This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
But theyre only as good as the data they rely on. If the underlying data is incomplete, inconsistent, or delayed, even the most advanced AI models and businessintelligence systems will produce unreliable insights. Heres why: AI Models Require Clean Data: Machine learning models are only as good as their training data.
Datapipelines are the backbone of your business’sdata architecture. Implementing a robust and scalable pipeline ensures you can effectively manage, analyze, and organize your growing data. We’ll answer the question, “What are datapipelines?” Table of Contents What are DataPipelines?
Data Aggregation Data aggregation is a powerful technique that involves compiling data from various sources to provide a comprehensive view. This process is crucial for generating summary statistics, such as averages, sums, and counts, which are essential for businessintelligence and analytics.
Push information about data freshness and quality to your businessintelligence, automatically scale up and down your warehouse based on usage patterns, and let the bots answer those questions in Slack so that the humans can focus on delivering real value. Unstruk is the DataOps platform for your unstructured data.
Push information about data freshness and quality to your businessintelligence, automatically scale up and down your warehouse based on usage patterns, and let the bots answer those questions in Slack so that the humans can focus on delivering real value. Tired of deploying bad data? Tired of deploying bad data?
A well-executed datapipeline can make or break your company’s ability to leverage real-time insights and stay competitive. Thriving in today’s world requires building modern datapipelines that make moving data and extracting valuable insights quick and simple. What is a DataPipeline?
Fortunately, there’s hope: in the same way that New Relic, DataDog, and other Application Performance Management solutions ensure reliable software and keep application downtime at bay, Monte Carlo solves the costly problem of broken datapipelines. The first 25 will receive a free, limited edition Monte Carlo hat!
Push information about data freshness and quality to your businessintelligence, automatically scale up and down your warehouse based on usage patterns, and let the bots answer those questions in Slack so that the humans can focus on delivering real value. Unstruk is the DataOps platform for your unstructured data.
If you’re a data engineering podcast listener, you get credits worth $3000 on an annual subscription Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold. Struggling with broken pipelines?
If you’re a data engineering podcast listener, you get credits worth $3000 on an annual subscription Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold. Struggling with broken pipelines?
Push information about data freshness and quality to your businessintelligence, automatically scale up and down your warehouse based on usage patterns, and let the bots answer those questions in Slack so that the humans can focus on delivering real value. Tired of deploying bad data? Tired of deploying bad data?
Push information about data freshness and quality to your businessintelligence, automatically scale up and down your warehouse based on usage patterns, and let the bots answer those questions in Slack so that the humans can focus on delivering real value. Unstruk is the DataOps platform for your unstructured data.
But is there more to generative AI than a fancy demo on Twitter? And how will it impact data? How generative AI will disrupt data With the advent of OpenAI’s DALL-E and ChatGPT, large language models became much more useful to the vast majority of humans. Request a demo today. Let’s assess. Will you join us?
Push information about data freshness and quality to your businessintelligence, automatically scale up and down your warehouse based on usage patterns, and let the bots answer those questions in Slack so that the humans can focus on delivering real value. Tired of deploying bad data? Tired of deploying bad data?
Data engineering excellence Modern offers robust solutions for building, managing, and operationalizing datapipelines. This capability is instrumental in meeting the analytical demands of various data applications, including analytics, businessintelligence (ABI), and data science.
Fortunately, there’s hope: in the same way that New Relic, DataDog, and other Application Performance Management solutions ensure reliable software and keep application downtime at bay, Monte Carlo solves the costly problem of broken datapipelines. The first 25 will receive a free, limited edition Monte Carlo hat!
Fortunately, there’s hope: in the same way that New Relic, DataDog, and other Application Performance Management solutions ensure reliable software and keep application downtime at bay, Monte Carlo solves the costly problem of broken datapipelines. The first 25 will receive a free, limited edition Monte Carlo hat!
Push information about data freshness and quality to your businessintelligence, automatically scale up and down your warehouse based on usage patterns, and let the bots answer those questions in Slack so that the humans can focus on delivering real value. Data teams are increasingly under pressure to deliver.
Data engineering excellence Modern offers robust solutions for building, managing, and operationalizing datapipelines. This capability is instrumental in meeting the analytical demands of various data applications, including analytics, businessintelligence (ABI), and data science.
Simultaneously, Monte Carlo provides CDOs and other data stakeholders with a holistic view of their company’s data health and reliability across critical business use cases. We are delighted to partner with Monte Carlo for their data observability capabilities,” said Tarik Dwiek, Director of Technology Alliances at Snowflake.
Today, I’m excited to announce Monte Carlo’s new Fivetran integration , giving mutual customers the ability to accelerate data incident detection and resolution by adding monitoring to datapipelines at the point of creation.
Today, I’m excited to announce Monte Carlo’s new Fivetran integration , giving mutual customers the ability to accelerate data incident detection and resolution by adding monitoring to datapipelines at the point of creation.
For Blinkist , a global book insights subscription service, broken datapipelines led to unreliable marketing spend, costly data fire drills, and loss of executive trust. When COVID-19 hit, they realized the growth of their company was being hindered by bad data. Talk to us! Request a free trial!
Datapipelines are messy. Data engineering design patterns are repeatable solutions that help you structure, optimize, and scale data processing, storage, and movement. They make data workflows more resilient and easier to manage when things inevitably go sideways. Enter your email to schedule a demo.
It often includes data marts (subsets of the data warehouse focused on specific business areas) and Online Analytical Processing cubes to support specific business functions. This layer is the primary interface for BusinessIntelligence tools that generate insights.
Help customers visualize their data using a businessintelligence tool. Inspyrus used Striim to seamlessly integrate customer data from various ERP and accounting systems into its Snowflake cloud data warehouse. Request a demo today.
In this post, we’ll dive into the world of data ownership, exploring how this new breed of professionals is shaping the future of businessintelligence and why, in the coming years, the success of your data strategy may hinge on the effectiveness of your data owners. Table of Contents What is a Data Owner?
What Databricks is used for Use cases for Databricks are as diverse and numerous as the types of data and the range of tools and operations it supports. Watch our video to learn more about one of the key Databricks applications — data engineering. All messages to and from the control plane are encrypted in transit.
Operations and analytics teams are increasingly leveraging this new approach to pipe transformed data from their cloud data warehouses into their CRMs (like Salesforce), marketing automation tools, advertising platforms, customer support and ticketing systems, and, of course, Slack. Image courtesy of Monte Carlo.
Incident IQ gives data engineers and analysts a centralized, all-in-one solution for conducting incident management and root cause analysis on your datapipelines. Be sure to check out our Live Product Demo on July 15, 2021 at 12:00 p.m. Video courtesy of Monte Carlo. EST / 9:00 a.m. PST to learn more.
On average, companies lose over $15 million per year on bad data, with data engineers spending upwards of 40 percent – or 120 hours per week – of their time tackling broken datapipelines. Be sure to check out our Live Product Demo on July 15, 2021 at 12:00 p.m. EST / 9:00 a.m.
To achieve this, combine data from the sum of your sources. For this purpose, you can use ETL (extract, transform, and load) tools or build a custom datapipeline of your own and send the aggregated data to a target system, such as a data warehouse. Sign up for a demo today.
To make a more informed decision, enquire about demos and do your own in-depth research. Oracle Data Integrator, IBM InfoSphere, Snaplogic, Xplenty, and. The toolkit allows you to quickly build datapipelines , automate integration tasks, and monitor jobs. Here, we’ll be comparing such vendors as. Talend Open Studio.
Gen AI can whip up serviceable code in moments — making it much faster to build and test datapipelines. Today’s LLMs can already process enormous amounts of unstructured data, automating much of the monotonous work of data science. But what does that mean for the roles of data engineers and data scientists going forward?
How should your businessintelligence improve as a result of this migration? Set your budget While you’ll likely save on a data warehouse migration to cloud tooling, the migration process will create costs of its own. This can either be built manually or through datapipeline services like Fivetran.
So, why does anyone need to integrate data in the first place? Today, companies want their business decisions to be driven by data. But here’s the thing — information required for businessintelligence (BI) and analytics processes often lives in a breadth of databases and applications.
Overwhelmed data engineers need to have the proper context of the blast radius to understand which incidents need to be addressed right away, and which incidents are a secondary priority. This is one of the most frequent data lineage use cases leveraged by Vox.
This post highlights exactly how our founders taught us to think differently about data and why it matters. Here are the cornerstones of this new paradigm: Data ownership is a construct Datapipelines should be accessible to everyone Data products should adapt to the organization, not vice versa.
Operational analytics, a subset of business analytics, focuses on improving and optimizing daily operations within an organization. To ensure effective implementation, decision services must access all existing data infrastructure components, such as data warehouses, BI tools, and real-time datapipelines.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























