This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
I joined Facebook in 2011 as a businessintelligence engineer. By the time I left in 2013, I was a data engineer. Instead, Facebook came to realize that the work we were doing transcended classic businessintelligence. Let’s highlight the fact that the abstractions exposed by traditional ETLtools are off-target.
Tableau is a robust BusinessIntelligencetool that helps users visualize data simply and elegantly. Tableau has helped numerous organizations understand their customer data better through their Visual Analytics platform.
Data Aggregation Data aggregation is a powerful technique that involves compiling data from various sources to provide a comprehensive view. This process is crucial for generating summary statistics, such as averages, sums, and counts, which are essential for businessintelligence and analytics.
The strategic, tactical, and operational business decisions of a company are directly impacted by Businessintelligence. BI encourages using historical data to promote fact-based decision-making instead of assumptions and intuition. What is BusinessIntelligence (BI)?
Also, data analysts have a thorough comprehension of statistical ideas and methods. Data Engineer vs Data Analyst: General Requirements Data Engineers must have experience with ETLtools, data warehousing, data modeling, data pipelines, and cloud computing.
Summary Applications of data have grown well beyond the venerable businessintelligence dashboards that organizations have relied on for decades. What are the core principles of data engineering that have remained from the original wave of ETLtools and rigid datawarehouses?
I’d like to discuss some popular Data engineering questions: Modern data engineering (DE). Does your DE work well enough to fuel advanced data pipelines and Businessintelligence (BI)? Are your data pipelines efficient? Often it is a datawarehouse solution (DWH) in the central part of our infrastructure.
Thus, to build a career in Data Science, you need to be familiar with how the business operates, its business model, strategies, problems, and challenges. Data Science Roles As Data Science is a broad field, you will find multiple different roles with different responsibilities.
Such visualizations as graphs and charts are typically prepared by data analysts or business analysts, though not every project has those people employed. Then, a data scientist uses complex businessintelligencetools to present business insights to executives. Managing data and metadata.
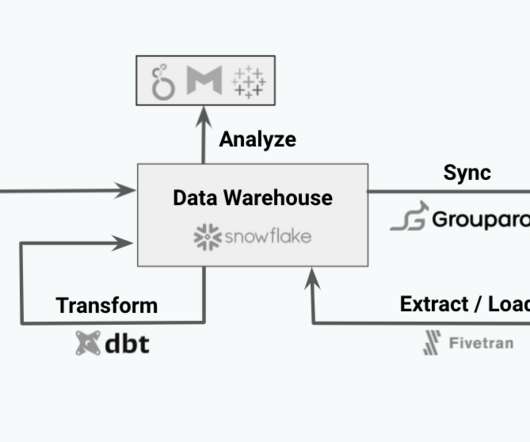
The Modern Data Stack is a recent development in the data engineering space. The core enabler of the Modern Data Stack is that datawarehouse technologies such as Snowflake, BigQuery, and Redshift have gotten fast enough and cheap enough to be considered the source of truth for many businesses.
Instead of combing through the vast amounts of all organizational data stored in a datawarehouse, you can use a data mart — a repository that makes specific pieces of data available quickly to any given business unit. What is a data mart? Data mart vs datawarehouse vs data lake vs OLAP cube.
Over the past few years, data-driven enterprises have succeeded with the Extract Transform Load (ETL) process to promote seamless enterprise data exchange. This indicates the growing use of the ETL process and various ETLtools and techniques across multiple industries.
Secondly , the rise of data lakes that catalyzed the transition from ELT to ELT and paved the way for niche paradigms such as Reverse ETL and Zero-ETL. Still, these methods have been overshadowed by EtLT — the predominant approach reshaping today’s data landscape.
Cloud datawarehouses solve these problems. Belonging to the category of OLAP (online analytical processing) databases, popular datawarehouses like Snowflake, Redshift and Big Query can query one billion rows in less than a minute. What is a datawarehouse?
It is the process of extracting data from various sources, transforming it into a format suitable for analysis, and loading it into a target database or datawarehouse. ETL is used to integrate data from different sources and formats into a single target for analysis. What is an ETL Pipeline?
Modern data teams have all the right solutions in place to ensure that data is ingested, stored, transformed, and loaded into their datawarehouse, but what happens at “the last mile?” In other words, how can data analysts and engineers ensure that transformed, actionable data is actually available to access and use?
If you encounter Big Data on a regular basis, the limitations of the traditional ETLtools in terms of storage, efficiency and cost is likely to force you to learn Hadoop. Having said that, the data professionals cannot afford to rest on their existing expertise of one or more of the ETLtools.
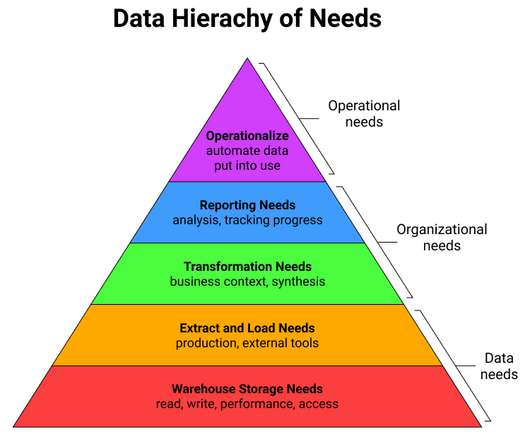
Warehouse Storage Needs The foundation of Maslow’s hierarchy of needs is about physiological needs like having enough food, water, and sleep. In the world of the modern data stack, the parallel is having a datawarehouse that can act as a foundation for the work to be done. It can certainly be quite challenging.
