This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The goal of this post is to understand how data integrity best practices have been embraced time and time again, no matter the technology underpinning. In the beginning, there was a datawarehouse The datawarehouse (DW) was an approach to data architecture and structured data management that really hit its stride in the early 1990s.
BusinessIntelligence and Artificial Intelligence are popular technologies that help organizations turn raw data into actionable insights. While both BI and AI provide data-driven insights, they differ in how they help businesses gain a competitive edge in the data-driven marketplace.
The volume of enterprise data generated, including structured data, sensor data, network logs, video and audio feeds, and other unstructureddata, is expanding exponentially as businesses diversify their client bases and adopt new technologies. Who is a DataWarehouse Engineer?
Are you looking to choose the best cloud datawarehouse for your next big data project? This blog presents a detailed comparison of two of the very famous cloud warehouses - Redshift vs. BigQuery - to help you pick the right solution for your data warehousing needs. billion by 2028 from $21.18
Today, businesses use traditional datawarehouses to centralize massive amounts of raw data from business operations. Amazon Redshift is helping over 10000 customers with its unique features and data analytics properties. Table of Contents AWS Redshift DataWarehouse Architecture 1. Clusters 3.
Data is often referred to as the new oil, and just like oil requires refining to become useful fuel, data also needs a similar transformation to unlock its true value. This transformation is where data warehousing tools come into play, acting as the refining process for your data. Why Choose a Data Warehousing Tool?
Before we dive further into the comparison between ETL developers and other data industry job titles, let us first understand what is an ETL developer, what are the necessary skills and responsibilities associated with the role, etc. Begin simply by loading a sample dataset from a Kaggle competition into a datawarehouse as a starting point.
Over the years, the technology landscape for data management has given rise to various architecture patterns, each thoughtfully designed to cater to specific use cases and requirements. These patterns include both centralized storage patterns like datawarehouse , data lake and data lakehouse , and distributed patterns such as data mesh.
Learn to Interact with the DBMS Systems Many companies keep their datawarehouses far from the stations where data can be accessed. The role of a data engineer is to use tools for interacting with the database management systems. for working on cloud datawarehouses.
Decide the process of Data Extraction and transformation, either ELT or ETL (Our Next Blog) Transforming and cleaning data to improve data reliability and usage ability for other teams from Data Science or Data Analysis. Dealing With different data types like structured, semi-structured, and unstructureddata.
Top ETL Business Use Cases for Streamlining Data Management Data Quality - ETL tools can be used for data cleansing, validation, enriching, and standardization before loading the data into a destination like a data lake or datawarehouse.
Google BigQuery BigQuery is a fully-managed, serverless cloud datawarehouse by Google. It facilitates business decisions using data with a scalable, multi-cloud analytics platform. Additionally, it has excellent machine learning and businessintelligence capabilities.
Push information about data freshness and quality to your businessintelligence, automatically scale up and down your warehouse based on usage patterns, and let the bots answer those questions in Slack so that the humans can focus on delivering real value. Unstruk is the DataOps platform for your unstructureddata.
Data volume and velocity, governance, structure, and regulatory requirements have all evolved and continue to. Despite these limitations, datawarehouses, introduced in the late 1980s based on ideas developed even earlier, remain in widespread use today for certain businessintelligence and data analysis applications.
Push information about data freshness and quality to your businessintelligence, automatically scale up and down your warehouse based on usage patterns, and let the bots answer those questions in Slack so that the humans can focus on delivering real value. Unstruk is the DataOps platform for your unstructureddata.
Two popular approaches that have emerged in recent years are datawarehouse and big data. While both deal with large datasets, but when it comes to datawarehouse vs big data, they have different focuses and offer distinct advantages.
Amazon, which generates massive volumes of data daily, faced this exact challenge. Extracting, transforming, and loading (ETL) data from their transactional databases into datawarehouses like Redshift slowed their analytics, delaying crucial business decisions.
BusinessIntelligence (BI) comprises a career field that supports organizations to make driven decisions by offering valuable insights. BusinessIntelligence is closely knitted to the field of data science since it leverages information acquired through large data sets to deliver insightful reports.
It can also access structured and unstructureddata from various sources. As a result, it must combine with other cloud-based data platforms, if not HDFS. Spark Projects for Data Engineers Learn to Write Spark Applications using Spark 2.0 Apache Hive Apache Hive is a Hadoop-based datawarehouse and management tool.
Ready to take your big data analysis to the next level? Check out this comprehensive tutorial on BusinessIntelligence on Hadoop and unlock the full potential of your data! million terabytes of data are generated daily. Table of Contents Why BusinessIntelligence On Hadoop?
A data mart is a cost-effective solution to efficiently acquire meaningful insights since it only comprises data relevant to a specific business area. It's a top-down method that starts with storing all enterprise data in a single area, then extracting a well-defined piece of the data when it's time to analyze it.
The terms “ DataWarehouse ” and “ Data Lake ” may have confused you, and you have some questions. Structuring data refers to converting unstructureddata into tables and defining data types and relationships based on a schema. What is DataWarehouse? .
BusinessIntelligence and Artificial Intelligence are popular technologies that help organizations turn raw data into actionable insights. While both BI and AI provide data-driven insights, they differ in how they help businesses gain a competitive edge in the data-driven marketplace.
Focus on Needs Over Nomenclature : Define the outcomes you want from your analytics team instead of getting caught up in the semantics of terms like analytics, data science, and businessintelligence. The Three C’s of Analytics : Emphasize data creation, curation, and consumption.
Check out this ultimate guide to explore the fascinating world of ETL with Python and discover why it's the top choice for modern data enthusiasts. Python ETL really empowers you to transform data like a pro. ETL, which stands for Extract, Transform, Load, is a crucial process in data integration and data warehousing.
