This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Imagine scheduling your ML tasks to run automatically without the need for manual […] The post How to Build and Monitor Systems Using Airflow? Airflow can help you manage your workflow and make your life easier with its monitoring and notifications features. appeared first on Analytics Vidhya.
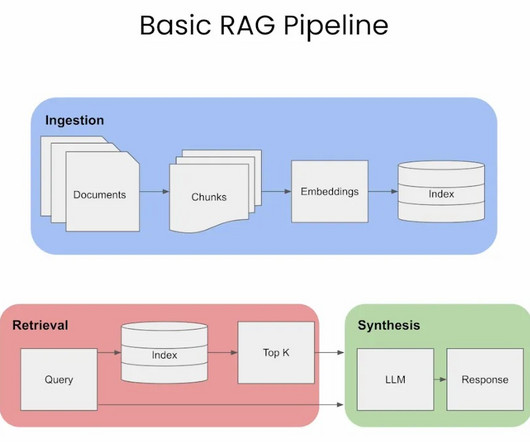
The ability to extract information from vast amounts of text has made question-answering (QA) systems essential in the modern era of AI-driven apps. RAG-based question-answering systems use large language models to generate human-like responses to user queries.
Retrieval augmented generation (RAG) is altering the way we use large language models, but building these systems can be hectic. In this article, you will learn how to build RAG systems using Haystack.
Building efficient data pipelines with DuckDB 4.1. Distributed systems are scalable, resilient to failures, & designed for high availability 4.5. Introduction 2. Project demo 3. Use DuckDB to process data, not for multiple users to access data 4.2. Cost calculation: DuckDB + Ephemeral VMs = dirt cheap data processing 4.3.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API.
Many of our customers are shifting from monolithic prompts with general-purpose models to specialized compound AI systems to achieve the quality needed for.
Were explaining the end-to-end systems the Facebook app leverages to deliver relevant content to people. At Facebooks scale, the systems built to support and overcome these challenges require extensive trade-off analyses, focused optimizations, and architecture built to allow our engineers to push for the same user and business outcomes.
Over the last year, we have seen a surge of commercial and open-source foundation models showing strong reasoning abilities on general knowledge tasks.
However, during development – and even more so once deployed to production – best practices for operating and improving generative AI applications are less understood. Register today to save your seat! December 6th, 2023 at 11:00am PST, 2:00pm EST, 7:pm GMT
Modern large-scale recommendation systems usually include multiple stages where retrieval aims at retrieving candidates from billions of candidate pools, and ranking predicts which item a user tends to engage from the trimmed candidate set retrieved from early stages [2]. General multi-stage recommendation system design in Pinterest.
Summary A significant amount of time in data engineering is dedicated to building connections and semantic meaning around pieces of information. In this episode Brian Platz explains how JSON-LD can be used as a shared representation of linked data for building semantic data products. Hex brings everything together.
Summary Any software system that survives long enough will require some form of migration or evolution. When that system is responsible for the data layer the process becomes more challenging. As you have gone through successive migration projects, how has that influenced the ways that you think about architecting data systems?
In this blog, well explore Building an ETL Pipeline with Snowpark by simulating a scenario where commerce data flows through distinct data layersRAW, SILVER, and GOLDEN.These tables form the foundation for insightful analytics and robust business intelligence. Create a fact table to summarize daily sales. Develop a VIEW in Semantic Layer.
Speaker: Ben Epstein, Stealth Founder & CTO | Tony Karrer, Founder & CTO, Aggregage
When tasked with building a fundamentally new product line with deeper insights than previously achievable for a high-value client, Ben Epstein and his team faced a significant challenge: how to harness LLMs to produce consistent, high-accuracy outputs at scale.
By the end of 2024, we’re aiming to continue to grow our infrastructure build-out that will include 350,000 NVIDIA H100 GPUs as part of a portfolio that will feature compute power equivalent to nearly 600,000 H100s. RSC has accelerated our open and responsible AI research by helping us build our first generation of advanced AI models.
Unified Logging System: We implemented comprehensive engagement tracking that helps us understand how users interact with gift content differently from standardPins. Personalization Stack Building a Gift-Optimized Recommendation System The success of Holiday Finds hinges on our ability to surface the right gift ideas at the right time.
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. These systems are built on open standards and offer immense analytical and transactional processing flexibility. These formats are transforming how organizations manage large datasets.
Summary Building streaming applications has gotten substantially easier over the past several years. Decodable was built with a mission of eliminating all of the painful aspects of developing and deploying stream processing systems for engineering teams. How can you get the best results for your use case? Rudderstack :  is crucial, as it offers a framework for scaling, monitoring, and refining AI agents.
