This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Error prevention: all of these data validation checks above contribute to a more proactive approach that minimizes the chance of downstream errors, and in turn, the effort required for datacleansing and correction later. Streamline the Process with Precisely Let’s talk about address data.
Power BI is a technology-driven businessintelligence tool or an array of software services, apps, and connectors to convert unrelated and raw data into visually immersive, coherent, actionable, and interactive insights and information. Conclusion A business can reach new heights by using the Power BI tool.
If you want to break into the field of data engineering but don't yet have any expertise in the field, compiling a portfolio of data engineering projects may help. Data pipeline best practices should be shown in these initiatives. Source: Use Stack Overflow Data for Analytic Purposes 4.
Spark Streaming Kafka Streams 1 Data received from live input data streams is Divided into Micro-batched for processing. processes per data stream(real real-time) 2 A separate processing Cluster is required No separate processing cluster is required. it's better for functions like row parsing, datacleansing, etc.
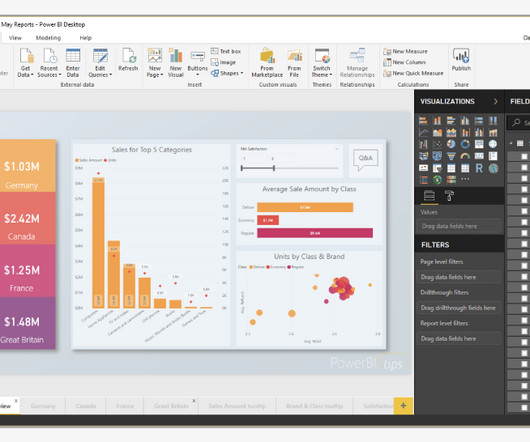
Power BI has become a widely used businessintelligence tool. Along with the ETL, data transformation and data modeling options. I've noticed a growing trend of businesses adopting Power BI and Fabric tools to elevate their data capabilities and refine decision-making processes. What is Power BI?
It entails using various technologies, including data mining, data transformation, and datacleansing, to examine and analyze that data. Both data science and software engineering rely largely on programming skills. However, data scientists are primarily concerned with working with massive datasets.
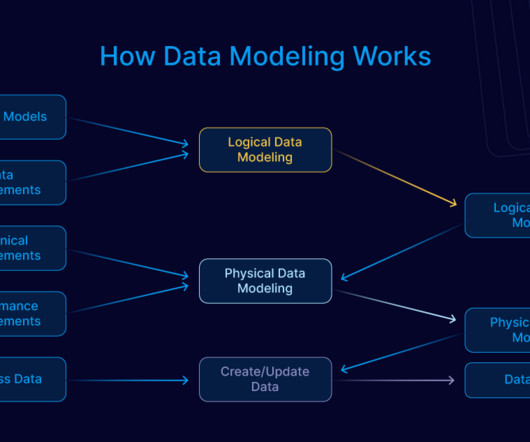
For any organization to grow, it requires businessintelligence reports and data to offer insights to aid in decision-making. This data and reports are generated and developed by Power BI developers. A power BI developer has a crucial role in business management. Mentor team members in data modeling techniques.
As you now know the key characteristics, it gets clear that not all data can be referred to as Big Data. What is Big Data analytics? Big Data analytics is the process of finding patterns, trends, and relationships in massive datasets that can’t be discovered with traditional data management techniques and tools.
The demand for data professionals with businessintelligence skills has increased significantly in recent years. With technological advancements and digital transformations, businesses are taking data very seriously. In today's business environment, data is an invaluable asset.
Data Processing and Cleaning : Preprocessing and data cleaning are important steps since raw data frequently has errors, duplication, missing information, and inconsistencies. To make sure the data is precise and suitable for analysis, data processing analysts use methods including datacleansing, imputation, and normalisation.
AI-driven tools can analyze large datasets in real time to detect subtle or unexpected deviations in schemachanges in field names, column counts, data types, or structural hierarchieswithout requiring extensive manual oversight. This is particularly helpful in environments where upstream data sources are subject to frequent revisions.
Due to its strong data analysis and manipulation skills, it has significantly increased its prominence in the field of data science. Python offers a strong ecosystem for data scientists to carry out activities like datacleansing, exploration, visualization, and modeling thanks to modules like NumPy, Pandas, and Matplotlib.
Artificial intelligence (AI) uses information to make important choices in different industries. Just like a tall building needs a strong plan and base, successful AI requires good data models. Techniques like outlier detection and imputation help make sure your data is reliable and ready for analysis.
Whether it's aggregating customer interactions, analyzing historical sales trends, or processing real-time sensor data, data extraction initiates the process. What is the purpose of extracting data? The purpose of data extraction is to transform large, unwieldy datasets into a usable and actionable format.
And if you are aspiring to become a data engineer, you must focus on these skills and practice at least one project around each of them to stand out from other candidates. Explore different types of Data Formats: A data engineer works with various dataset formats like.csv,josn,xlx, etc.
As per Microsoft, “A Power BI report is a multi-perspective view of a dataset, with visuals representing different findings and insights from that dataset. ” Reports and dashboards are the two vital components of the Power BI platform, which are used to analyze and visualize data. Use descriptive names.
In 2010, a transformative concept took root in the realm of data storage and analytics — a data lake. The term was coined by James Dixon , Back-End Java, Data, and BusinessIntelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data.
In-Memory Caching- Memory-optimized instances are suitable for in-memory caching solutions, enhancing the speed of data access. Big Data Processing- Workloads involving large datasets, analytics, and data processing can benefit from the enhanced memory capacity provided by M-Series instances.
Here the practice of data warehousing and warehouse system is very important and the use of right modelling techniques has become a very important factor in todays’ competitive world. In this choice, Big Data will play an important role and its choice is also inevitably crucial in the BusinessIntelligence and related systems.
Here are a few project ideas that are suitable for beginners: Analyzing a dataset to identify trends and patterns: One of the most common projects for beginners is to analyze a dataset to identify trends and patterns. Intermediate data analytics projects can be challenging but rewarding.
Learning visualization tools, such as Tableau , is a common way to improve your data visualization abilities. This industry-standard application allows you to turn your data into dashboards, data models, visualizations, and businessintelligence reports. 2) The skill to clean datasets completely.
Data Science is an interdisciplinary field that consists of numerous scientific methods, tools, algorithms, and Machine Learning approaches that attempt to identify patterns in the provided raw input data and derive practical insights from it. . The first step is to compile the pertinent data and business requirements.
MapReduce is a Hadoop framework used for processing large datasets. Another name for it is a programming model that enables us to process big datasets across computer clusters. This program allows for distributed data storage, simplifying complex processing and vast amounts of data. What is MapReduce in Hadoop?
CDWs are designed for running large and complex queries across vast amounts of data, making them ideal for centralizing an organization’s analytical data for the purpose of businessintelligence and data analytics applications. It should also enable easy sharing of insights across the organization.
Data Volumes and Veracity Data volume and quality decide how fast the AI System is ready to scale. The larger the set of predictions and usage, the larger is the implications of Data in the workflow. Complex Technology Implications at Scale Onerous DataCleansing & Preparation Tasks 3.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content