This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management RudderStack helps you build a customer data platform on your warehouse or datalake. Businessintelligence is a crowded market. Businessintelligence is a crowded market.
Data marts involved the creation of built-for-purpose analytic repositories meant to directly support more specific business users and reporting needs (e.g., But those end users werent always clear on which data they should use for which reports, as the data definitions were often unclear or conflicting. A datalake!
Introduction Enterprises here and now catalyze vast quantities of data, which can be a high-end source of businessintelligence and insight when used appropriately. Delta Lake allows businesses to access and break new data down in real time.
Summary Businessintelligence is the foremost application of data in organizations of all sizes. Zing Data is building a mobile native platform for businessintelligence. Trusted by the data teams at Fox, JetBlue, and PagerDuty, Monte Carlo solves the costly problem of broken data pipelines.
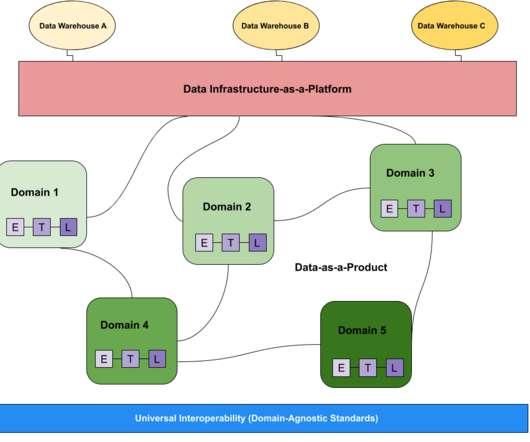
Over the years, the technology landscape for data management has given rise to various architecture patterns, each thoughtfully designed to cater to specific use cases and requirements. These patterns include both centralized storage patterns like data warehouse , datalake and data lakehouse , and distributed patterns such as data mesh.
Summary Designing a data platform is a complex and iterative undertaking which requires accounting for many conflicting needs. Designing a platform that relies on a datalake as its central architectural tenet adds additional layers of difficulty. When is a datalake architecture the wrong choice?
Snowflake is now making it even easier for customers to bring the platform’s usability, performance, governance and many workloads to more data with Iceberg tables (now generally available), unlocking full storage interoperability. Iceberg tables provide compute engine interoperability over a single copy of data.
It incorporates elements from several Microsoft products working together, like Power BI, Azure Synapse Analytics, Data Factory, and OneLake, into a single SaaS experience. No matter the workload, Fabric stores all data on OneLake, a single, unified datalake built on the Delta Lake model.
Despite these limitations, data warehouses, introduced in the late 1980s based on ideas developed even earlier, remain in widespread use today for certain businessintelligence and data analysis applications. While data warehouses are still in use, they are limited in use-cases as they only support structured data.
Push information about data freshness and quality to your businessintelligence, automatically scale up and down your warehouse based on usage patterns, and let the bots answer those questions in Slack so that the humans can focus on delivering real value.
One of the most important innovations in data management is open table formats, specifically Apache Iceberg , which fundamentally transforms the way data teams manage operational metadata in the datalake.
However, with Businessintelligence dashboards, knowledge is dispersed throughout the organization, enabling users to produce interactive reports, utilize data visualization, and disseminate the knowledge with internal and external stakeholders. What is a BusinessIntelligence Dashboard?
Push information about data freshness and quality to your businessintelligence, automatically scale up and down your warehouse based on usage patterns, and let the bots answer those questions in Slack so that the humans can focus on delivering real value.
Acryl Data provides DataHub as an easy to consume SaaS product which has been adopted by several companies. Signup for the SaaS product at dataengineeringpodcast.com/acryl RudderStack helps you build a customer data platform on your warehouse or datalake. Stop struggling to speed up your datalake.
The terms “ Data Warehouse ” and “ DataLake ” may have confused you, and you have some questions. Structuring data refers to converting unstructured data into tables and defining data types and relationships based on a schema. Data Warehouse in DBMS: . What is DataLake? .
It’s not always the most accurate indicator, but a quick glance at google trends sees Data Engineer rocketing in popularity, compared to more traditional functions such as BI and ETL Developer: google trends Now, that’s not saying that the other roles are going away, not by a long stretch.
Trusted by the data teams at Fox, JetBlue, and PagerDuty, Monte Carlo solves the costly problem of broken data pipelines. Monte Carlo also gives you a holistic picture of data health with automatic, end-to-end lineage from ingestion to the BI layer directly out of the box.
Trusted by the data teams at Fox, JetBlue, and PagerDuty, Monte Carlo solves the costly problem of broken data pipelines. Monte Carlo also gives you a holistic picture of data health with automatic, end-to-end lineage from ingestion to the BI layer directly out of the box.
Shifting left involves moving data processing upstream, closer to the source, enabling broader access to high-quality data through well-defined data products and contracts, thus reducing duplication, enhancing data integrity, and bridging the gap between operational and analytical data domains.
When it comes to the data community, there’s always a debate broiling about something— and right now “data mesh vs datalake” is right at the top of that list. In this post we compare and contrast the data mesh vs datalake to illustrate the benefits of each and help discover what’s right for your data platform.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
In 2010, a transformative concept took root in the realm of data storage and analytics — a datalake. The term was coined by James Dixon , Back-End Java, Data, and BusinessIntelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data.
