This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
But theyre only as good as the data they rely on. If the underlying data is incomplete, inconsistent, or delayed, even the most advanced AI models and businessintelligence systems will produce unreliable insights. Heres why: AI Models Require Clean Data: Machine learning models are only as good as their training data.
The article advocates for a "shift left" approach to data processing, improving data accessibility, quality, and efficiency for operational and analytical use cases. link] Get Your Guide: From Snowflake to Databricks: Our cost-effective journey to a unified data warehouse.
Build vs buy orchestration tooling Unlike the other components we’ve discussed in Part 3, datapipelines don’t require orchestration to be considered functional—at least not at a foundational level. And data orchestration tools are generally easy to stand-up for initial use-cases. Missed Nishith’s 5 considerations?
It closely follows the best practices of DevOps although the implementation of DataOps to data is nothing like DevOps to code. This paper will focus on providing a prescriptive approach in implementing a datapipeline using a DataOps discipline for data practitioners.
By automating many of the processes involved in dataquality management, dataquality platforms can help organizations reduce errors, streamline workflows, and make better use of their data assets. This functionality is critical for not only fixing current issues but also preventing future ones.
By adopting a set of best practices inspired by Agile methodologies, DevOps principles, and statistical process control techniques, DataOps helps organizations deliver high-qualitydata insights more efficiently.
And the desire to leverage those technologies for analytics, machine learning, or businessintelligence (BI) has grown exponentially as well. We optimize these products for use cases and architectures that will remain business-critical for years to come. What does all this mean for your business? Bigger, better results.
This proactive approach to dataquality guarantees that downstream analytics and business decisions are based on reliable, high-qualitydata, thereby mitigating the risks associated with poor dataquality. There are multiple locations where problems can happen in a data and analytic system.
Data is a priority for your CEO, as it often is for digital-first companies, and she is fluent in the latest and greatest businessintelligence tools. What about a frantic email from your CTO about “duplicate data” in a businessintelligence dashboard?
And with so many data teams across functions, how does Fox approach data governance? Table of Contents Solve data silos starting at the people-level Keep data governance approachable Oliver Gomes’ data governance best practices Manage and promote the value of high-qualitydata How will Generative AI impact dataquality at Fox?
Is it possible to treat data not just as a necessary operational output, but as a product that holds immense strategic value? Treating data as a product is more than a concept; it’s a paradigm shift that can significantly elevate the value that businessintelligence and data-centric decision-making have on the business.
The ACE comprises all types of data contributors, from analytics engineers to data engineers to businessintelligence analysts, who collaborate to help the business make more strategic decisions using data. The platform has introduced a host of other data-related possibilities. Quick time to value 2.
while overlooking or failing to understand what it really takes to make their tools — and, ultimately, their data initiatives — successful. When it comes to driving impact with your data, you first need to understand and manage that data’squality. learn when and why data may be down.
In fact, according to Gartner , dataquality issues cost organizations an average of $12.9 From businessintelligence to machine learning, reliable data is the lifeblood of your data products. Bad data in—bad data products out. And that puts dataquality at the top of every CTO’s priority list.
Data informs every business decision, from customer support to feature development, and most recently, how to support pricing plans for organizations most affected during COVID-19. When migrating to Snowflake, PagerDuty wanted to understand the health of their datapipelines through fully automated data observability.
Gen AI can whip up serviceable code in moments — making it much faster to build and test datapipelines. Today’s LLMs can already process enormous amounts of unstructured data, automating much of the monotonous work of data science. Those who don’t embrace it will be left behind. With the right prompt (this is key!),
For the past few decades, most companies have kept data in an organizational silo. Analytics teams served business units, and even as data became more crucial to decision-making and product roadmaps, the teams in charge of datapipelines were treated more like plumbers and less like partners.
Summary The purpose of businessintelligence systems is to allow anyone in the business to access and decode data to help them make informed decisions. The team at Zenlytic have leaned on the promise of large language models to build an AI agent that lets you converse with your data.
Data Warehouse (Or Lakehouse) Migration 34. Integrate Data Stacks Post Merger 35. Know When To Fix Vs. Refactor DataPipelines Improve DataOps Processes 37. Analyze Data Incident Impact and Triage 39. Transition To A Data Mesh (Or Other Data Team Structure) 40. Prioritize Data Assets And Efforts 41.
Data warehouse (or Lakehouse) migration 34. Integrate Data Stacks Post Merger 35. Know When To Fix Vs. Refactor DataPipelines Improve DataOps Processes 37. Analyze Data Incident Impact and Triage 39. Transition To A Data Mesh (Or Other Data Team Structure) 40. Prioritize Data Assets And Efforts 41.
Modern data engineering can help with this. It creates the systems and processes needed to gather, clean, transfer, and prepare data for AI models. Without it, AI technologies wouldn’t have access to high-qualitydata. Au tomation in modern data engineering has a new dimension.
Operational analytics, a subset of business analytics, focuses on improving and optimizing daily operations within an organization. To ensure effective implementation, decision services must access all existing data infrastructure components, such as data warehouses, BI tools, and real-time datapipelines.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