Organizations collect and leverage data on an ever-expanding basis to inform businessintelligence and optimize practices. Data allows businesses to gain a greater understanding of their suppliers, customers, and internal processes. Read more about our Reverse ETLTools. featured image via unsplash
The technology was written in Java and Scala in LinkedIn to solve the internal problem of managing continuous data flows. A publisher (say, telematics or Internet of Medical Things system) produces data units, also called events or messages , and directs them not to consumers but to a middleware platform — a broker.
What is Databricks Databricks is an analytics platform with a unified set of tools for data engineering, data management , data science, and machine learning. It combines the best elements of a datawarehouse, a centralized repository for structured data, and a data lake used to host large amounts of raw data.
CSP was recently recognized as a leader in the 2022 GigaOm Radar for Streaming Data Platforms report. Reduce ingest latency and complexity: Multiple point solutions were needed to move data from different data sources to downstream systems. Better yet, it works in any cloud environment.
Introduction Amazon Redshift, a cloud datawarehouse service from Amazon Web Services (AWS), will directly query your structured and semi-structured data with SQL. Amazon Redshift is a petabyte-scale service that allows you to analyze all your data using SQL and your favorite businessintelligence (BI) tools.
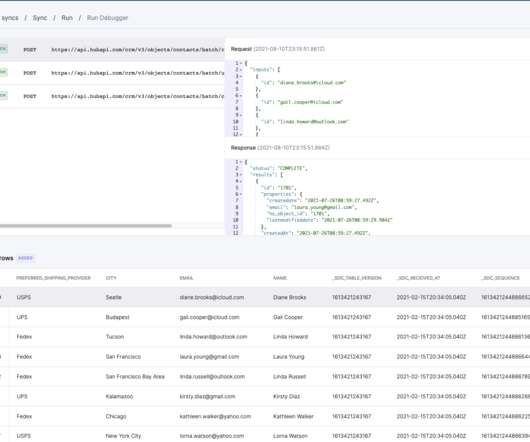
The integration with Fivetran is the latest step in Monte Carlo’s mission to bring end-to-end data observability for customers across their data stack.
The integration with Fivetran is the latest step in Monte Carlo’s mission to bring end-to-end data observability for customers across their data stack.
If we take the more traditional approach to data-related jobs used by larger companies, there are different specialists doing narrowly-focused tasks on different sides of the project. Data engineers build data pipelines and perform ETL — extract data from sources, transform it, and load it into a centralized repository like a datawarehouse.
In 2010, a transformative concept took root in the realm of data storage and analytics — a data lake. The term was coined by James Dixon , Back-End Java, Data, and BusinessIntelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data.
Introduction Most data modeling approaches for customer segmentation are based on a wide table with user attributes. This table only stores the current attributes for each user, and is then loaded into the various SaaS platforms via Reverse ETLtools.
Support Data Streaming: Build systems that allow the flow of required data seamlessly in real-time for analysis. Implement analytics systems: Install and tune such systems for analytics and businessintelligence operations. Create Business Reports: Formulate reports that will be helpful in deciding company advisors.
This data can be structured, semi-structured, or entirely unstructured, making it a versatile tool for collecting information from various origins. The extracted data is then duplicated or transferred to a designated destination, often a datawarehouse optimized for Online Analytical Processing (OLAP).
Data integration defines the process of collecting data from a number of disparate source systems and presenting it in a unified form within a centralized location like a datawarehouse. So, why is data integration such a big deal? Connections to both datawarehouses and data lakes are possible in any case.
Why is ETL used in Data Science? ETL stands for Extract, Transform, and Load. It entails gathering data from numerous sources, converting it, and then storing it in a new single datawarehouse. ETL pipelines help data scientists to prepare data for analytics and businessintelligence.
Data integration is the process of taking data from multiple disparate internal and external sources and putting it in a single location (e.g., datawarehouse ) to achieve a unified view of collected data. So, why does anyone need to integrate data in the first place? Key types of data integration.
Generally, data pipelines are created to store data in a datawarehouse or data lake or provide information directly to the machine learning model development. Keeping data in datawarehouses or data lakes helps companies centralize the data for several data-driven initiatives.
Zero-Code Development Life Cycle (ZDLC) is the recognition that Matillion for Snowflake is a new breed of ETLtool that allows a full spectrum of users and use cases to operate concurrently on the same platform for the same organization. This is often called CURATED, or REPORT, or even DATAWAREHOUSE.
You shall know database creation, data manipulation, and similar operations on the data sets. Data Warehousing: Datawarehouses store massive pieces of information for querying and data analysis. Your organization will use internal and external sources to port the data. Don’t Mention Every Tool.
The process of data modeling begins with stakeholders providing business requirements to the data engineering team. Prepare for Your Next Big Data Job Interview with Kafka Interview Questions and Answers How is a datawarehouse different from an operational database? Data is regularly updated.
Operational analytics, a subset of business analytics, focuses on improving and optimizing daily operations within an organization. Acquire the Necessary Tools The foundation of operational analytics lies in having the right tools to handle diverse data sources and deliver real-time insights.
That's where the ETL (Extract, Transform, and Load) pipeline comes into the picture! Table of Contents What is ETL Pipeline? First, we will start with understanding the Data pipelines with a straightforward layman's example. Now let us try to understand ETLdata pipelines in more detail.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content