In broader terms, two types of data -- structured and unstructureddata -- flow through a data pipeline. The structured data comprises data that can be saved and retrieved in a fixed format, like email addresses, locations, or phone numbers. What is a Big Data Pipeline?
Push information about data freshness and quality to your businessintelligence, automatically scale up and down your warehouse based on usage patterns, and let the bots answer those questions in Slack so that the humans can focus on delivering real value. Unstruk is the DataOps platform for your unstructureddata.
Relational Database Management Systems (RDBMS) Non-relational Database Management Systems Relational Databases primarily work with structured data using SQL (Structured Query Language). SQL works on data arranged in a predefined schema. Non-relational databases support dynamic schema for unstructureddata.
Different vendors offering datawarehouses, data lakes, and now data lakehouses all offer their own distinct advantages and disadvantages for data teams to consider. So let’s get to the bottom of the big question: what kind of data storage layer will provide the strongest foundation for your data platform?
Push information about data freshness and quality to your businessintelligence, automatically scale up and down your warehouse based on usage patterns, and let the bots answer those questions in Slack so that the humans can focus on delivering real value. images, documents, etc.)
Transform- Data is validated, cleaned, and modified in the staging area so that you can integrate it with a target system. Load- Finally, you can store the data in a datawarehouse or other storage systems. ELT involves three core stages- Extract- Importing data from the source server is the initial stage in this process.
With the global cloud data warehousing market likely to be worth $10.42 billion by 2026, cloud data warehousing is now more critical than ever. Cloud datawarehouses offer significant benefits to organizations, including faster real-time insights, higher scalability, and lower overhead expenses.
An ETL (Extract, Transform, Load) Data Engineer is responsible for designing, building, and maintaining the systems that extract data from various sources, transform it into a format suitable for data analysis, and load it into datawarehouses, lakes, or other data storage systems.
It is popular for its versatility and ease of use, making it suitable for batch and streaming data ingestion scenarios. Learn more about how NiFi helps ingest real-time data efficiently by working on this Real-Time Streaming of Twitter Sentiments AWS EC2 NiFi Project.
In an era of digital transformation of enterprises, there are several questions that have arisen- How can businessintelligence provide real time insights? How can businessintelligence scale and analyse the growing data heap? How can businessintelligence meet changing business needs?
A robust data infrastructure is a must-have to compete in the F1 business. We’ll build a data architecture to support our racing team starting from the three canonical layers : Data Lake, DataWarehouse, and Data Mart. Data Marts There is a thin line between DataWarehouses and Data Marts.
Designing and managing data flows to support analytical initiatives is the core responsibility of a data engineer. The main challenge is creating a flow that merges data from multiple sources into a datawarehouse or shared location. Both stream and batch real-time processing are supported.
Summary Data lineage is the roadmap for your data platform, providing visibility into all of the dependencies for any report, machine learning model, or datawarehouse table that you are working with. What is involved in integrating Manta with an organization’s data systems?
Data engineering courses also teach data engineers how to leverage cloud resources for scalable data solutions while optimizing costs. Suppose a cloud data engineer completes a course that covers Google Cloud BigQuery and its cost-effective pricing model.
Roles and Responsibilities Finding data sources and automating the data collection process Discovering patterns and trends by analyzing information Performing data pre-processing on both structured and unstructureddata Creating predictive models and machine-learning algorithms Average Salary: USD 81,361 (1-3 years) / INR 10,00,000 per annum 3.
FAQs on the Data Science Pipeline What is a Data Science Pipeline? A data science pipeline is a structured process that involves gathering raw and unstructureddata from multiple sources, processing it through transformations like filtering and aggregating, and storing it in a datawarehouse for analysis.
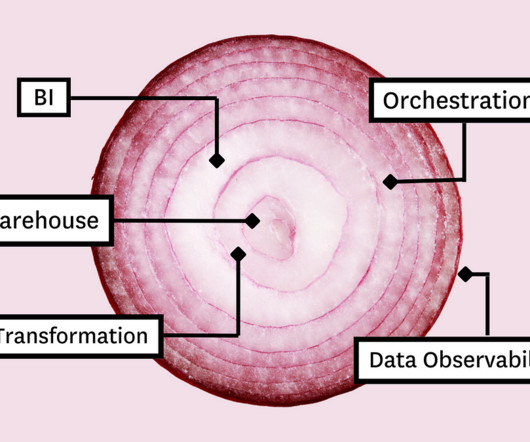
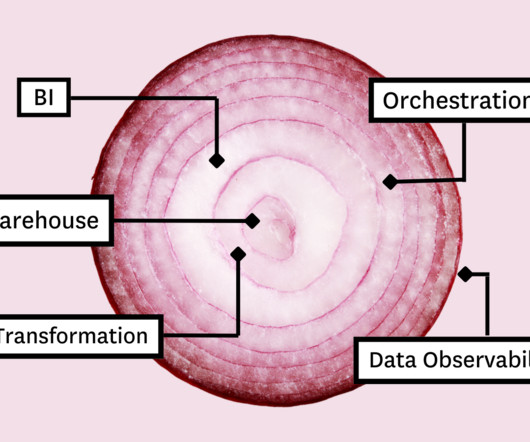
In this article, we’ll present you with the Five Layer Data Stack — a model for platform development consisting of five critical tools that will not only allow you to maximize impact but empower you to grow with the needs of your organization. Before you can model the data for your stakeholders, you need a place to collect and store it.
In this article, we’ll present you with the Five Layer Data Stack—a model for platform development consisting of five critical tools that will not only allow you to maximize impact but empower you to grow with the needs of your organization. Before you can model the data for your stakeholders, you need a place to collect and store it.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content