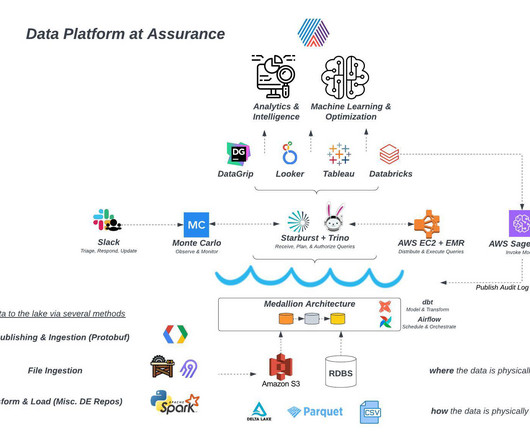
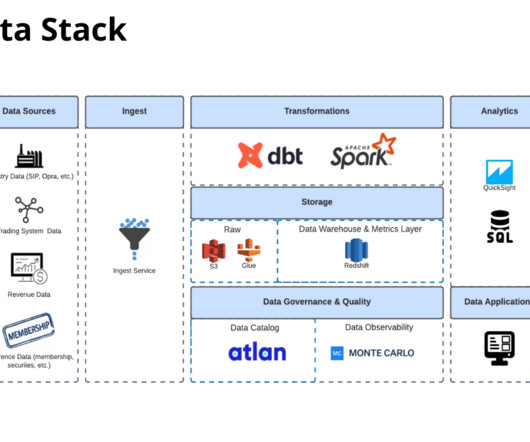



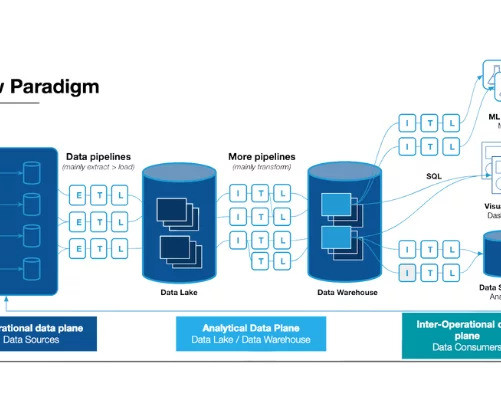




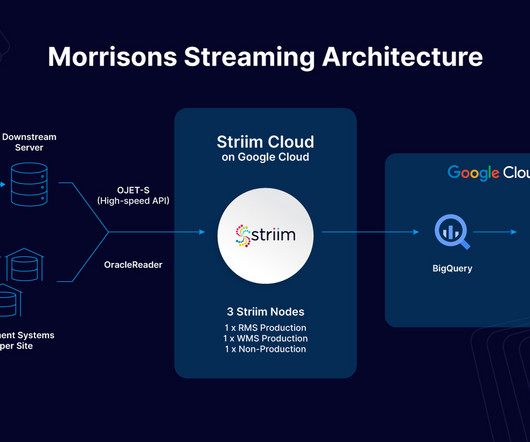






Let's personalize your content