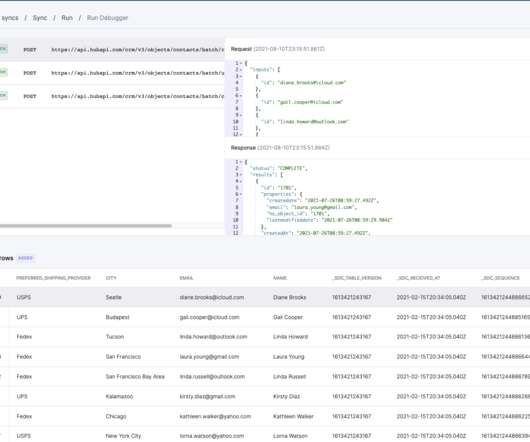







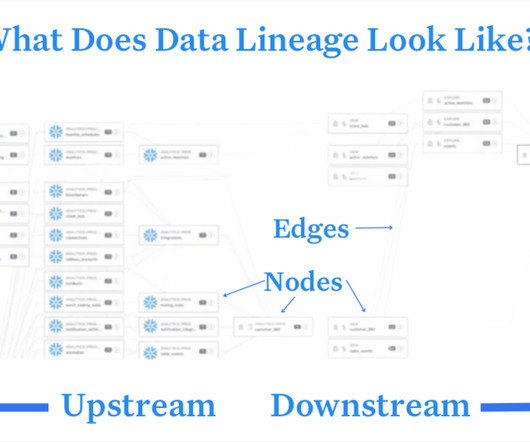

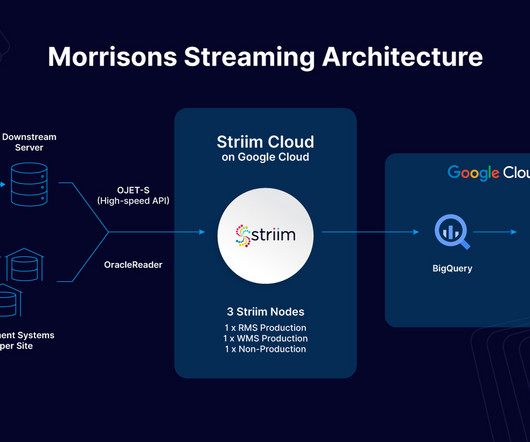






Let's personalize your content