

Data Integrity for AI: What’s Old is New Again
Precisely
JANUARY 9, 2025
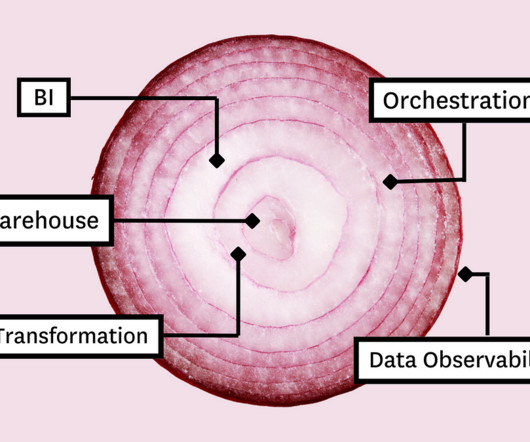
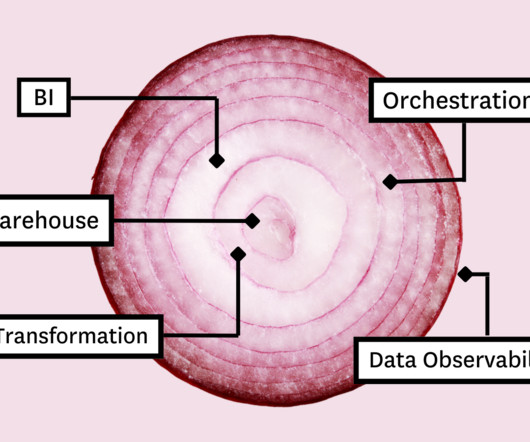
The goal of this post is to understand how data integrity best practices have been embraced time and time again, no matter the technology underpinning. In the beginning, there was a data warehouse The data warehouse (DW) was an approach to data architecture and structured data management that really hit its stride in the early 1990s.










































Let's personalize your content