snowflake’s Startup Spotlight, where we learn about awesome companies building businesses on Snowflake. Traveling over hard ground on the way to building something important is what inspires me. Hum is harnessing frontier AI to transform content and audience data into actionable insights and personalized experiences.
The data warehouse needs to reflect the business, and the business should have clarity on how it thinks about analytics. Conflicting nomenclature and inconsistent data across different namespaces, or “ data marts ” are problematic. Data engineers are many degrees removed from those who are “moving the needle”.
The data industry has a wide variety of approaches and philosophies for managing data: Inman data factory, Kimball methodology, s tar schema , or the data vault pattern, which can be a great way to store and organize rawdata, and more. Data mesh does not replace or require any of these.
If a model do not respect a contract it will not build. In dbt vocabulary build means run + other things. Building a ChatGPT Plugin for Medium. Fast News ⚡️ Building a Flink self-serve platform on Kubernetes at scale — Instacart engineering team migrated from Flink on EMR to Flink on Kubernetes.
Read our eBook Validation and Enrichment: Harnessing Insights from RawData In this ebook, we delve into the crucial data validation and enrichment process, uncovering the challenges organizations face and presenting solutions to simplify and enhance these processes.
Now that you have learned what batch data processing is, let’s move on to the next step: creating and managing batch processing pipelines in VDK. 2 Creating and Managing Batch Processing Pipelines in VDK VDK adopts a component-based approach, enabling you to builddata processing pipelines quickly. link] Summary Congratulations!
We talked about their plans for GenAI and the challenges theyve encountered as they incorporate large language models (LLMs) into their data products while prioritizing consistency and reliability. The company uses a medallion architecture, where data flows from raw (bronze) to standardized (silver) to aggregated (gold) layers.
RAPIDS on the Cloudera Data Platform comes pre-configured with all the necessary libraries and dependencies to bring the power of RAPIDS to your projects. RAPIDS brings the power of GPU compute to standard Data Science operations, be it exploratory data analysis, feature engineering or model building. Data Ingestion.
There’s also some static reference data that is published on web pages. ?After Wrangling the data. With the rawdata in Kafka, we can now start to process it. Since we’re using Kafka, we are working on streams of data. After we scrape these manually, they are produced directly into a Kafka topic.
Learn how we builddata lake infrastructures and help organizations all around the world achieving their data goals. In today's data-driven world, organizations are faced with the challenge of managing and processing large volumes of data efficiently.
This was the first year that startups had the chance to build with our Native Applications Framework (currently in private preview), and we were thrilled to see the number of entries that included a native app. It transforms multiple financial and operational systems’ rawdata into a common, friendly data model that people can understand.
The second Applied Machine Learning Prototype that was made available is for building a fraud detection model. . These are prototypes that will help you build a fully working machine learning example in CML. The Templates will include source data and walk through various steps: Ingest data into a useful place in CDP (e.g.
A 2016 data science report from data enrichment platform CrowdFlower found that data scientists spend around 80% of their time in data preparation (collecting, cleaning, and organizing of data) before they can even begin to build machine learning (ML) models to deliver business value.
Want to run SQL queries on your structured data while also keeping raw files for your data scientists to play with? The data lakehouse has got you covered! Data typically flows through three stages: Bronze : Rawdata lands here first, preserved in its original form.
With the customer at its heart, modern augmented BI platforms no longer require scripting/coding skills or the knowledge to build the back-end data models, empowering even laymen to harness the power of rawdata. As a user, here are the top AI capabilities that you need to look for in BI software.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content