” Brooks agrees with this observation, and suggests a radical solution: have as few senior programmers as possible, and build a team around each one – a bit like how a hospital surgeon leads a whole team. Brooks discusses software in the context of producing operating systems, pre-internet. A most interesting addition!
This will help you decide whether to build an in-house entity resolution system or utilize an existing solution like the Senzing® API for entity resolution. This guide will walk you through the requirements and challenges of implementing entity resolution.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Dagster offers a new approach to building and running data platforms and data pipelines. Go to dataengineeringpodcast.com/dagster today to get started. Your first 30 days are free! Data lakes are notoriously complex.
And its not sufficient to simply build these data + AI applications – as in any other technological discipline, you have to do it reliably, too. System Data + AI applications rely on a complex and interconnected web of tools and systems to deliver insights, models and automations.
Over the past four weeks, I took a break from blogging and LinkedIn to focus on building nao. AI companies are aiming for the moon—AGI—promising it will arrive once OpenAI develops a system capable of generating at least $100 billion in profits. Meanwhile, the AI landscape remains unpredictable.
As an example: Systems for authenticating users Dashboards and tools for showing info A small e-commerce site with shopping carts, payment methods, and the ability to browse products. Building APIs Flask is often used to make RESTful APIs that let different apps talk to each other. Steeper learning curve for larger projects.
Think your customers will pay more for data visualizations in your application? Five years ago they may have. But today, dashboards and visualizations have become table stakes. Discover which features will differentiate your application and maximize the ROI of your embedded analytics. Brought to you by Logi Analytics.
It is a critical and powerful tool for scalable discovery of relevant data and data flows, which supports privacy controls across Metas systems. It enhances the traceability of data flows within systems, ultimately empowering developers to swiftly implement privacy controls and create innovative products.
A €150K ($165K) grant, three people, and 10 months to build it. We recently covered how CockroachDB joins the trend of moving from open source to proprietary and why Oxide decided to keep using it with self-support , regardless Web hosting: Netlify : chosen thanks to their super smooth preview system with SSR support.
Consequently, over the years, our test collateral grew unchecked, the development environment became increasingly intricate and build and test times slowed down significantly, negatively impacting developer productivity. Transparency helps build customer trust and keeps feedback flowing.
Summary Monitoring and auditing IT systems for security events requires the ability to quickly analyze massive volumes of unstructured log data. The majority of products that are available either require too much effort to structure the logs, or aren't fast enough for interactive use cases.
If you had a continuous deployment system up and running around 2010, you were ahead of the pack: but today it’s considered strange if your team would not have this for things like web applications. He then worked at the casual games company Zynga, building their in-game advertising platform.
We expect that over the coming years, structured data is going to become heavily integrated into AI workflows and that dbt will play a key role in building and provisioning this data. We are committed to building the data control plane that enables AI to reliably access structured data from across your entire data lineage.
Juraj included system monitoring parts which monitor the server’s capacity he runs the app on: The monitoring page on the Rides app And it doesn’t end here. Juraj created a systems design explainer on how he built this project, and the technologies used: The systems design diagram for the Rides application The app uses: Node.js
The simple idea was, hey how can we get more value from the transactional data in our operational systems spanning finance, sales, customer relationship management, and other siloed functions. Data integration best practices are required to build and train the LLM or SLM with the necessary information and context.
Semih is a researcher and entrepreneur with a background in distributed systems and databases. He then pursued his doctoral studies at Stanford University, delving into the complexities of database systems. Dont forget to subscribe to my YouTube channel to get the latest on Unapologetically Technical!
He’s solved interesting engineering challenges along the way, too – like building observability for Amazon’s EC2 offering, and being one of the first engineers on Uber’s observability platform. I wrote code for drivers on Windows, and started to put a basic observability system in place.
In the early 90’s, DOS programs like the ones my company made had its own Text UI screen rendering system. This rendering system was easy for me to understand, even on day one. Our rendering system was very memory inefficient, but that could be fixed. By doing so, I got to see every screen of the system.
Part 2: Navigating Ambiguity By: VarunKhaitan With special thanks to my stunning colleagues: Mallika Rao , Esmir Mesic , HugoMarques Building on the foundation laid in Part 1 , where we explored the what behind the challenges of title launch observability at Netflix, this post shifts focus to the how.
A very popular open-source solution for systems and services monitoring. Prometheus is part of the Cloud Native Foundation, membership of which indicates that it’s safe to build on top of Prometheus, as it’s actively maintained and will continue to be. It evaluates rules and can trigger alerts. But why is this?
Welcome to Snowflakes Startup Spotlight, where we learn about awesome companies building businesses on Snowflake. Building relationships of trust with a team and an extended network of believers and even critics is all-important. Aging rules-based systems are failing to detect attacks effectively.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content