Cloudera customers run some of the biggest datalakes on earth. These lakes power mission critical large scale data analytics, businessintelligence (BI), and machine learning use cases, including enterprise data warehouses. On data warehouses and datalakes.
Summary When your data lives in multiple locations, belonging to at least as many applications, it is exceedingly difficult to ask complex questions of it. The default way to manage this situation is by crafting pipelines that will extract the data from source systems and load it into a datalake or data warehouse.
That’s why it’s essential for teams to choose the right architecture for the storage layer of their data stack. But, the options for data storage are evolving quickly. Different vendors offering data warehouses, datalakes, and now data lakehouses all offer their own distinct advantages and disadvantages for data teams to consider.
A robust data infrastructure is a must-have to compete in the F1 business. We’ll build a data architecture to support our racing team starting from the three canonical layers : DataLake, Data Warehouse, and Data Mart. Looker, PowerBI, Tableau, ThoughtSpot, …) and data pipelines tools.
Many of the existing visual businessintelligence and dashboard tools also use SQL as a standard language. Democratizing data refers to a mechanism that provides a self-serve paradigm and culture for an ever-growing internal audience to get the data they need to add value to the business.
Push information about data freshness and quality to your businessintelligence, automatically scale up and down your warehouse based on usage patterns, and let the bots answer those questions in Slack so that the humans can focus on delivering real value.
Over the past decade, Cloudera has enabled multi-function analytics on datalakes through the introduction of the Hive table format and Hive ACID. Companies, on the other hand, have continued to demand highly scalable and flexible analytic engines and services on the datalake, without vendor lock-in.
Imagine being in charge of creating an intelligentdata universe where collaboration, analytics, and artificial intelligence all work together harmoniously. That’s what a Microsoft Fabric Engineer does.
In the same way that application performance monitoring ensures reliable software and keeps application downtime at bay, Monte Carlo solves the costly problem of broken data pipelines. Go to dataengineeringpodcast.com/montecarlo and start trusting your data with Monte Carlo today!
Acryl Data provides DataHub as an easy to consume SaaS product which has been adopted by several companies. Signup for the SaaS product at dataengineeringpodcast.com/acryl RudderStack helps you build a customer data platform on your warehouse or datalake.
Fortunately, there’s hope: in the same way that New Relic, DataDog, and other Application Performance Management solutions ensure reliable software and keep application downtime at bay, Monte Carlo solves the costly problem of broken data pipelines.
Change Data Capture (CDC) has emerged as an ideal solution for near real-time movement of data from relational databases (like SQL Server or Oracle) to data warehouses, datalakes or other databases. What is Change Data Capture?
Push information about data freshness and quality to your businessintelligence, automatically scale up and down your warehouse based on usage patterns, and let the bots answer those questions in Slack so that the humans can focus on delivering real value.
The pathway from ETL to actionable analytics can often feel disconnected and cumbersome, leading to frustration for data teams and long wait times for business users. And even when we manage to streamline the data workflow, those insights aren’t always accessible to users unfamiliar with antiquated businessintelligence tools.
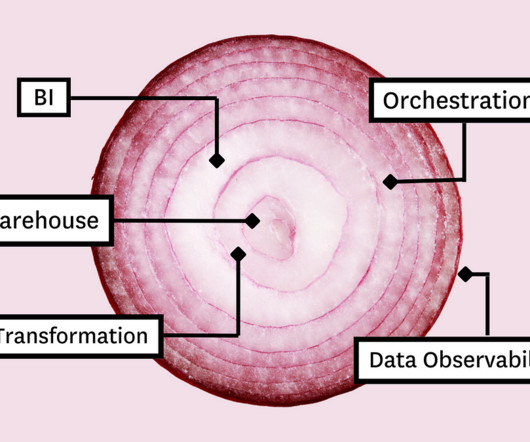
In this article, we’ll present you with the Five Layer Data Stack — a model for platform development consisting of five critical tools that will not only allow you to maximize impact but empower you to grow with the needs of your organization. Before you can model the data for your stakeholders, you need a place to collect and store it.
In the same way that application performance monitoring ensures reliable software and keeps application downtime at bay, Monte Carlo solves the costly problem of broken data pipelines. Start trusting your data with Monte Carlo today! Start trusting your data with Monte Carlo today!
In the same way that application performance monitoring ensures reliable software and keeps application downtime at bay, Monte Carlo solves the costly problem of broken data pipelines. Start trusting your data with Monte Carlo today! Start trusting your data with Monte Carlo today!
In the same way that application performance monitoring ensures reliable software and keeps application downtime at bay, Monte Carlo solves the costly problem of broken data pipelines. Start trusting your data with Monte Carlo today! Start trusting your data with Monte Carlo today!
In the same way that application performance monitoring ensures reliable software and keeps application downtime at bay, Monte Carlo solves the costly problem of broken data pipelines. Start trusting your data with Monte Carlo today! Start trusting your data with Monte Carlo today!
In the same way that application performance monitoring ensures reliable software and keeps application downtime at bay, Monte Carlo solves the costly problem of broken data pipelines. Start trusting your data with Monte Carlo today! Start trusting your data with Monte Carlo today!
In the same way that application performance monitoring ensures reliable software and keeps application downtime at bay, Monte Carlo solves the costly problem of broken data pipelines. Start trusting your data with Monte Carlo today! Start trusting your data with Monte Carlo today!
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content